 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfAlign: Inference-aware language model alignment
Dec 27, 2024Language model alignment has become a critical step in training modern generative language models. The goal of alignment is to finetune a reference model such that the win rate of a sample from the aligned model over a sample from the reference model is high, subject to a KL divergence constraint. Today, we are increasingly using inference-time algorithms (e.g., Best-of-N, controlled decoding, tree search) to decode from language models rather than standard sampling. However, the alignment objective does not capture such inference-time decoding procedures. We show that the existing alignment framework is sub-optimal in view of such inference-time methods. We then modify the alignment objective and propose a framework for inference-aware alignment (IAPO). We prove that for any inference-time decoding algorithm, the optimal solution that optimizes the inference-time win rate of the aligned policy against the reference policy is the solution to the typical RLHF problem with a transformation of the reward. This motivates us to provide the KL-regularized calibrate-and-transform RL (CTRL) algorithm to solve this problem, which involves a reward calibration step and a KL-regularized reward maximization step with a transformation of the calibrated reward. We particularize our study to two important inference-time strategies: best-of-N sampling and best-of-N jailbreaking, where N responses are sampled from the model and the one with the highest or lowest reward is selected. We propose specific transformations for these strategies and demonstrate that our framework offers significant improvements over existing state-of-the-art methods for language model alignment. Empirically, we outperform baselines that are designed without taking inference-time decoding into consideration by 8-12% and 4-9% on inference-time win rates over the Anthropic helpfulness and harmlessness dialog benchmark datasets.
Inducing Group Fairness in LLM-Based Decisions
Jun 24, 2024



Prompting Large Language Models (LLMs) has created new and interesting means for classifying textual data. While evaluating and remediating group fairness is a well-studied problem in classifier fairness literature, some classical approaches (e.g., regularization) do not carry over, and some new opportunities arise (e.g., prompt-based remediation). We measure fairness of LLM-based classifiers on a toxicity classification task, and empirically show that prompt-based classifiers may lead to unfair decisions. We introduce several remediation techniques and benchmark their fairness and performance trade-offs. We hope our work encourages more research on group fairness in LLM-based classifiers.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
FRAPPÉ: A Post-Processing Framework for Group Fairness Regularization
Dec 05, 2023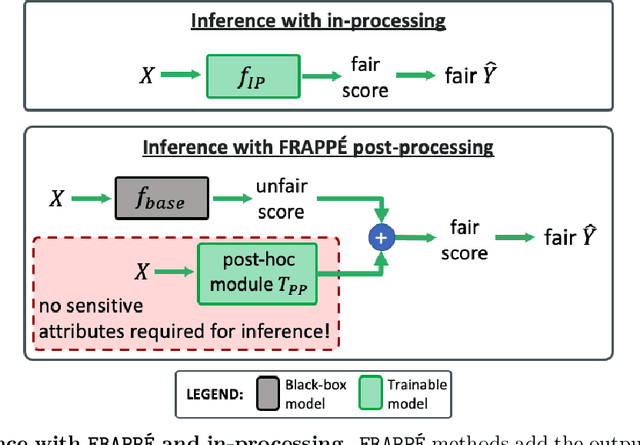
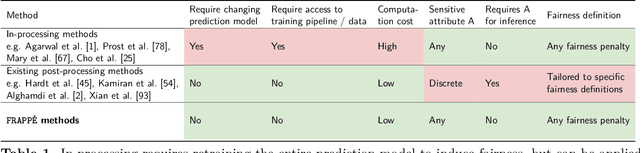
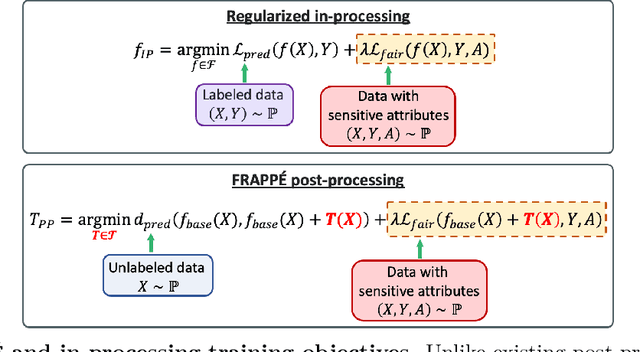
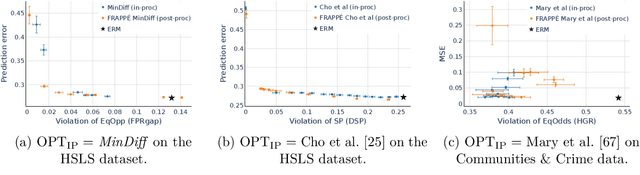
Post-processing mitigation techniques for group fairness generally adjust the decision threshold of a base model in order to improve fairness. Methods in this family exhibit several advantages that make them appealing in practice: post-processing requires no access to the model training pipeline, is agnostic to the base model architecture, and offers a reduced computation cost compared to in-processing. Despite these benefits, existing methods face other challenges that limit their applicability: they require knowledge of the sensitive attributes at inference time and are oftentimes outperformed by in-processing. In this paper, we propose a general framework to transform any in-processing method with a penalized objective into a post-processing procedure. The resulting method is specifically designed to overcome the aforementioned shortcomings of prior post-processing approaches. Furthermore, we show theoretically and through extensive experiments on real-world data that the resulting post-processing method matches or even surpasses the fairness-error trade-off offered by the in-processing counterpart.
Towards A Scalable Solution for Improving Multi-Group Fairness in Compositional Classification
Jul 11, 2023Despite the rich literature on machine learning fairness, relatively little attention has been paid to remediating complex systems, where the final prediction is the combination of multiple classifiers and where multiple groups are present. In this paper, we first show that natural baseline approaches for improving equal opportunity fairness scale linearly with the product of the number of remediated groups and the number of remediated prediction labels, rendering them impractical. We then introduce two simple techniques, called {\em task-overconditioning} and {\em group-interleaving}, to achieve a constant scaling in this multi-group multi-label setup. Our experimental results in academic and real-world environments demonstrate the effectiveness of our proposal at mitigation within this environment.
Simpson's Paradox in Recommender Fairness: Reconciling differences between per-user and aggregated evaluations
Oct 14, 2022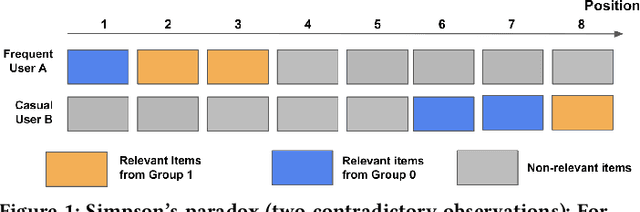
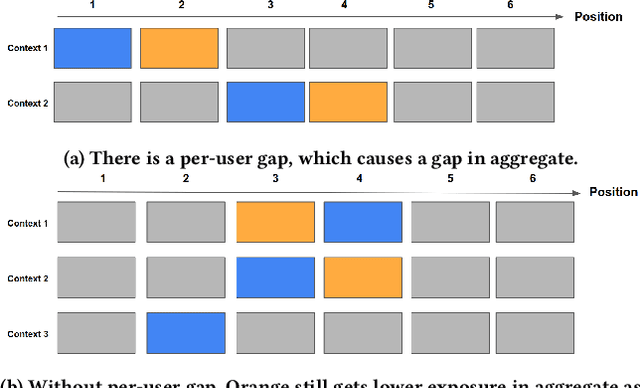
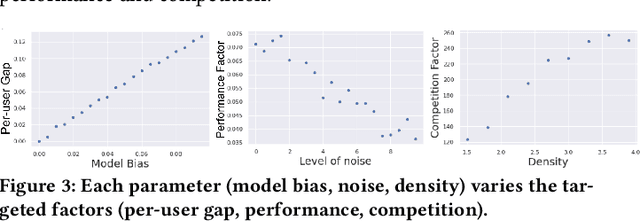
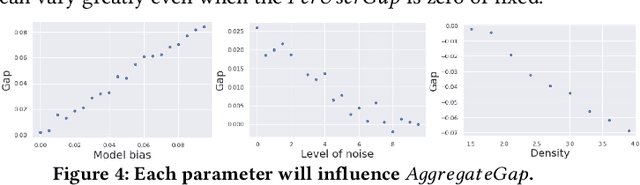
There has been a flurry of research in recent years on notions of fairness in ranking and recommender systems, particularly on how to evaluate if a recommender allocates exposure equally across groups of relevant items (also known as provider fairness). While this research has laid an important foundation, it gave rise to different approaches depending on whether relevant items are compared per-user/per-query or aggregated across users. Despite both being established and intuitive, we discover that these two notions can lead to opposite conclusions, a form of Simpson's Paradox. We reconcile these notions and show that the tension is due to differences in distributions of users where items are relevant, and break down the important factors of the user's recommendations. Based on this new understanding, practitioners might be interested in either notions, but might face challenges with the per-user metric due to partial observability of the relevance and user satisfaction, typical in real-world recommenders. We describe a technique based on distribution matching to estimate it in such a scenario. We demonstrate on simulated and real-world recommender data the effectiveness and usefulness of such an approach.
Understanding and Improving Fairness-Accuracy Trade-offs in Multi-Task Learning
Jun 04, 2021
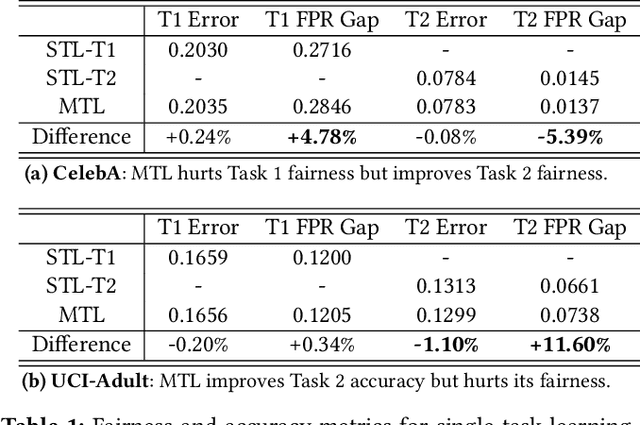
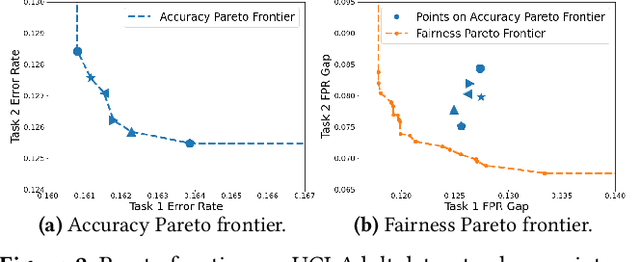
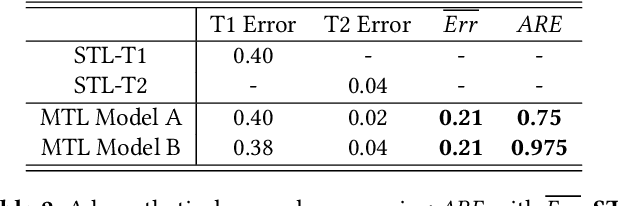
As multi-task models gain popularity in a wider range of machine learning applications, it is becoming increasingly important for practitioners to understand the fairness implications associated with those models. Most existing fairness literature focuses on learning a single task more fairly, while how ML fairness interacts with multiple tasks in the joint learning setting is largely under-explored. In this paper, we are concerned with how group fairness (e.g., equal opportunity, equalized odds) as an ML fairness concept plays out in the multi-task scenario. In multi-task learning, several tasks are learned jointly to exploit task correlations for a more efficient inductive transfer. This presents a multi-dimensional Pareto frontier on (1) the trade-off between group fairness and accuracy with respect to each task, as well as (2) the trade-offs across multiple tasks. We aim to provide a deeper understanding on how group fairness interacts with accuracy in multi-task learning, and we show that traditional approaches that mainly focus on optimizing the Pareto frontier of multi-task accuracy might not perform well on fairness goals. We propose a new set of metrics to better capture the multi-dimensional Pareto frontier of fairness-accuracy trade-offs uniquely presented in a multi-task learning setting. We further propose a Multi-Task-Aware Fairness (MTA-F) approach to improve fairness in multi-task learning. Experiments on several real-world datasets demonstrate the effectiveness of our proposed approach.
Measuring Model Fairness under Noisy Covariates: A Theoretical Perspective
May 20, 2021
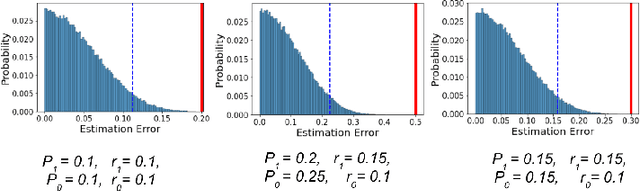
In this work we study the problem of measuring the fairness of a machine learning model under noisy information. Focusing on group fairness metrics, we investigate the particular but common situation when the evaluation requires controlling for the confounding effect of covariate variables. In a practical setting, we might not be able to jointly observe the covariate and group information, and a standard workaround is to then use proxies for one or more of these variables. Prior works have demonstrated the challenges with using a proxy for sensitive attributes, and strong independence assumptions are needed to provide guarantees on the accuracy of the noisy estimates. In contrast, in this work we study using a proxy for the covariate variable and present a theoretical analysis that aims to characterize weaker conditions under which accurate fairness evaluation is possible. Furthermore, our theory identifies potential sources of errors and decouples them into two interpretable parts $\gamma$ and $\epsilon$. The first part $\gamma$ depends solely on the performance of the proxy such as precision and recall, whereas the second part $\epsilon$ captures correlations between all the variables of interest. We show that in many scenarios the error in the estimates is dominated by $\gamma$ via a linear dependence, whereas the dependence on the correlations $\epsilon$ only constitutes a lower order term. As a result we expand the understanding of scenarios where measuring model fairness via proxies can be an effective approach. Finally, we compare, via simulations, the theoretical upper-bounds to the distribution of simulated estimation errors and show that assuming some structure on the data, even weak, is key to significantly improve both theoretical guarantees and empirical results.
Measuring Recommender System Effects with Simulated Users
Jan 12, 2021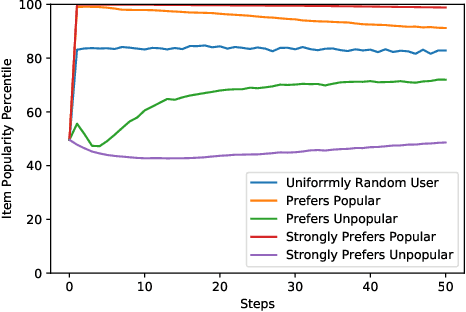

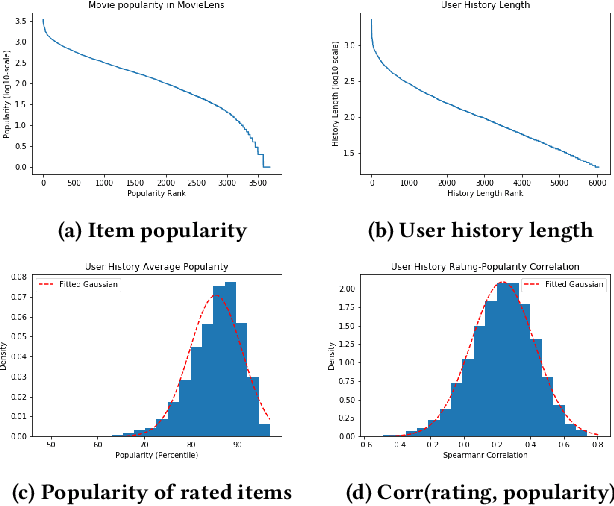
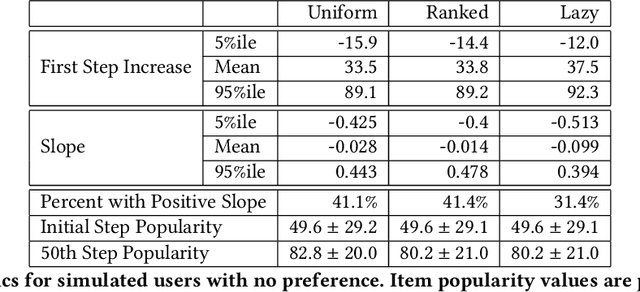
Imagine a food recommender system -- how would we check if it is \emph{causing} and fostering unhealthy eating habits or merely reflecting users' interests? How much of a user's experience over time with a recommender is caused by the recommender system's choices and biases, and how much is based on the user's preferences and biases? Popularity bias and filter bubbles are two of the most well-studied recommender system biases, but most of the prior research has focused on understanding the system behavior in a single recommendation step. How do these biases interplay with user behavior, and what types of user experiences are created from repeated interactions? In this work, we offer a simulation framework for measuring the impact of a recommender system under different types of user behavior. Using this simulation framework, we can (a) isolate the effect of the recommender system from the user preferences, and (b) examine how the system performs not just on average for an "average user" but also the extreme experiences under atypical user behavior. As part of the simulation framework, we propose a set of evaluation metrics over the simulations to understand the recommender system's behavior. Finally, we present two empirical case studies -- one on traditional collaborative filtering in MovieLens and one on a large-scale production recommender system -- to understand how popularity bias manifests over time.
Fairness without Demographics through Adversarially Reweighted Learning
Jun 24, 2020
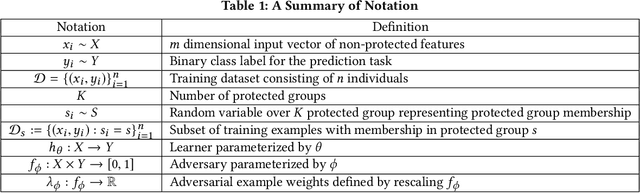
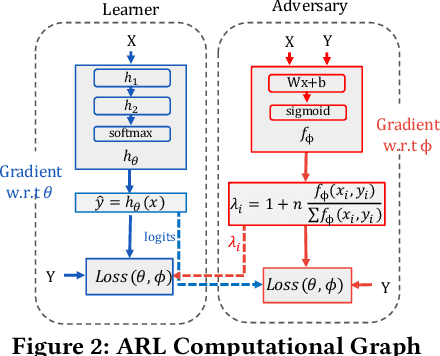
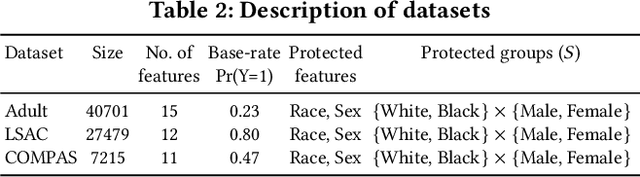
Much of the previous machine learning (ML) fairness literature assumes that protected features such as race and sex are present in the dataset, and relies upon them to mitigate fairness concerns. However, in practice factors like privacy and regulation often preclude the collection of protected features, or their use for training or inference, severely limiting the applicability of traditional fairness research. Therefore we ask: How can we train a ML model to improve fairness when we do not even know the protected group memberships? In this work we address this problem by proposing Adversarially Reweighted Learning (ARL). In particular, we hypothesize that non-protected features and task labels are valuable for identifying fairness issues, and can be used to co-train an adversarial reweighting approach for improving fairness. Our results show that ARL improves Rawlsian Max-Min fairness, with significant AUC improvements for worst-case protected groups in multiple datasets,outperforming state-of-the-art alternatives.