 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023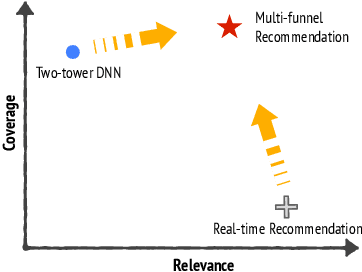
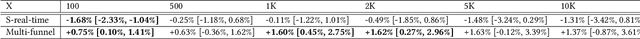
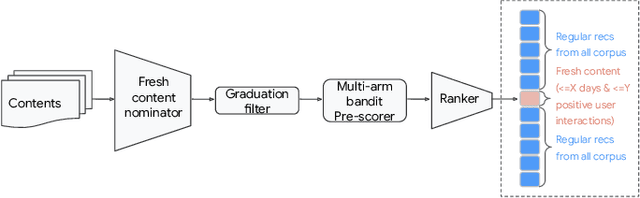

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Value of Exploration: Measurements, Findings and Algorithms
May 12, 2023



Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.
Fairness in Recommendation Ranking through Pairwise Comparisons
Mar 02, 2019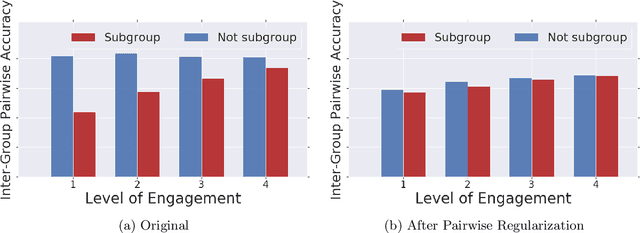

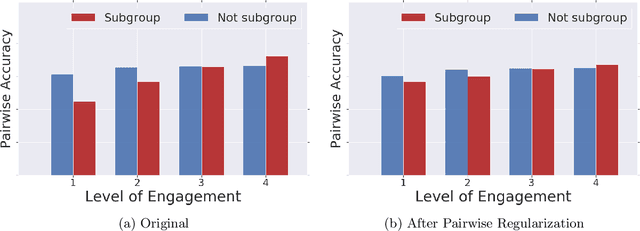
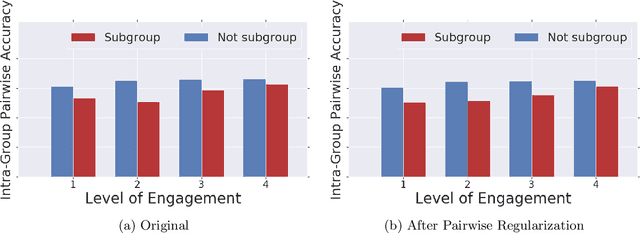
Recommender systems are one of the most pervasive applications of machine learning in industry, with many services using them to match users to products or information. As such it is important to ask: what are the possible fairness risks, how can we quantify them, and how should we address them? In this paper we offer a set of novel metrics for evaluating algorithmic fairness concerns in recommender systems. In particular we show how measuring fairness based on pairwise comparisons from randomized experiments provides a tractable means to reason about fairness in rankings from recommender systems. Building on this metric, we offer a new regularizer to encourage improving this metric during model training and thus improve fairness in the resulting rankings. We apply this pairwise regularization to a large-scale, production recommender system and show that we are able to significantly improve the system's pairwise fairness.