 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRFM: Dissecting Relational In-Context Learning
Jun 03, 2026Relational Foundation Models (RFMs) promise a single pre-trained predictor that, given any relational database, returns predictions in one forward pass via relational in-context learning (ICL). Yet a substantial gap separates open RFMs from their commercial counterparts, and the origin of this gap has not been systematically understood. We dissect a representative framework, the Relational Transformer (RT), from two perspectives. Model side: we show that RT performs relation-level ICL, and a kernel regression view shows it fails when sparse label-cell coverage yields an underdetermined regression. Data side: we ablate RT's pre-training source and find that existing synthetic-only pre-training and in-distribution pre-training drive the same architecture into different regimes, lazy vs. feature-learning. Probing this gap reveals that the missing ingredient is a support-identifiable relational latent in the label-generation process. These two diagnoses translate into (1) a dual-stage ICL architecture that combines the relational backbone with a batch-level ICL layer lifted from a pre-trained tabular foundation model to overcome relation-level label scarcity, and (2) a homophily-aware synthetic plus continual real-data pre-training mixture, augmented with a prototype-based regularization. These choices define OpenRFM, a simple yet effective RFM that improves average task performance by approximately 30% over the RT backbone and surpasses the commercial model KumoRFMv1 on a large set of evaluation tasks.
Exploring Cross-Scenario Generality of Agentic Memory Systems: Diagnostics and a Strong Baseline
Jun 03, 2026LLM agents accumulate histories that outgrow their context windows, motivating a growing literature on memory systems. Yet most existing designs are tuned to a single scenario (multi-session chat or a single trajectory format), and there is little evidence that they generalize across the heterogeneous trajectories agents encounter in deployment. We revisit eight memory systems plus an agentic harness for search problems, on five scenarios: single-turn QA, multi-session chat, agentic-trajectory QA, memory stress tests, and long-horizon agentic tasks. The harness, which self-manages flat text-file storage via tool calls, achieves the best cross-task ranking, suggesting that memory performance hinges on giving the agent active control over storage and retrieval rather than on a passive store behind a fixed pipeline. We instantiate this insight in AutoMEM, an agentic memory harness with a self-managed tool interface that achieves the best cross-scenario generality among the systems we evaluate.
DeepContext: A Context-aware, Cross-platform, and Cross-framework Tool for Performance Profiling and Analysis of Deep Learning Workloads
Nov 05, 2024



Effective performance profiling and analysis are essential for optimizing training and inference of deep learning models, especially given the growing complexity of heterogeneous computing environments. However, existing tools often lack the capability to provide comprehensive program context information and performance optimization insights for sophisticated interactions between CPUs and GPUs. This paper introduces DeepContext, a novel profiler that links program contexts across high-level Python code, deep learning frameworks, underlying libraries written in C/C++, as well as device code executed on GPUs. DeepContext incorporates measurements of both coarse- and fine-grained performance metrics for major deep learning frameworks, such as PyTorch and JAX, and is compatible with GPUs from both Nvidia and AMD, as well as various CPU architectures, including x86 and ARM. In addition, DeepContext integrates a novel GUI that allows users to quickly identify hotpots and an innovative automated performance analyzer that suggests users with potential optimizations based on performance metrics and program context. Through detailed use cases, we demonstrate how DeepContext can help users identify and analyze performance issues to enable quick and effective optimization of deep learning workloads. We believe Deep Context is a valuable tool for users seeking to optimize complex deep learning workflows across multiple compute environments.
Efficient model compression with Random Operation Access Specific Tile (ROAST) hashing
Jul 21, 2022
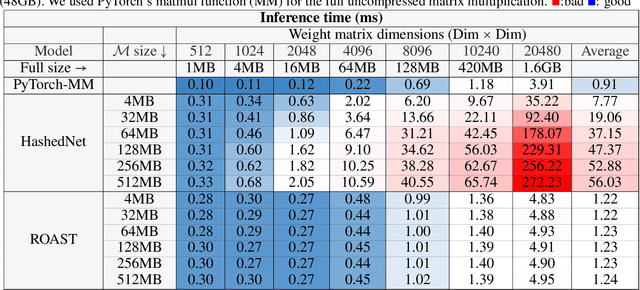

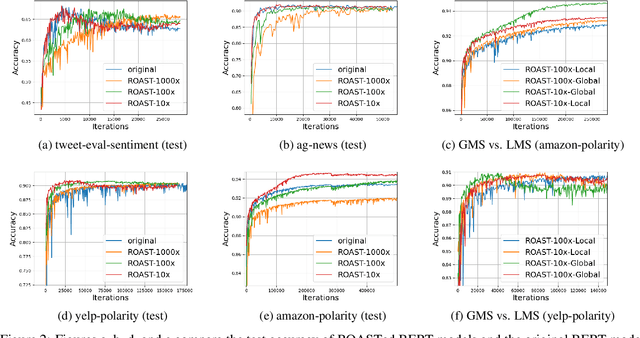
Advancements in deep learning are often associated with increasing model sizes. The model size dramatically affects the deployment cost and latency of deep models. For instance, models like BERT cannot be deployed on edge devices and mobiles due to their sheer size. As a result, most advances in Deep Learning are yet to reach the edge. Model compression has sought much-deserved attention in literature across natural language processing, vision, and recommendation domains. This paper proposes a model-agnostic, cache-friendly model compression approach: Random Operation Access Specific Tile (ROAST) hashing. ROAST collapses the parameters by clubbing them through a lightweight mapping. Notably, while clubbing these parameters, ROAST utilizes cache hierarchies by aligning the memory access pattern with the parameter access pattern. ROAST is up to $\sim 25 \times$ faster to train and $\sim 50 \times$ faster to infer than the popular parameter sharing method HashedNet. Additionally, ROAST introduces global weight sharing, which is empirically and theoretically superior to local weight sharing in HashedNet, and can be of independent interest in itself. With ROAST, we present the first compressed BERT, which is $100\times - 1000\times$ smaller but does not result in quality degradation. These compression levels on universal architecture like transformers are promising for the future of SOTA model deployment on resource-constrained devices like mobile and edge devices