 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the sample complexity of semi-supervised multi-objective learning
Aug 23, 2025In multi-objective learning (MOL), several possibly competing prediction tasks must be solved jointly by a single model. Achieving good trade-offs may require a model class $\mathcal{G}$ with larger capacity than what is necessary for solving the individual tasks. This, in turn, increases the statistical cost, as reflected in known MOL bounds that depend on the complexity of $\mathcal{G}$. We show that this cost is unavoidable for some losses, even in an idealized semi-supervised setting, where the learner has access to the Bayes-optimal solutions for the individual tasks as well as the marginal distributions over the covariates. On the other hand, for objectives defined with Bregman losses, we prove that the complexity of $\mathcal{G}$ may come into play only in terms of unlabeled data. Concretely, we establish sample complexity upper bounds, showing precisely when and how unlabeled data can significantly alleviate the need for labeled data. These rates are achieved by a simple, semi-supervised algorithm via pseudo-labeling.
Learning Pareto manifolds in high dimensions: How can regularization help?
Mar 11, 2025Simultaneously addressing multiple objectives is becoming increasingly important in modern machine learning. At the same time, data is often high-dimensional and costly to label. For a single objective such as prediction risk, conventional regularization techniques are known to improve generalization when the data exhibits low-dimensional structure like sparsity. However, it is largely unexplored how to leverage this structure in the context of multi-objective learning (MOL) with multiple competing objectives. In this work, we discuss how the application of vanilla regularization approaches can fail, and propose a two-stage MOL framework that can successfully leverage low-dimensional structure. We demonstrate its effectiveness experimentally for multi-distribution learning and fairness-risk trade-offs.
Early-Stopped Mirror Descent for Linear Regression over Convex Bodies
Mar 05, 2025Early-stopped iterative optimization methods are widely used as alternatives to explicit regularization, and direct comparisons between early-stopping and explicit regularization have been established for many optimization geometries. However, most analyses depend heavily on the specific properties of the optimization geometry or strong convexity of the empirical objective, and it remains unclear whether early-stopping could ever be less statistically efficient than explicit regularization for some particular shape constraint, especially in the overparameterized regime. To address this question, we study the setting of high-dimensional linear regression under additive Gaussian noise when the ground truth is assumed to lie in a known convex body and the task is to minimize the in-sample mean squared error. Our main result shows that for any convex body and any design matrix, up to an absolute constant factor, the worst-case risk of unconstrained early-stopped mirror descent with an appropriate potential is at most that of the least squares estimator constrained to the convex body. We achieve this by constructing algorithmic regularizers based on the Minkowski functional of the convex body.
A Framework for Verification of Wasserstein Adversarial Robustness
Oct 13, 2021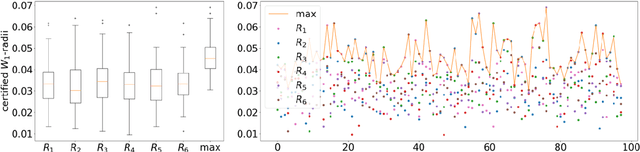


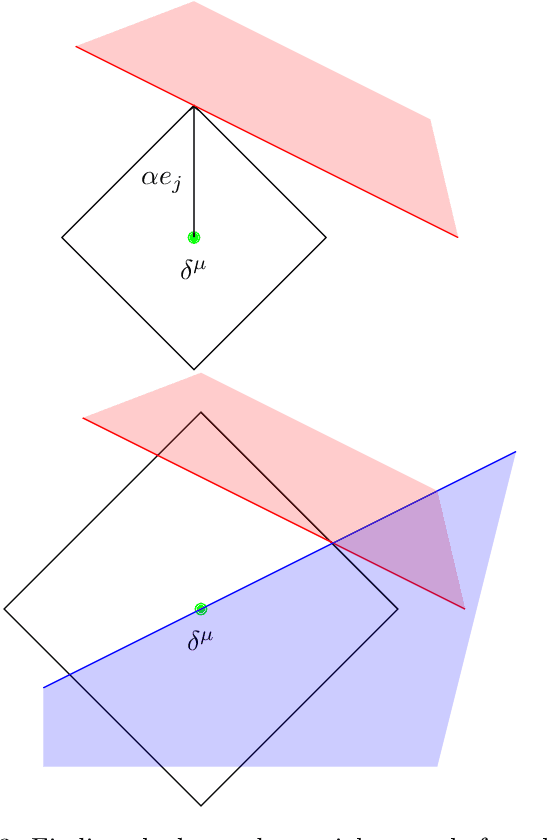
Machine learning image classifiers are susceptible to adversarial and corruption perturbations. Adding imperceptible noise to images can lead to severe misclassifications of the machine learning model. Using $L_p$-norms for measuring the size of the noise fails to capture human similarity perception, which is why optimal transport based distance measures like the Wasserstein metric are increasingly being used in the field of adversarial robustness. Verifying the robustness of classifiers using the Wasserstein metric can be achieved by proving the absence of adversarial examples (certification) or proving their presence (attack). In this work we present a framework based on the work by Levine and Feizi, which allows us to transfer existing certification methods for convex polytopes or $L_1$-balls to the Wasserstein threat model. The resulting certification can be complete or incomplete, depending on whether convex polytopes or $L_1$-balls were chosen. Additionally, we present a new Wasserstein adversarial attack that is projected gradient descent based and which has a significantly reduced computational burden compared to existing attack approaches.