 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
TF Boosted Trees: A scalable TensorFlow based framework for gradient boosting
Oct 31, 2017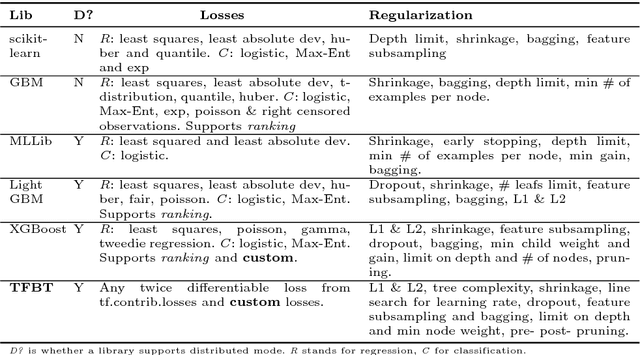
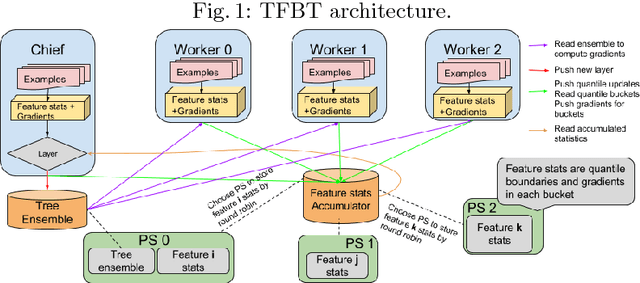
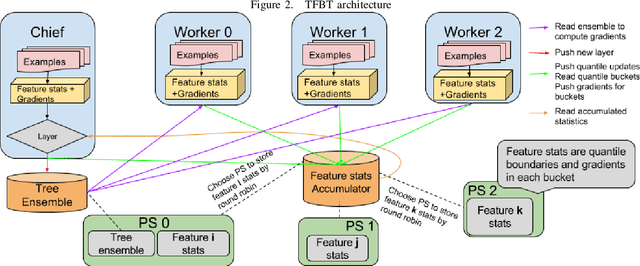
TF Boosted Trees (TFBT) is a new open-sourced frame-work for the distributed training of gradient boosted trees. It is based on TensorFlow, and its distinguishing features include a novel architecture, automatic loss differentiation, layer-by-layer boosting that results in smaller ensembles and faster prediction, principled multi-class handling, and a number of regularization techniques to prevent overfitting.
Compact Multi-Class Boosted Trees
Oct 31, 2017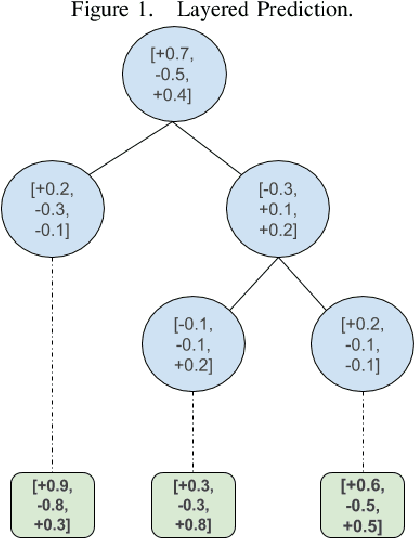
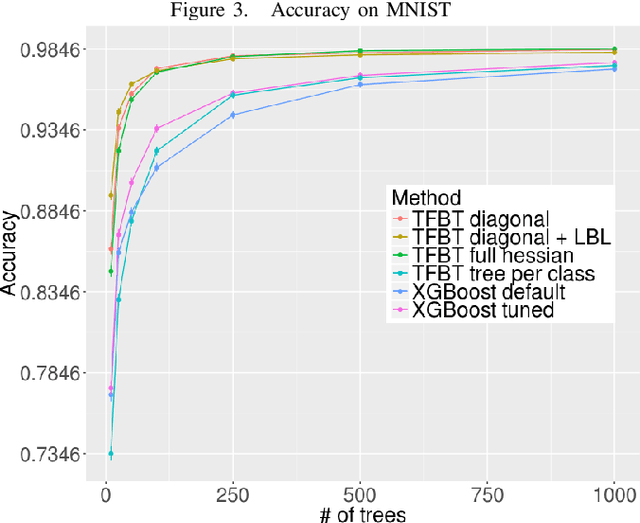
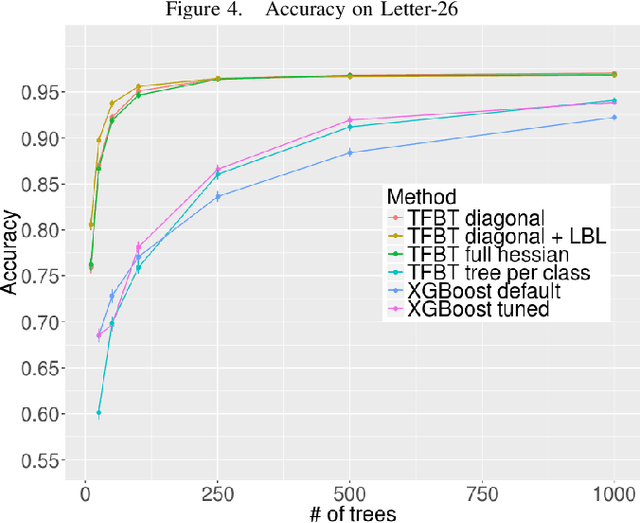
Gradient boosted decision trees are a popular machine learning technique, in part because of their ability to give good accuracy with small models. We describe two extensions to the standard tree boosting algorithm designed to increase this advantage. The first improvement extends the boosting formalism from scalar-valued trees to vector-valued trees. This allows individual trees to be used as multiclass classifiers, rather than requiring one tree per class, and drastically reduces the model size required for multiclass problems. We also show that some other popular vector-valued gradient boosted trees modifications fit into this formulation and can be easily obtained in our implementation. The second extension, layer-by-layer boosting, takes smaller steps in function space, which is empirically shown to lead to a faster convergence and to a more compact ensemble. We have added both improvements to the open-source TensorFlow Boosted trees (TFBT) package, and we demonstrate their efficacy on a variety of multiclass datasets. We expect these extensions will be of particular interest to boosted tree applications that require small models, such as embedded devices, applications requiring fast inference, or applications desiring more interpretable models.