 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Kernel-based Cross Modal Network for Spatio-Temporal Video Grounding
Paper and Code
Jul 02, 2022
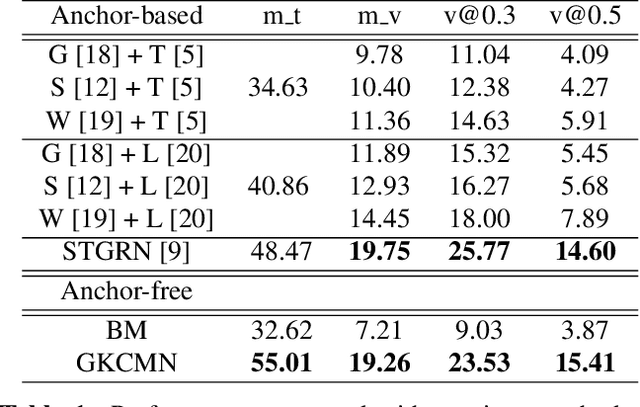
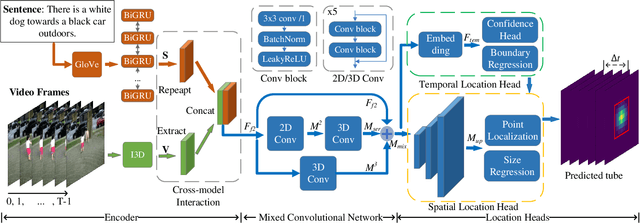
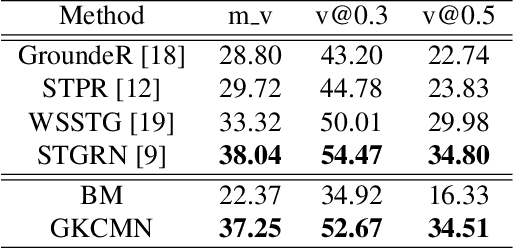
Spatial-Temporal Video Grounding (STVG) is a challenging task which aims to localize the spatio-temporal tube of the interested object semantically according to a natural language query. Most previous works not only severely rely on the anchor boxes extracted by Faster R-CNN, but also simply regard the video as a series of individual frames, thus lacking their temporal modeling. Instead, in this paper, we are the first to propose an anchor-free framework for STVG, called Gaussian Kernel-based Cross Modal Network (GKCMN). Specifically, we utilize the learned Gaussian Kernel-based heatmaps of each video frame to locate the query-related object. A mixed serial and parallel connection network is further developed to leverage both spatial and temporal relations among frames for better grounding. Experimental results on VidSTG dataset demonstrate the effectiveness of our proposed GKCMN.