 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Novelty-Driven Neural Architecture Search
Paper and Code
Jul 22, 2019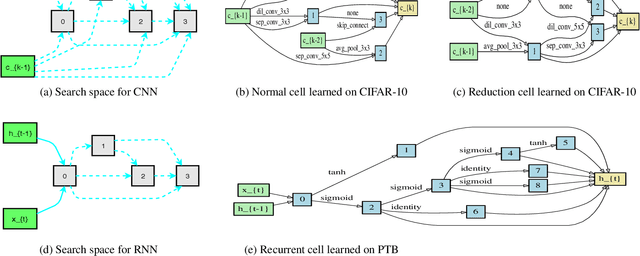
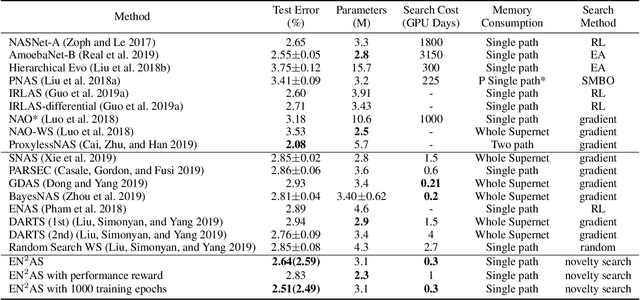


One-Shot Neural architecture search (NAS) attracts broad attention recently due to its capacity to reduce the computational hours through weight sharing. However, extensive experiments on several recent works show that there is no positive correlation between the validation accuracy with inherited weights from the supernet and the test accuracy after re-training for One-Shot NAS. Different from devising a controller to find the best performing architecture with inherited weights, this paper focuses on how to sample architectures to train the supernet to make it more predictive. A single-path supernet is adopted, where only a small part of weights are optimized in each step, to reduce the memory demand greatly. Furthermore, we abandon devising complicated reward based architecture sampling controller, and sample architectures to train supernet based on novelty search. An efficient novelty search method for NAS is devised in this paper, and extensive experiments demonstrate the effectiveness and efficiency of our novelty search based architecture sampling method. The best architecture obtained by our algorithm with the same search space achieves the state-of-the-art test error rate of 2.51\% on CIFAR-10 with only 7.5 hours search time in a single GPU, and a validation perplexity of 60.02 and a test perplexity of 57.36 on PTB. We also transfer these search cell structures to larger datasets ImageNet and WikiText-2, respectively.