 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based User Personas for Recommendations at Scale
Jun 10, 2026Large Language Models (LLMs) offer unprecedented potential for enhancing recommendation systems through their world knowledge and reasoning capabilities. However, existing approaches often rely on structured IDs or offline processing, limiting semantic richness, real-time adaptability, and user-facing interpretability. In this paper, we introduce a novel framework that enables real-time generation of LLM-based user interest personas for a large-scale commercial video recommendation platform. Our method generates natural-language user interest personas that address the exploitation-exploration trade-off by combining the summarization of existing interests with novel topics, directly during serving. To overcome the computational challenges of online LLM inference at a billion-user scale, we design a cost-efficient architecture leveraging knowledge distillation, asynchronous inference, and input optimization via semantically clustered video representations. Extensive offline evaluations, user studies, and live A/B tests demonstrate significant improvements in viewer value. This work bridges the gap between high-level semantic understanding and industrial-scale recommendation, paving the way for more dynamic, explainable, and satisfying personalized experiences.
Serendipitous Recommendation with Multimodal LLM
Jun 09, 2025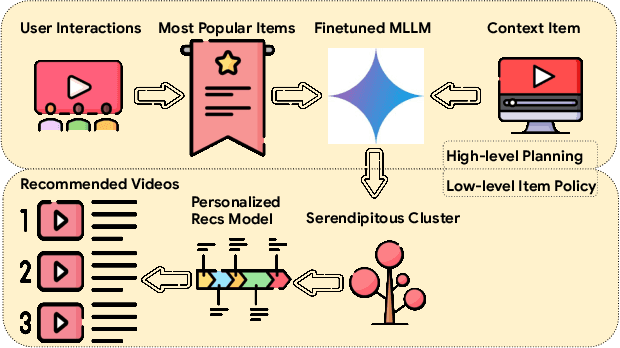
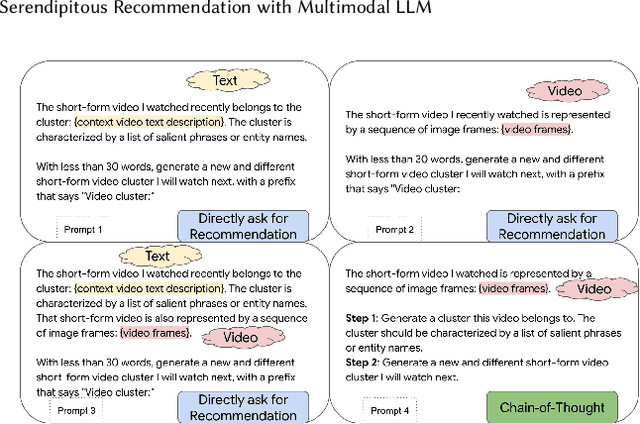
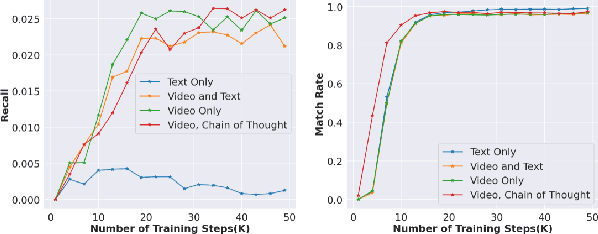
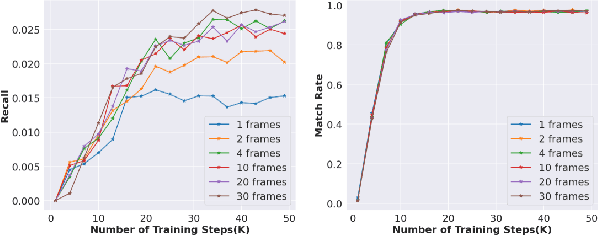
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
User Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
LLMs for User Interest Exploration: A Hybrid Approach
May 25, 2024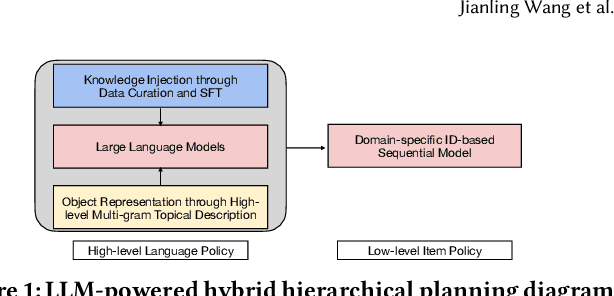

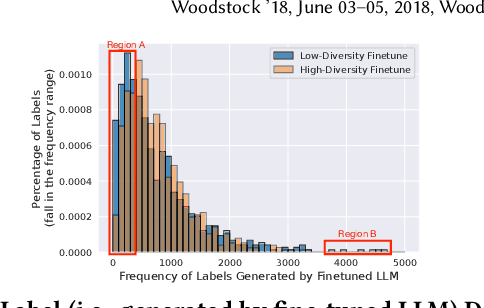
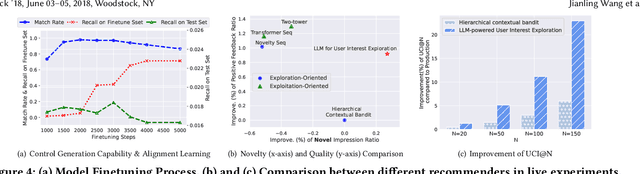
Traditional recommendation systems are subject to a strong feedback loop by learning from and reinforcing past user-item interactions, which in turn limits the discovery of novel user interests. To address this, we introduce a hybrid hierarchical framework combining Large Language Models (LLMs) and classic recommendation models for user interest exploration. The framework controls the interfacing between the LLMs and the classic recommendation models through "interest clusters", the granularity of which can be explicitly determined by algorithm designers. It recommends the next novel interests by first representing "interest clusters" using language, and employs a fine-tuned LLM to generate novel interest descriptions that are strictly within these predefined clusters. At the low level, it grounds these generated interests to an item-level policy by restricting classic recommendation models, in this case a transformer-based sequence recommender to return items that fall within the novel clusters generated at the high level. We showcase the efficacy of this approach on an industrial-scale commercial platform serving billions of users. Live experiments show a significant increase in both exploration of novel interests and overall user enjoyment of the platform.
Large Language Models as Data Augmenters for Cold-Start Item Recommendation
Feb 18, 2024


The reasoning and generalization capabilities of LLMs can help us better understand user preferences and item characteristics, offering exciting prospects to enhance recommendation systems. Though effective while user-item interactions are abundant, conventional recommendation systems struggle to recommend cold-start items without historical interactions. To address this, we propose utilizing LLMs as data augmenters to bridge the knowledge gap on cold-start items during training. We employ LLMs to infer user preferences for cold-start items based on textual description of user historical behaviors and new item descriptions. The augmented training signals are then incorporated into learning the downstream recommendation models through an auxiliary pairwise loss. Through experiments on public Amazon datasets, we demonstrate that LLMs can effectively augment the training signals for cold-start items, leading to significant improvements in cold-start item recommendation for various recommendation models.
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023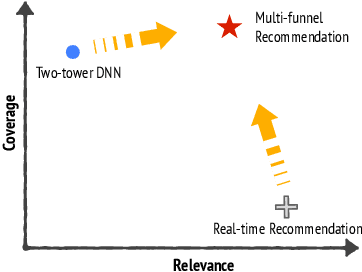
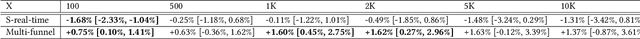
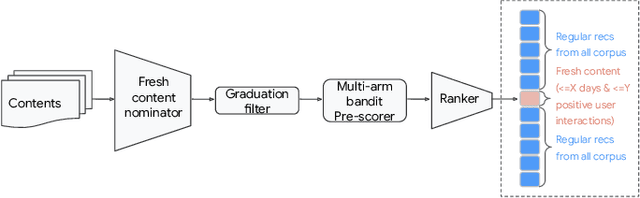

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Value of Exploration: Measurements, Findings and Algorithms
May 12, 2023



Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.