 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025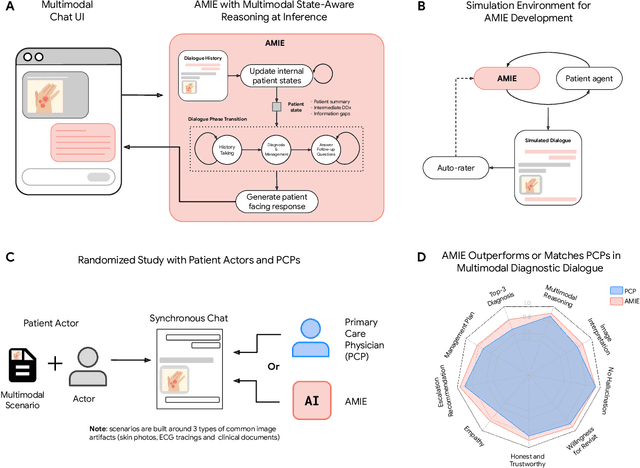
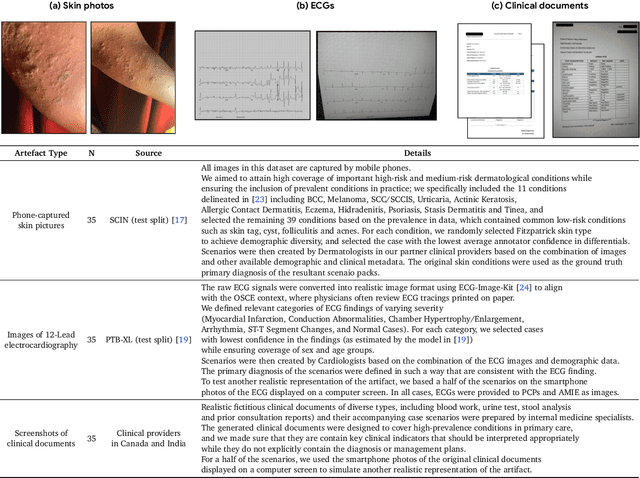
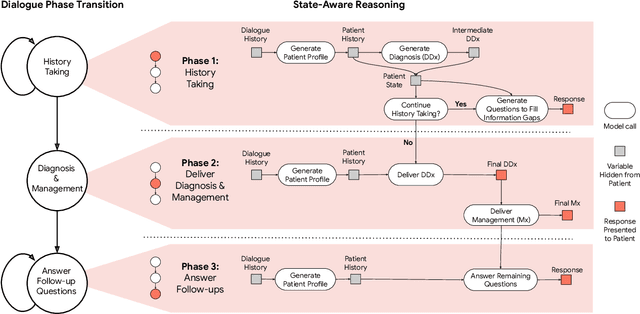
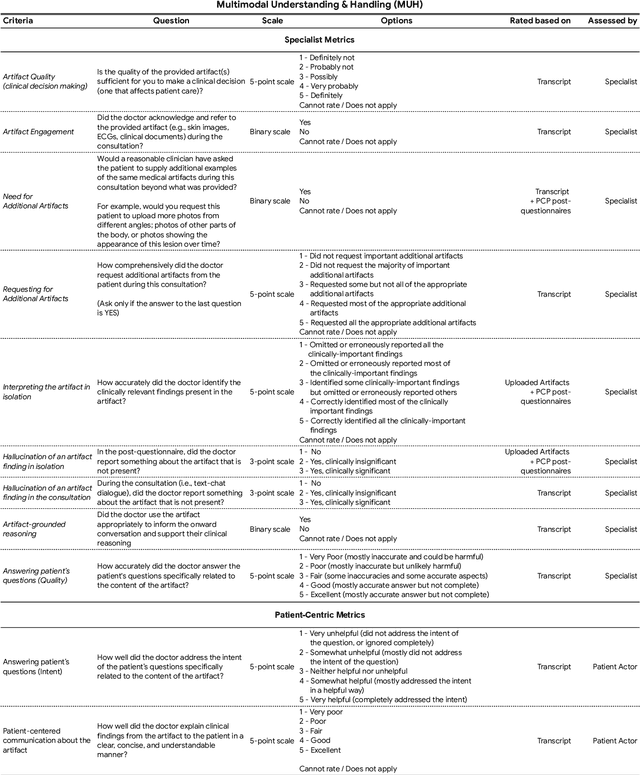
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
A deep learning system for differential diagnosis of skin diseases
Sep 11, 2019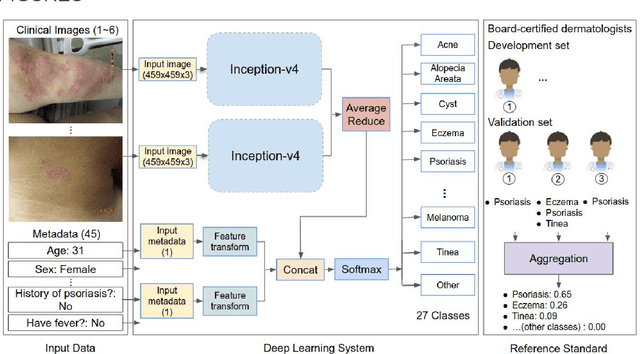
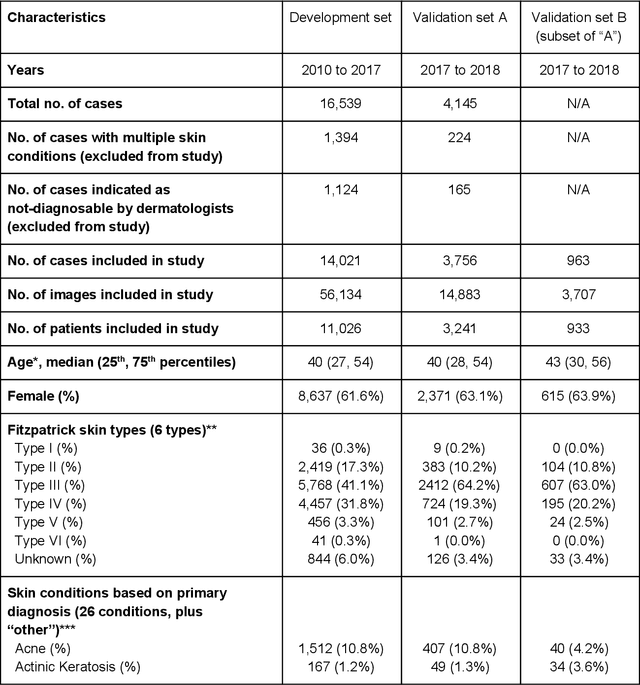
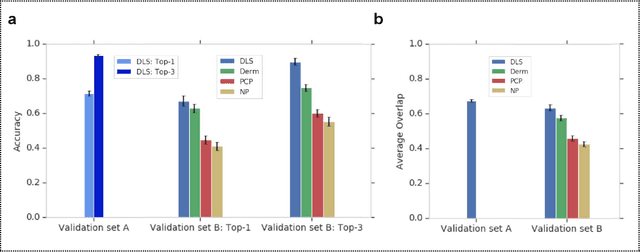
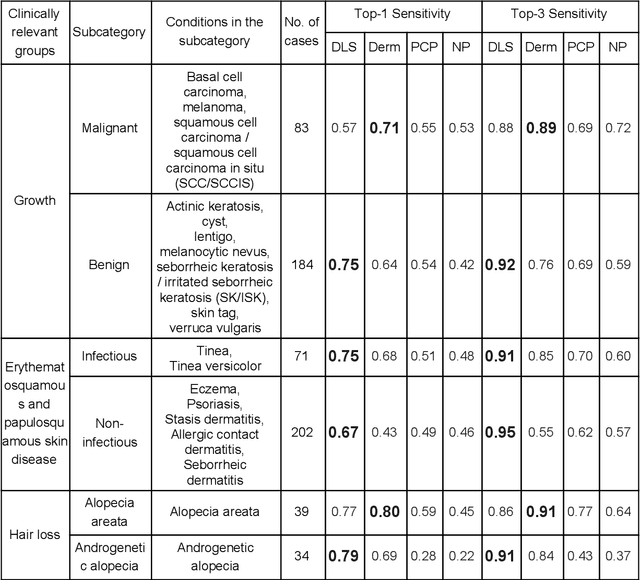
Skin conditions affect an estimated 1.9 billion people worldwide. A shortage of dermatologists causes long wait times and leads patients to seek dermatologic care from general practitioners. However, the diagnostic accuracy of general practitioners has been reported to be only 0.24-0.70 (compared to 0.77-0.96 for dermatologists), resulting in referral errors, delays in care, and errors in diagnosis and treatment. In this paper, we developed a deep learning system (DLS) to provide a differential diagnosis of skin conditions for clinical cases (skin photographs and associated medical histories). The DLS distinguishes between 26 skin conditions that represent roughly 80% of the volume of skin conditions seen in primary care. The DLS was developed and validated using de-identified cases from a teledermatology practice serving 17 clinical sites via a temporal split: the first 14,021 cases for development and the last 3,756 cases for validation. On the validation set, where a panel of three board-certified dermatologists defined the reference standard for every case, the DLS achieved 0.71 and 0.93 top-1 and top-3 accuracies respectively. For a random subset of the validation set (n=963 cases), 18 clinicians reviewed the cases for comparison. On this subset, the DLS achieved a 0.67 top-1 accuracy, non-inferior to board-certified dermatologists (0.63, p<0.001), and higher than primary care physicians (PCPs, 0.45) and nurse practitioners (NPs, 0.41). The top-3 accuracy showed a similar trend: 0.90 DLS, 0.75 dermatologists, 0.60 PCPs, and 0.55 NPs. These results highlight the potential of the DLS to augment general practitioners to accurately diagnose skin conditions by suggesting differential diagnoses that may not have been considered. Future work will be needed to prospectively assess the clinical impact of using this tool in actual clinical workflows.