 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm to Compilation Co-design: An Integrated View of Neural Network Sparsity
Paper and Code
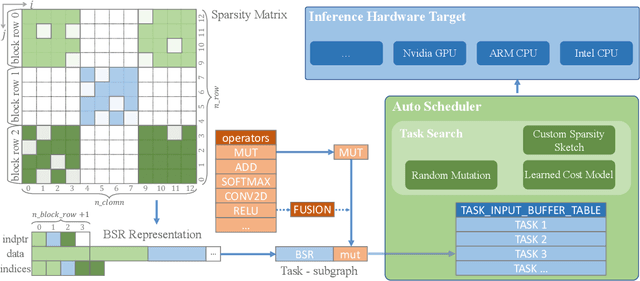
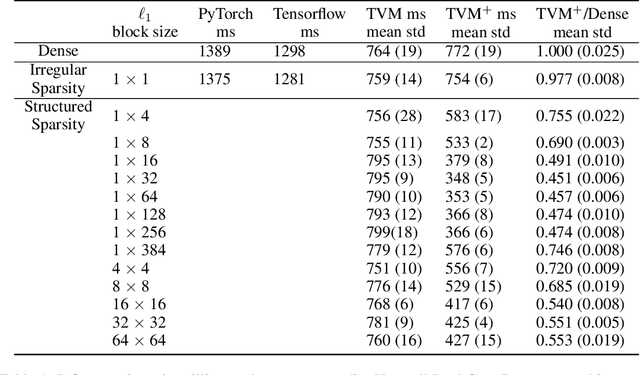
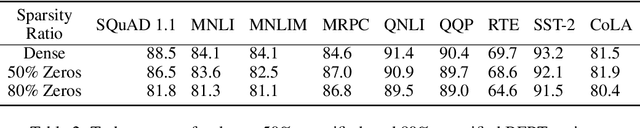
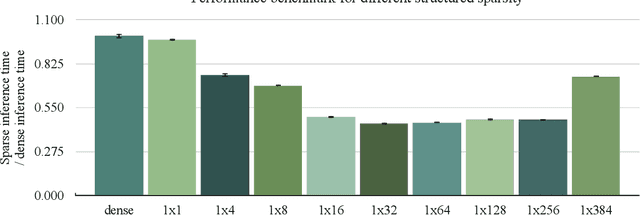
Reducing computation cost, inference latency, and memory footprint of neural networks are frequently cited as research motivations for pruning and sparsity. However, operationalizing those benefits and understanding the end-to-end effect of algorithm design and regularization on the runtime execution is not often examined in depth. Here we apply structured and unstructured pruning to attention weights of transformer blocks of the BERT language model, while also expanding block sparse representation (BSR) operations in the TVM compiler. Integration of BSR operations enables the TVM runtime execution to leverage structured pattern sparsity induced by model regularization. This integrated view of pruning algorithms enables us to study relationships between modeling decisions and their direct impact on sparsity-enhanced execution. Our main findings are: 1) we validate that performance benefits of structured sparsity block regularization must be enabled by the BSR augmentations to TVM, with 4x speedup relative to vanilla PyTorch and 2.2x speedup relative to standard TVM compilation (without expanded BSR support). 2) for BERT attention weights, the end-to-end optimal block sparsity shape in this CPU inference context is not a square block (as in \cite{gray2017gpu}) but rather a linear 32x1 block 3) the relationship between performance and block size / shape is is suggestive of how model regularization parameters interact with task scheduler optimizations resulting in the observed end-to-end performance.