 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Pareto manifolds in high dimensions: How can regularization help?
Mar 11, 2025Simultaneously addressing multiple objectives is becoming increasingly important in modern machine learning. At the same time, data is often high-dimensional and costly to label. For a single objective such as prediction risk, conventional regularization techniques are known to improve generalization when the data exhibits low-dimensional structure like sparsity. However, it is largely unexplored how to leverage this structure in the context of multi-objective learning (MOL) with multiple competing objectives. In this work, we discuss how the application of vanilla regularization approaches can fail, and propose a two-stage MOL framework that can successfully leverage low-dimensional structure. We demonstrate its effectiveness experimentally for multi-distribution learning and fairness-risk trade-offs.
FRAPPÉ: A Post-Processing Framework for Group Fairness Regularization
Dec 05, 2023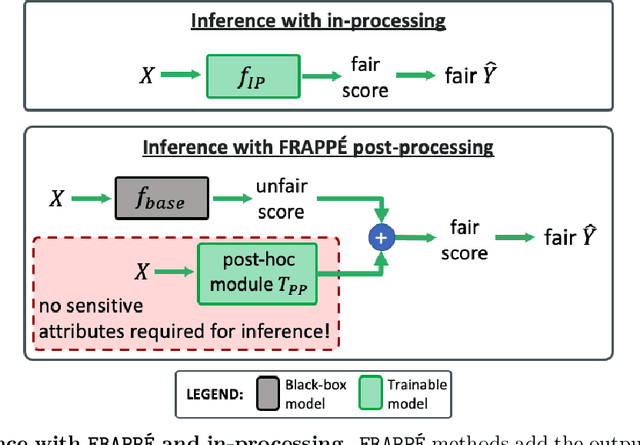
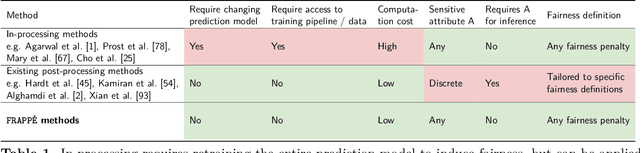
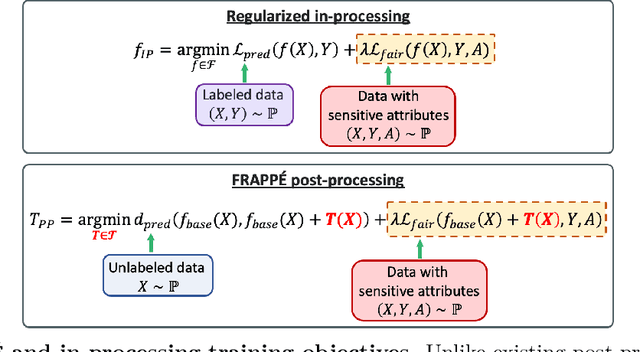
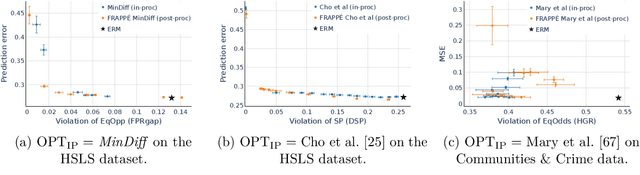
Post-processing mitigation techniques for group fairness generally adjust the decision threshold of a base model in order to improve fairness. Methods in this family exhibit several advantages that make them appealing in practice: post-processing requires no access to the model training pipeline, is agnostic to the base model architecture, and offers a reduced computation cost compared to in-processing. Despite these benefits, existing methods face other challenges that limit their applicability: they require knowledge of the sensitive attributes at inference time and are oftentimes outperformed by in-processing. In this paper, we propose a general framework to transform any in-processing method with a penalized objective into a post-processing procedure. The resulting method is specifically designed to overcome the aforementioned shortcomings of prior post-processing approaches. Furthermore, we show theoretically and through extensive experiments on real-world data that the resulting post-processing method matches or even surpasses the fairness-error trade-off offered by the in-processing counterpart.
Can semi-supervised learning use all the data effectively? A lower bound perspective
Nov 30, 2023Prior works have shown that semi-supervised learning algorithms can leverage unlabeled data to improve over the labeled sample complexity of supervised learning (SL) algorithms. However, existing theoretical analyses focus on regimes where the unlabeled data is sufficient to learn a good decision boundary using unsupervised learning (UL) alone. This begs the question: Can SSL algorithms simultaneously improve upon both UL and SL? To this end, we derive a tight lower bound for 2-Gaussian mixture models that explicitly depends on the labeled and the unlabeled dataset size as well as the signal-to-noise ratio of the mixture distribution. Surprisingly, our result implies that no SSL algorithm can improve upon the minimax-optimal statistical error rates of SL or UL algorithms for these distributions. Nevertheless, we show empirically on real-world data that SSL algorithms can still outperform UL and SL methods. Therefore, our work suggests that, while proving performance gains for SSL algorithms is possible, it requires careful tracking of constants.
Interpolation can hurt robust generalization even when there is no noise
Aug 05, 2021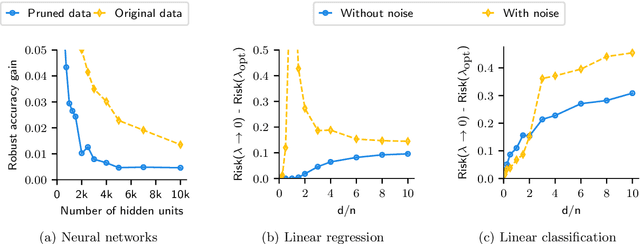
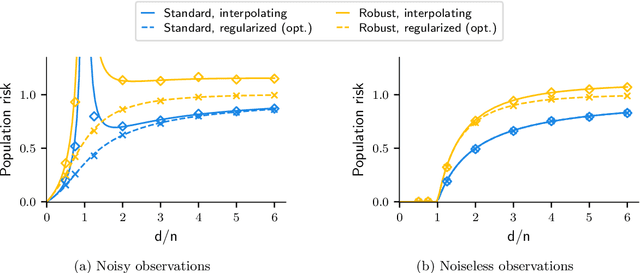
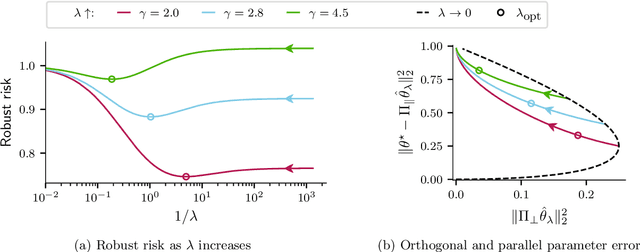
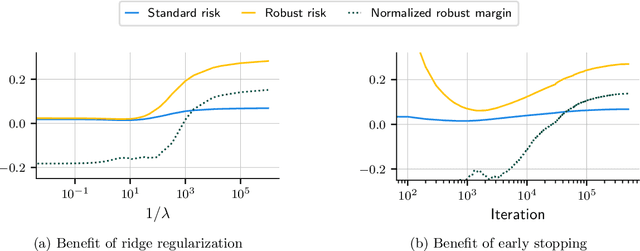
Numerous recent works show that overparameterization implicitly reduces variance for min-norm interpolators and max-margin classifiers. These findings suggest that ridge regularization has vanishing benefits in high dimensions. We challenge this narrative by showing that, even in the absence of noise, avoiding interpolation through ridge regularization can significantly improve generalization. We prove this phenomenon for the robust risk of both linear regression and classification and hence provide the first theoretical result on robust overfitting.
Learn what you can't learn: Regularized Ensembles for Transductive Out-of-distribution Detection
Dec 10, 2020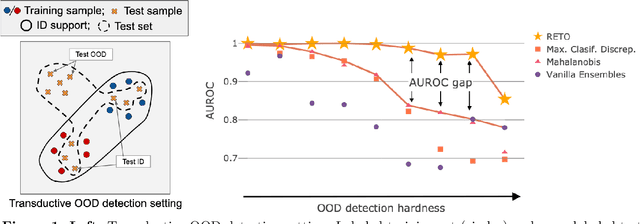
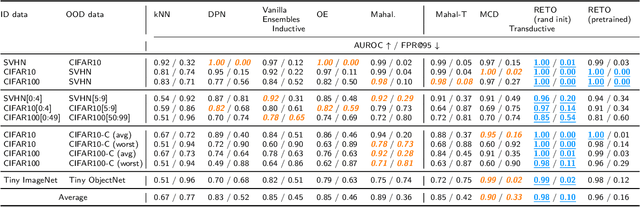


Machine learning models are often used in practice if they achieve good generalization results on in-distribution (ID) holdout data. When employed in the wild, they should also be able to detect samples they cannot predict well. We show that current out-of-distribution (OOD) detection algorithms for neural networks produce unsatisfactory results in a variety of OOD detection scenarios, e.g. when OOD data consists of unseen classes or corrupted measurements. This paper studies how such "hard" OOD scenarios can benefit from adjusting the detection method after observing a batch of the test data. This transductive setting is relevant when the advantage of even a slightly delayed OOD detection outweighs the financial cost for additional tuning. We propose a novel method that uses an artificial labeling scheme for the test data and regularization to obtain ensembles of models that produce contradictory predictions only on the OOD samples in a test batch. We show via comprehensive experiments that our approach is indeed able to significantly outperform both inductive and transductive baselines on difficult OOD detection scenarios, such as unseen classes on CIFAR-10/CIFAR-100, severe corruptions(CIFAR-C), and strong covariate shift (ImageNet vs ObjectNet).