 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Interpretable Models into Human-Readable Code
Feb 09, 2021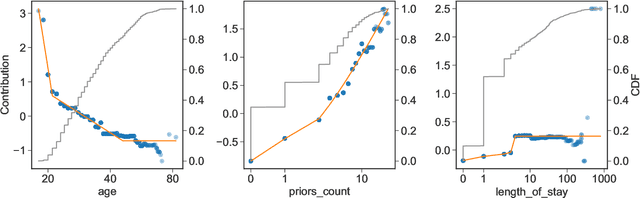
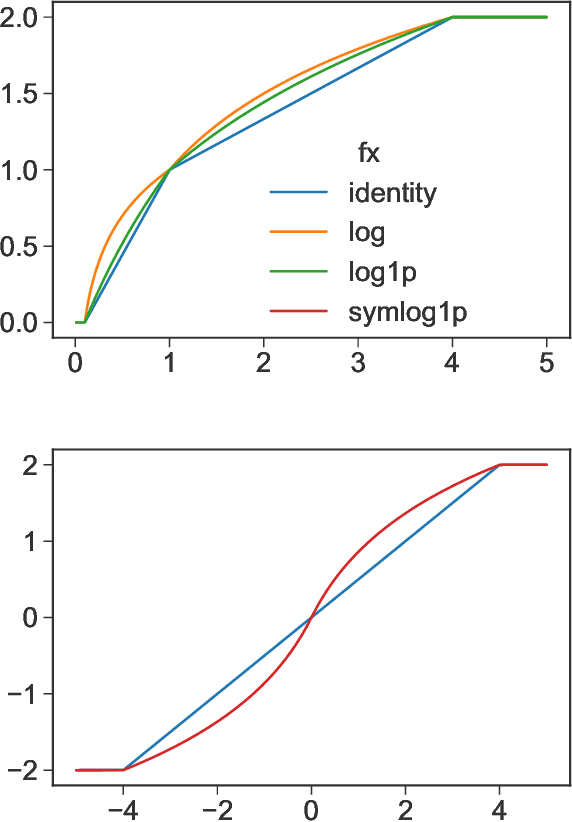
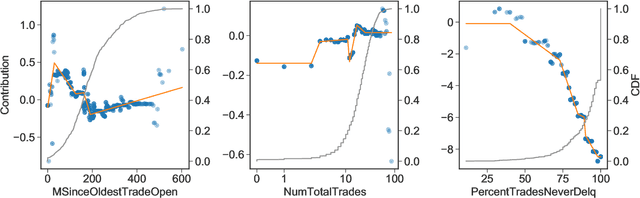
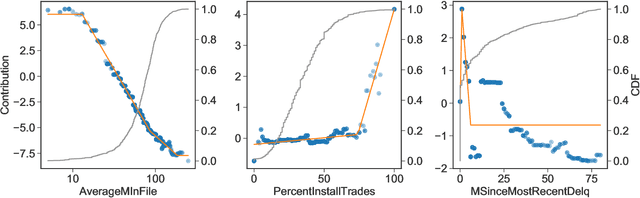
The goal of model distillation is to faithfully transfer teacher model knowledge to a model which is faster, more generalizable, more interpretable, or possesses other desirable characteristics. Human-readability is an important and desirable standard for machine-learned model interpretability. Readable models are transparent and can be reviewed, manipulated, and deployed like traditional source code. As a result, such models can be improved outside the context of machine learning and manually edited if desired. Given that directly training such models is difficult, we propose to train interpretable models using conventional methods, and then distill them into concise, human-readable code. The proposed distillation methodology approximates a model's univariate numerical functions with piecewise-linear curves in a localized manner. The resulting curve model representations are accurate, concise, human-readable, and well-regularized by construction. We describe a piecewise-linear curve-fitting algorithm that produces high-quality results efficiently and reliably across a broad range of use cases. We demonstrate the effectiveness of the overall distillation technique and our curve-fitting algorithm using four datasets across the tasks of classification, regression, and ranking.
Interpretable Learning-to-Rank with Generalized Additive Models
May 14, 2020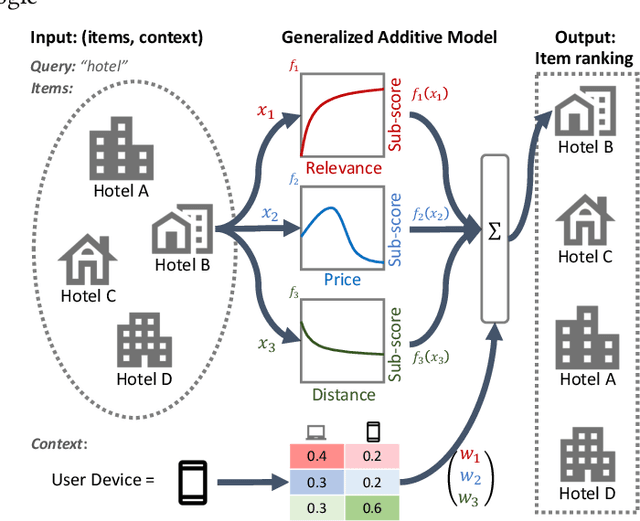

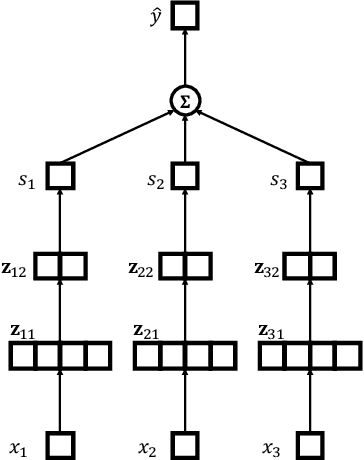
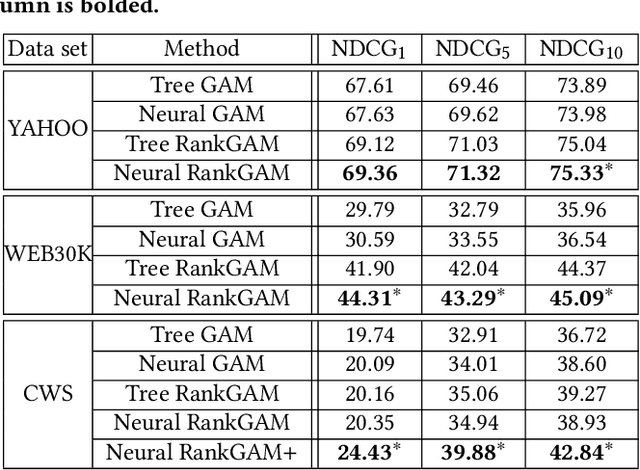
Interpretability of learning-to-rank models is a crucial yet relatively under-examined research area. Recent progress on interpretable ranking models largely focuses on generating post-hoc explanations for existing black-box ranking models, whereas the alternative option of building an intrinsically interpretable ranking model with transparent and self-explainable structure remains unexplored. Developing fully-understandable ranking models is necessary in some scenarios (e.g., due to legal or policy constraints) where post-hoc methods cannot provide sufficiently accurate explanations. In this paper, we lay the groundwork for intrinsically interpretable learning-to-rank by introducing generalized additive models (GAMs) into ranking tasks. Generalized additive models (GAMs) are intrinsically interpretable machine learning models and have been extensively studied on regression and classification tasks. We study how to extend GAMs into ranking models which can handle both item-level and list-level features and propose a novel formulation of ranking GAMs. To instantiate ranking GAMs, we employ neural networks instead of traditional splines or regression trees. We also show that our neural ranking GAMs can be distilled into a set of simple and compact piece-wise linear functions that are much more efficient to evaluate with little accuracy loss. We conduct experiments on three data sets and show that our proposed neural ranking GAMs can achieve significantly better performance than other traditional GAM baselines while maintaining similar interpretability.
TF Boosted Trees: A scalable TensorFlow based framework for gradient boosting
Oct 31, 2017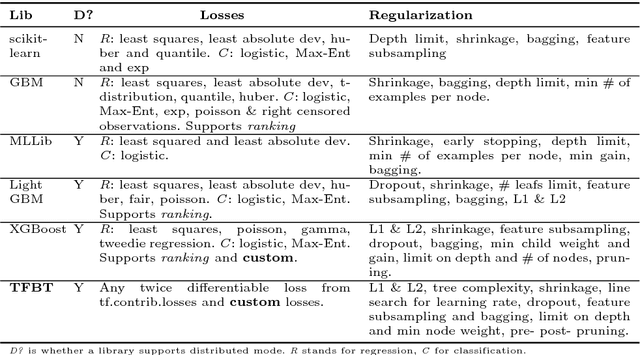
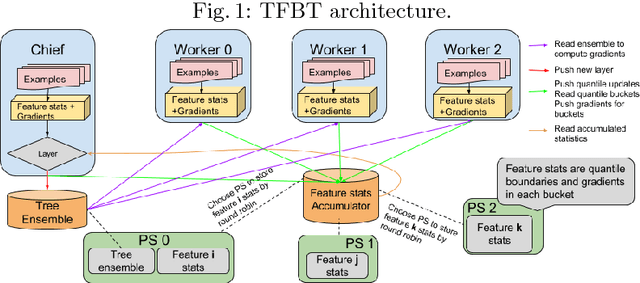
TF Boosted Trees (TFBT) is a new open-sourced frame-work for the distributed training of gradient boosted trees. It is based on TensorFlow, and its distinguishing features include a novel architecture, automatic loss differentiation, layer-by-layer boosting that results in smaller ensembles and faster prediction, principled multi-class handling, and a number of regularization techniques to prevent overfitting.