 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Recommender System Effects with Simulated Users
Jan 12, 2021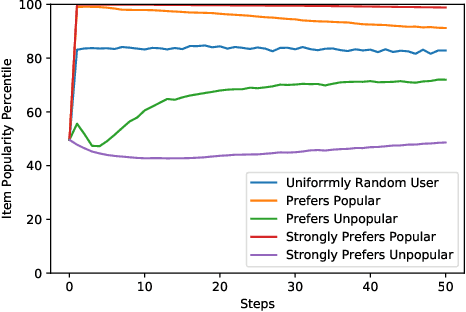

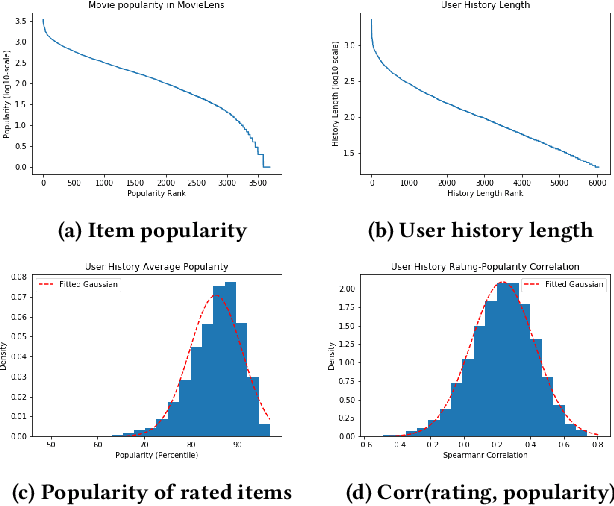
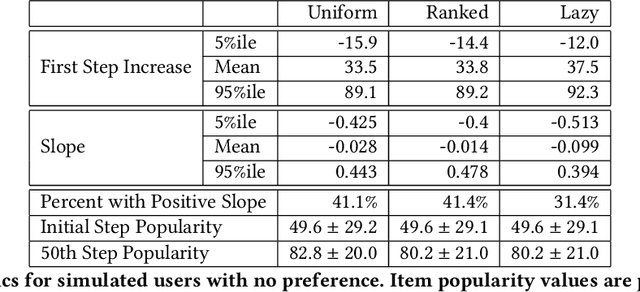
Imagine a food recommender system -- how would we check if it is \emph{causing} and fostering unhealthy eating habits or merely reflecting users' interests? How much of a user's experience over time with a recommender is caused by the recommender system's choices and biases, and how much is based on the user's preferences and biases? Popularity bias and filter bubbles are two of the most well-studied recommender system biases, but most of the prior research has focused on understanding the system behavior in a single recommendation step. How do these biases interplay with user behavior, and what types of user experiences are created from repeated interactions? In this work, we offer a simulation framework for measuring the impact of a recommender system under different types of user behavior. Using this simulation framework, we can (a) isolate the effect of the recommender system from the user preferences, and (b) examine how the system performs not just on average for an "average user" but also the extreme experiences under atypical user behavior. As part of the simulation framework, we propose a set of evaluation metrics over the simulations to understand the recommender system's behavior. Finally, we present two empirical case studies -- one on traditional collaborative filtering in MovieLens and one on a large-scale production recommender system -- to understand how popularity bias manifests over time.
Fairness without Demographics through Adversarially Reweighted Learning
Jun 24, 2020
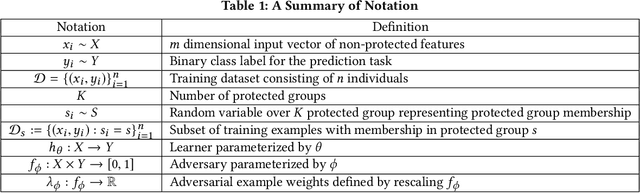
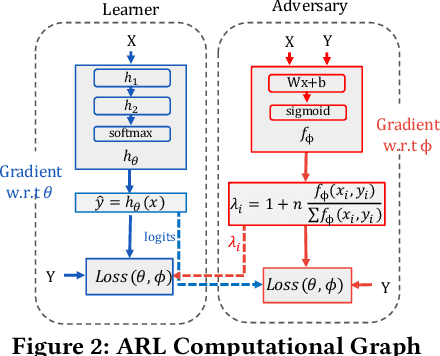
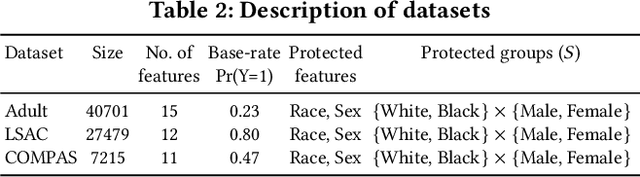
Much of the previous machine learning (ML) fairness literature assumes that protected features such as race and sex are present in the dataset, and relies upon them to mitigate fairness concerns. However, in practice factors like privacy and regulation often preclude the collection of protected features, or their use for training or inference, severely limiting the applicability of traditional fairness research. Therefore we ask: How can we train a ML model to improve fairness when we do not even know the protected group memberships? In this work we address this problem by proposing Adversarially Reweighted Learning (ARL). In particular, we hypothesize that non-protected features and task labels are valuable for identifying fairness issues, and can be used to co-train an adversarial reweighting approach for improving fairness. Our results show that ARL improves Rawlsian Max-Min fairness, with significant AUC improvements for worst-case protected groups in multiple datasets,outperforming state-of-the-art alternatives.
A deep learning system for differential diagnosis of skin diseases
Sep 11, 2019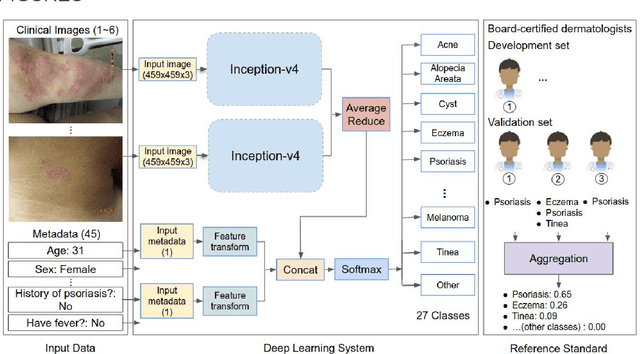
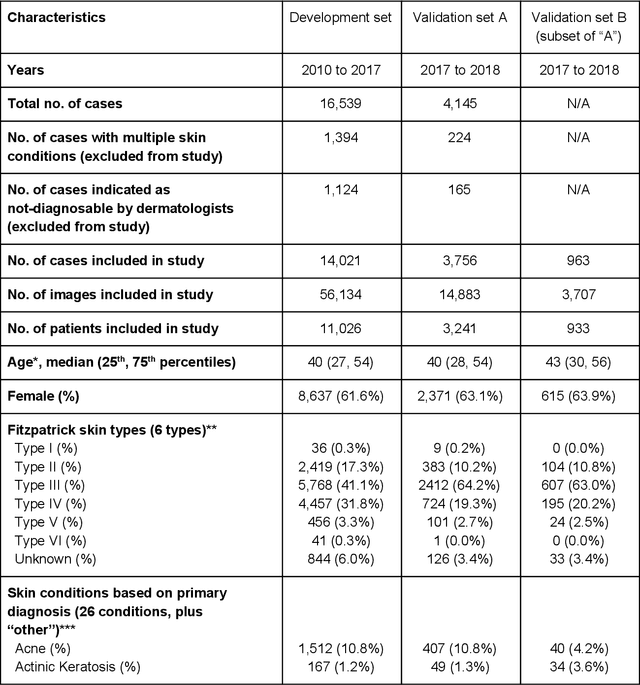
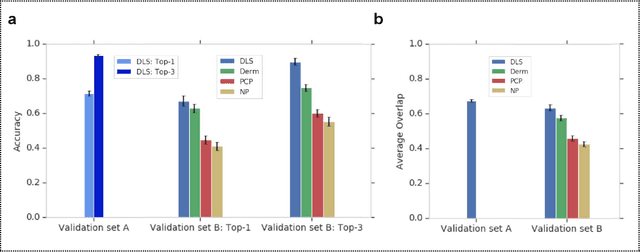
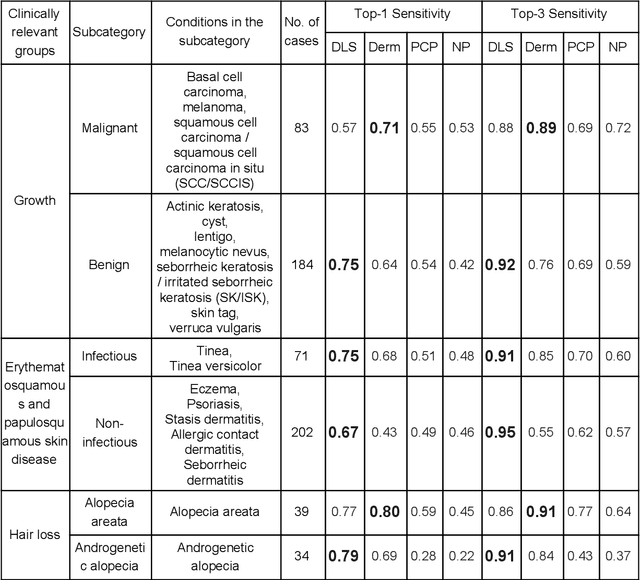
Skin conditions affect an estimated 1.9 billion people worldwide. A shortage of dermatologists causes long wait times and leads patients to seek dermatologic care from general practitioners. However, the diagnostic accuracy of general practitioners has been reported to be only 0.24-0.70 (compared to 0.77-0.96 for dermatologists), resulting in referral errors, delays in care, and errors in diagnosis and treatment. In this paper, we developed a deep learning system (DLS) to provide a differential diagnosis of skin conditions for clinical cases (skin photographs and associated medical histories). The DLS distinguishes between 26 skin conditions that represent roughly 80% of the volume of skin conditions seen in primary care. The DLS was developed and validated using de-identified cases from a teledermatology practice serving 17 clinical sites via a temporal split: the first 14,021 cases for development and the last 3,756 cases for validation. On the validation set, where a panel of three board-certified dermatologists defined the reference standard for every case, the DLS achieved 0.71 and 0.93 top-1 and top-3 accuracies respectively. For a random subset of the validation set (n=963 cases), 18 clinicians reviewed the cases for comparison. On this subset, the DLS achieved a 0.67 top-1 accuracy, non-inferior to board-certified dermatologists (0.63, p<0.001), and higher than primary care physicians (PCPs, 0.45) and nurse practitioners (NPs, 0.41). The top-3 accuracy showed a similar trend: 0.90 DLS, 0.75 dermatologists, 0.60 PCPs, and 0.55 NPs. These results highlight the potential of the DLS to augment general practitioners to accurately diagnose skin conditions by suggesting differential diagnoses that may not have been considered. Future work will be needed to prospectively assess the clinical impact of using this tool in actual clinical workflows.