 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Architecture Search Without Training Nor Labels: A Pruning Perspective
Paper and Code
Jun 22, 2021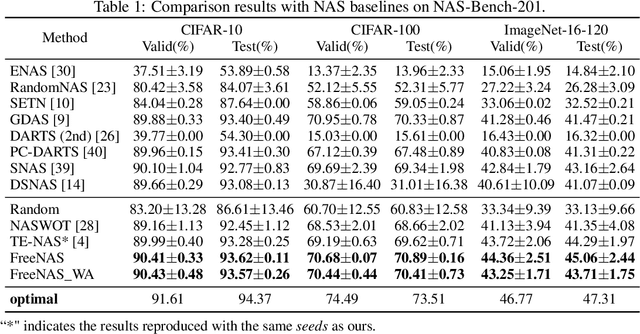
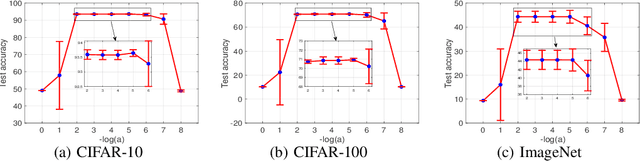
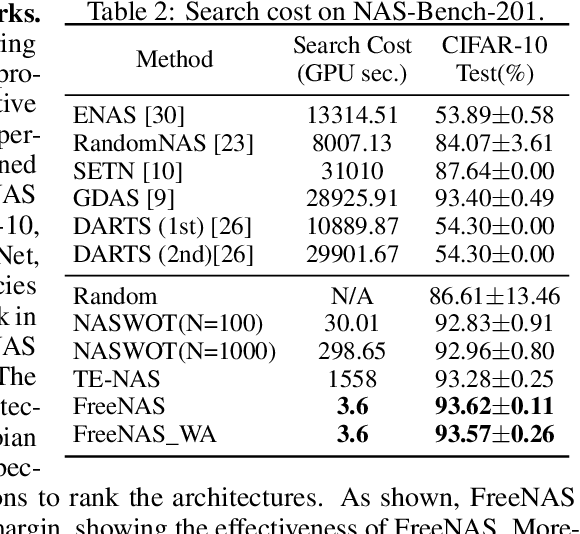
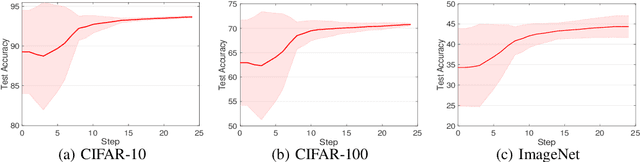
With leveraging the weight-sharing and continuous relaxation to enable gradient-descent to alternately optimize the supernet weights and the architecture parameters through a bi-level optimization paradigm, \textit{Differentiable ARchiTecture Search} (DARTS) has become the mainstream method in Neural Architecture Search (NAS) due to its simplicity and efficiency. However, more recent works found that the performance of the searched architecture barely increases with the optimization proceeding in DARTS. In addition, several concurrent works show that the NAS could find more competitive architectures without labels. The above observations reveal that the supervision signal in DARTS may be a poor indicator for architecture optimization, inspiring a foundational question: instead of using the supervision signal to perform bi-level optimization, \textit{can we find high-quality architectures \textbf{without any training nor labels}}? We provide an affirmative answer by customizing the NAS as a network pruning at initialization problem. By leveraging recent techniques on the network pruning at initialization, we designed a FreeFlow proxy to score the importance of candidate operations in NAS without any training nor labels, and proposed a novel framework called \textit{training and label free neural architecture search} (\textbf{FreeNAS}) accordingly. We show that, without any training nor labels, FreeNAS with the proposed FreeFlow proxy can outperform most NAS baselines. More importantly, our framework is extremely efficient, which completes the architecture search within only \textbf{3.6s} and \textbf{79s} on a single GPU for the NAS-Bench-201 and DARTS search space, respectively. We hope our work inspires more attempts in solving NAS from the perspective of pruning at initialization.