 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Learning-to-Rank with Generalized Additive Models
May 14, 2020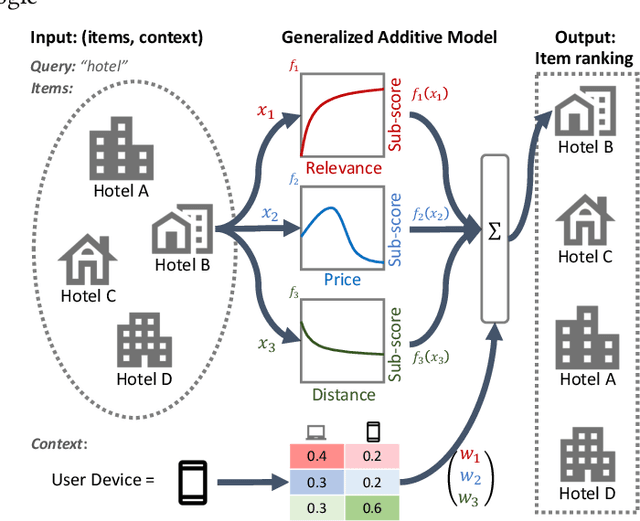

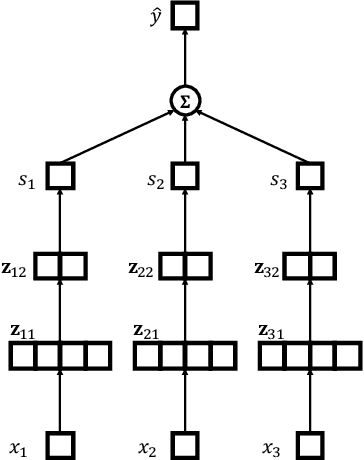
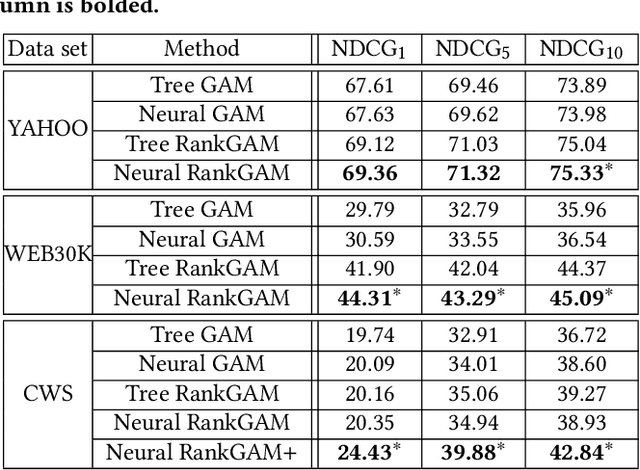
Interpretability of learning-to-rank models is a crucial yet relatively under-examined research area. Recent progress on interpretable ranking models largely focuses on generating post-hoc explanations for existing black-box ranking models, whereas the alternative option of building an intrinsically interpretable ranking model with transparent and self-explainable structure remains unexplored. Developing fully-understandable ranking models is necessary in some scenarios (e.g., due to legal or policy constraints) where post-hoc methods cannot provide sufficiently accurate explanations. In this paper, we lay the groundwork for intrinsically interpretable learning-to-rank by introducing generalized additive models (GAMs) into ranking tasks. Generalized additive models (GAMs) are intrinsically interpretable machine learning models and have been extensively studied on regression and classification tasks. We study how to extend GAMs into ranking models which can handle both item-level and list-level features and propose a novel formulation of ranking GAMs. To instantiate ranking GAMs, we employ neural networks instead of traditional splines or regression trees. We also show that our neural ranking GAMs can be distilled into a set of simple and compact piece-wise linear functions that are much more efficient to evaluate with little accuracy loss. We conduct experiments on three data sets and show that our proposed neural ranking GAMs can achieve significantly better performance than other traditional GAM baselines while maintaining similar interpretability.
Toward a better trade-off between performance and fairness with kernel-based distribution matching
Oct 25, 2019
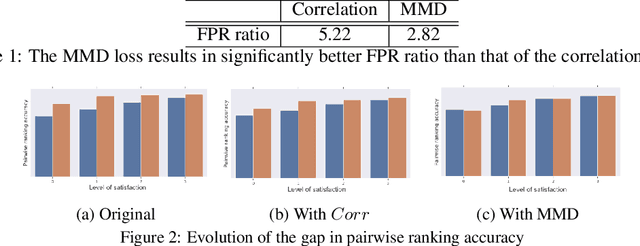

As recent literature has demonstrated how classifiers often carry unintended biases toward some subgroups, deploying machine learned models to users demands careful consideration of the social consequences. How should we address this problem in a real-world system? How should we balance core performance and fairness metrics? In this paper, we introduce a MinDiff framework for regularizing classifiers toward different fairness metrics and analyze a technique with kernel-based statistical dependency tests. We run a thorough study on an academic dataset to compare the Pareto frontier achieved by different regularization approaches, and apply our kernel-based method to two large-scale industrial systems demonstrating real-world improvements.
Transfer of Machine Learning Fairness across Domains
Jun 26, 2019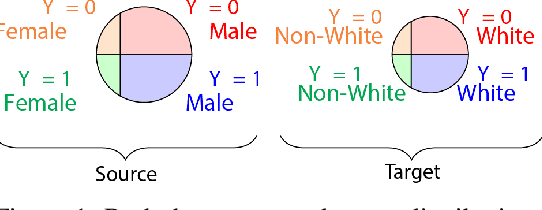

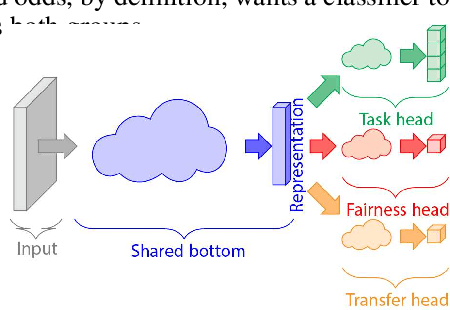
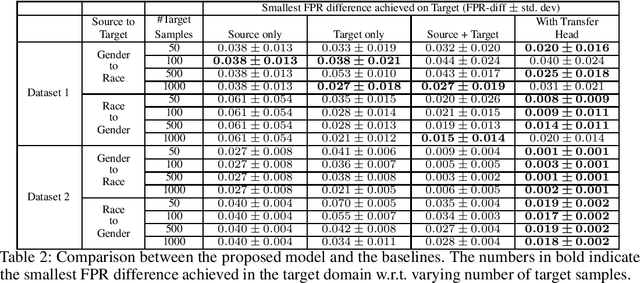
If our models are used in new or unexpected cases, do we know if they will make fair predictions? Previously, researchers developed ways to debias a model for a single problem domain. However, this is often not how models are trained and used in practice. For example, labels and demographics (sensitive attributes) are often hard to observe, resulting in auxiliary or synthetic data to be used for training, and proxies of the sensitive attribute to be used for evaluation of fairness. A model trained for one setting may be picked up and used in many others, particularly as is common with pre-training and cloud APIs. Despite the pervasiveness of these complexities, remarkably little work in the fairness literature has theoretically examined these issues. We frame all of these settings as domain adaptation problems: how can we use what we have learned in a source domain to debias in a new target domain, without directly debiasing on the target domain as if it is a completely new problem? We offer new theoretical guarantees of improving fairness across domains, and offer a modeling approach to transfer to data-sparse target domains. We give empirical results validating the theory and showing that these modeling approaches can improve fairness metrics with less data.
Fairness in Recommendation Ranking through Pairwise Comparisons
Mar 02, 2019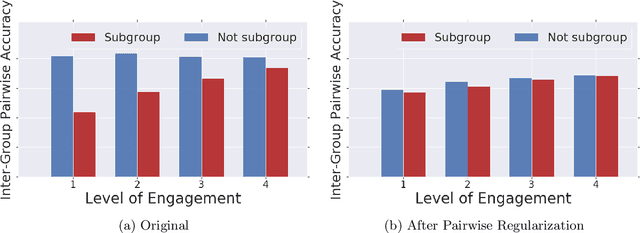

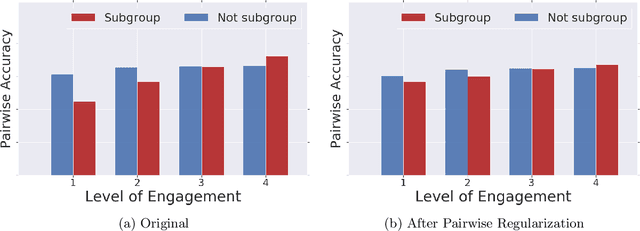
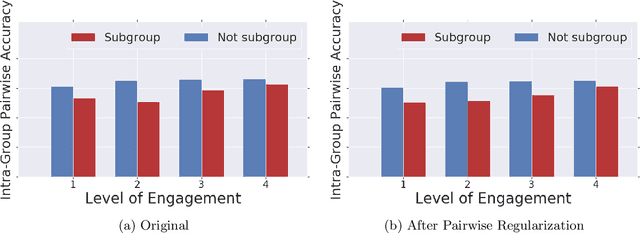
Recommender systems are one of the most pervasive applications of machine learning in industry, with many services using them to match users to products or information. As such it is important to ask: what are the possible fairness risks, how can we quantify them, and how should we address them? In this paper we offer a set of novel metrics for evaluating algorithmic fairness concerns in recommender systems. In particular we show how measuring fairness based on pairwise comparisons from randomized experiments provides a tractable means to reason about fairness in rankings from recommender systems. Building on this metric, we offer a new regularizer to encourage improving this metric during model training and thus improve fairness in the resulting rankings. We apply this pairwise regularization to a large-scale, production recommender system and show that we are able to significantly improve the system's pairwise fairness.
Putting Fairness Principles into Practice: Challenges, Metrics, and Improvements
Jan 14, 2019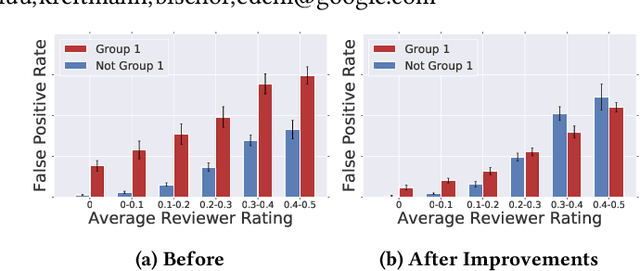
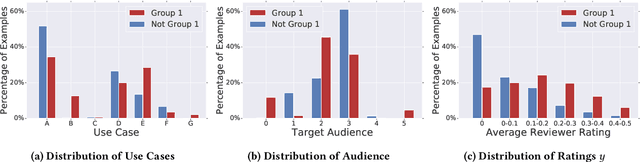

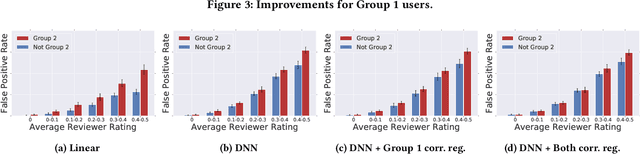
As more researchers have become aware of and passionate about algorithmic fairness, there has been an explosion in papers laying out new metrics, suggesting algorithms to address issues, and calling attention to issues in existing applications of machine learning. This research has greatly expanded our understanding of the concerns and challenges in deploying machine learning, but there has been much less work in seeing how the rubber meets the road. In this paper we provide a case-study on the application of fairness in machine learning research to a production classification system, and offer new insights in how to measure and address algorithmic fairness issues. We discuss open questions in implementing equality of opportunity and describe our fairness metric, conditional equality, that takes into account distributional differences. Further, we provide a new approach to improve on the fairness metric during model training and demonstrate its efficacy in improving performance for a real-world product