 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn what you can't learn: Regularized Ensembles for Transductive Out-of-distribution Detection
Paper and Code
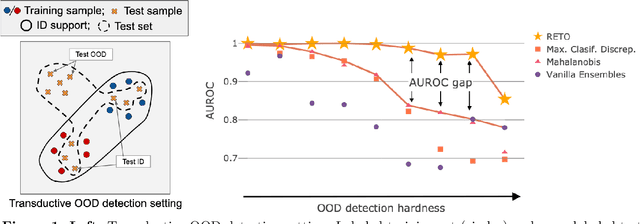
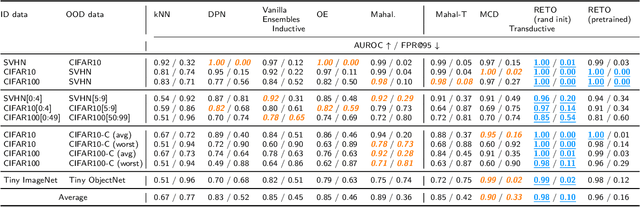


Machine learning models are often used in practice if they achieve good generalization results on in-distribution (ID) holdout data. When employed in the wild, they should also be able to detect samples they cannot predict well. We show that current out-of-distribution (OOD) detection algorithms for neural networks produce unsatisfactory results in a variety of OOD detection scenarios, e.g. when OOD data consists of unseen classes or corrupted measurements. This paper studies how such "hard" OOD scenarios can benefit from adjusting the detection method after observing a batch of the test data. This transductive setting is relevant when the advantage of even a slightly delayed OOD detection outweighs the financial cost for additional tuning. We propose a novel method that uses an artificial labeling scheme for the test data and regularization to obtain ensembles of models that produce contradictory predictions only on the OOD samples in a test batch. We show via comprehensive experiments that our approach is indeed able to significantly outperform both inductive and transductive baselines on difficult OOD detection scenarios, such as unseen classes on CIFAR-10/CIFAR-100, severe corruptions(CIFAR-C), and strong covariate shift (ImageNet vs ObjectNet).