 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Weakly-supervised Video Temporal Grounding From a Game Perspective
May 26, 2026This paper addresses the challenging task of weakly-supervised video temporal grounding. Existing approaches are generally based on the moment proposal selection framework that utilizes contrastive learning and reconstruction paradigm for scoring the pre-defined moment proposals. Although they have achieved significant progress, we argue that their current frameworks have overlooked two indispensable issues: 1) Coarse-grained cross-modal learning: previous methods solely capture the global video-level alignment with the query, failing to model the detailed consistency between video frames and query words for accurately grounding the moment boundaries. 2) Complex moment proposals: their performance severely relies on the quality of proposals, which are also time-consuming and complicated for selection. To this end, in this paper, we make the first attempt to tackle this task from a novel game perspective, which effectively learns the uncertain relationship between each vision-language pair with diverse granularity and flexible combination for multi-level cross-modal interaction.Specifically, we creatively model each video frame and query word as game players with multivariate cooperative game theory to learn their contribution to the cross-modal similarity score. By quantifying the trend of frame-word cooperation within a coalition via the game-theoretic interaction, we are able to value all uncertain but possible correspondence between frames and words. Finally, instead of using moment proposals, we utilize the learned query-guided frame-wise scores for better moment localization.Experiments show that our method achieves superior performance on both Charades-STA and ActivityNet Caption datasets.
Sketch Then Generate: Providing Incremental User Feedback and Guiding LLM Code Generation through Language-Oriented Code Sketches
May 07, 2024

Crafting effective prompts for code generation or editing with Large Language Models (LLMs) is not an easy task. Particularly, the absence of immediate, stable feedback during prompt crafting hinders effective interaction, as users are left to mentally imagine possible outcomes until the code is generated. In response, we introduce Language-Oriented Code Sketching, an interactive approach that provides instant, incremental feedback in the form of code sketches (i.e., incomplete code outlines) during prompt crafting. This approach converts a prompt into a code sketch by leveraging the inherent linguistic structures within the prompt and applying classic natural language processing techniques. The sketch then serves as an intermediate placeholder that not only previews the intended code structure but also guides the LLM towards the desired code, thereby enhancing human-LLM interaction. We conclude by discussing the approach's applicability and future plans.
A Comprehensive Survey for Evaluation Methodologies of AI-Generated Music
Aug 26, 2023In recent years, AI-generated music has made significant progress, with several models performing well in multimodal and complex musical genres and scenes. While objective metrics can be used to evaluate generative music, they often lack interpretability for musical evaluation. Therefore, researchers often resort to subjective user studies to assess the quality of the generated works, which can be resource-intensive and less reproducible than objective metrics. This study aims to comprehensively evaluate the subjective, objective, and combined methodologies for assessing AI-generated music, highlighting the advantages and disadvantages of each approach. Ultimately, this study provides a valuable reference for unifying generative AI in the field of music evaluation.
Tracking Objects and Activities with Attention for Temporal Sentence Grounding
Feb 21, 2023



Temporal sentence grounding (TSG) aims to localize the temporal segment which is semantically aligned with a natural language query in an untrimmed video.Most existing methods extract frame-grained features or object-grained features by 3D ConvNet or detection network under a conventional TSG framework, failing to capture the subtle differences between frames or to model the spatio-temporal behavior of core persons/objects. In this paper, we introduce a new perspective to address the TSG task by tracking pivotal objects and activities to learn more fine-grained spatio-temporal behaviors. Specifically, we propose a novel Temporal Sentence Tracking Network (TSTNet), which contains (A) a Cross-modal Targets Generator to generate multi-modal templates and search space, filtering objects and activities, and (B) a Temporal Sentence Tracker to track multi-modal targets for modeling the targets' behavior and to predict query-related segment. Extensive experiments and comparisons with state-of-the-arts are conducted on challenging benchmarks: Charades-STA and TACoS. And our TSTNet achieves the leading performance with a considerable real-time speed.
Rethinking the Video Sampling and Reasoning Strategies for Temporal Sentence Grounding
Jan 02, 2023Temporal sentence grounding (TSG) aims to identify the temporal boundary of a specific segment from an untrimmed video by a sentence query. All existing works first utilize a sparse sampling strategy to extract a fixed number of video frames and then conduct multi-modal interactions with query sentence for reasoning. However, we argue that these methods have overlooked two indispensable issues: 1) Boundary-bias: The annotated target segment generally refers to two specific frames as corresponding start and end timestamps. The video downsampling process may lose these two frames and take the adjacent irrelevant frames as new boundaries. 2) Reasoning-bias: Such incorrect new boundary frames also lead to the reasoning bias during frame-query interaction, reducing the generalization ability of model. To alleviate above limitations, in this paper, we propose a novel Siamese Sampling and Reasoning Network (SSRN) for TSG, which introduces a siamese sampling mechanism to generate additional contextual frames to enrich and refine the new boundaries. Specifically, a reasoning strategy is developed to learn the inter-relationship among these frames and generate soft labels on boundaries for more accurate frame-query reasoning. Such mechanism is also able to supplement the absent consecutive visual semantics to the sampled sparse frames for fine-grained activity understanding. Extensive experiments demonstrate the effectiveness of SSRN on three challenging datasets.
Gaussian Kernel-based Cross Modal Network for Spatio-Temporal Video Grounding
Jul 02, 2022
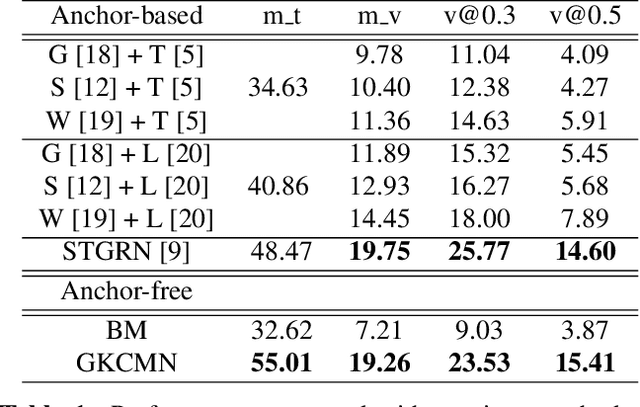
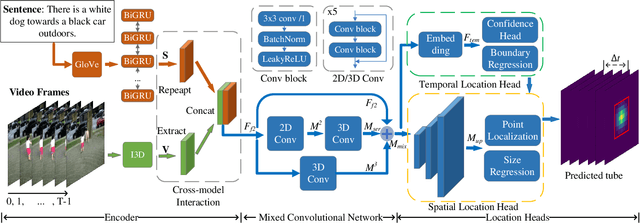
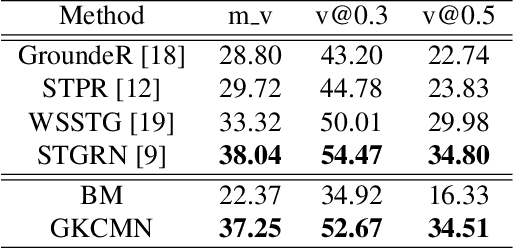
Spatial-Temporal Video Grounding (STVG) is a challenging task which aims to localize the spatio-temporal tube of the interested object semantically according to a natural language query. Most previous works not only severely rely on the anchor boxes extracted by Faster R-CNN, but also simply regard the video as a series of individual frames, thus lacking their temporal modeling. Instead, in this paper, we are the first to propose an anchor-free framework for STVG, called Gaussian Kernel-based Cross Modal Network (GKCMN). Specifically, we utilize the learned Gaussian Kernel-based heatmaps of each video frame to locate the query-related object. A mixed serial and parallel connection network is further developed to leverage both spatial and temporal relations among frames for better grounding. Experimental results on VidSTG dataset demonstrate the effectiveness of our proposed GKCMN.
Equivariant geometric learning for digital rock physics: estimating formation factor and effective permeability tensors from Morse graph
Apr 12, 2021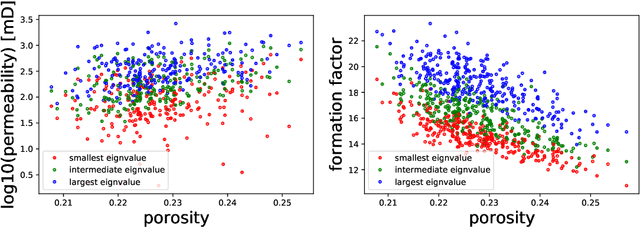
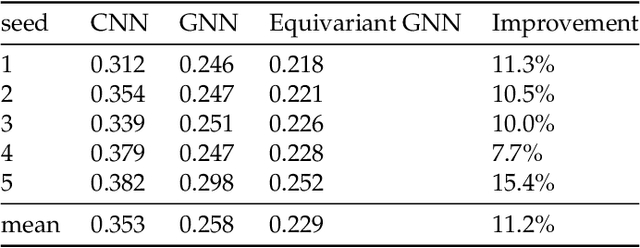
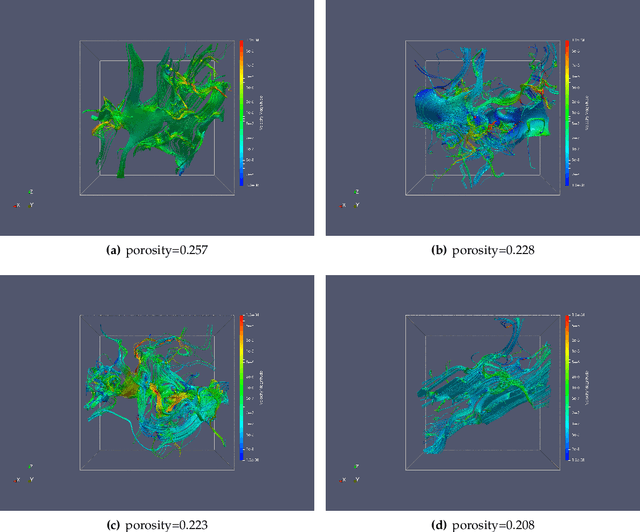
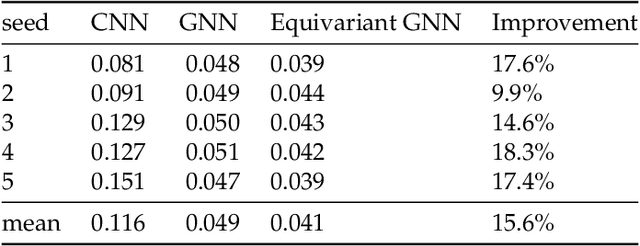
We present a SE(3)-equivariant graph neural network (GNN) approach that directly predicting the formation factor and effective permeability from micro-CT images. FFT solvers are established to compute both the formation factor and effective permeability, while the topology and geometry of the pore space are represented by a persistence-based Morse graph. Together, they constitute the database for training, validating, and testing the neural networks. While the graph and Euclidean convolutional approaches both employ neural networks to generate low-dimensional latent space to represent the features of the micro-structures for forward predictions, the SE(3) equivariant neural network is found to generate more accurate predictions, especially when the training data is limited. Numerical experiments have also shown that the new SE(3) approach leads to predictions that fulfill the material frame indifference whereas the predictions from classical convolutional neural networks (CNN) may suffer from spurious dependence on the coordinate system of the training data. Comparisons among predictions inferred from training the CNN and those from graph convolutional neural networks (GNN) with and without the equivariant constraint indicate that the equivariant graph neural network seems to perform better than the CNN and GNN without enforcing equivariant constraints.