 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftware-Hardware Co-optimization for Modular E2E AV Paradigm: A Unified Framework of Optimization Approaches, Simulation Environment and Evaluation Metrics
Jan 12, 2026Modular end-to-end (ME2E) autonomous driving paradigms combine modular interpretability with global optimization capability and have demonstrated strong performance. However, existing studies mainly focus on accuracy improvement, while critical system-level factors such as inference latency and energy consumption are often overlooked, resulting in increasingly complex model designs that hinder practical deployment. Prior efforts on model compression and acceleration typically optimize either the software or hardware side in isolation. Software-only optimization cannot fundamentally remove intermediate tensor access and operator scheduling overheads, whereas hardware-only optimization is constrained by model structure and precision. As a result, the real-world benefits of such optimizations are often limited. To address these challenges, this paper proposes a reusable software and hardware co-optimization and closed-loop evaluation framework for ME2E autonomous driving inference. The framework jointly integrates software-level model optimization with hardware-level computation optimization under a unified system-level objective. In addition, a multidimensional evaluation metric is introduced to assess system performance by jointly considering safety, comfort, efficiency, latency, and energy, enabling quantitative comparison of different optimization strategies. Experiments across multiple ME2E autonomous driving stacks show that the proposed framework preserves baseline-level driving performance while significantly reducing inference latency and energy consumption, achieving substantial overall system-level improvements. These results demonstrate that the proposed framework provides practical and actionable guidance for efficient deployment of ME2E autonomous driving systems.
MMHU: A Massive-Scale Multimodal Benchmark for Human Behavior Understanding
Jul 16, 2025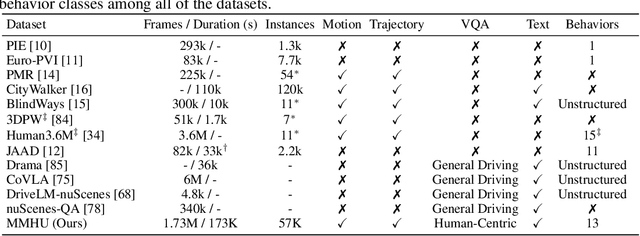



Humans are integral components of the transportation ecosystem, and understanding their behaviors is crucial to facilitating the development of safe driving systems. Although recent progress has explored various aspects of human behavior$\unicode{x2014}$such as motion, trajectories, and intention$\unicode{x2014}$a comprehensive benchmark for evaluating human behavior understanding in autonomous driving remains unavailable. In this work, we propose $\textbf{MMHU}$, a large-scale benchmark for human behavior analysis featuring rich annotations, such as human motion and trajectories, text description for human motions, human intention, and critical behavior labels relevant to driving safety. Our dataset encompasses 57k human motion clips and 1.73M frames gathered from diverse sources, including established driving datasets such as Waymo, in-the-wild videos from YouTube, and self-collected data. A human-in-the-loop annotation pipeline is developed to generate rich behavior captions. We provide a thorough dataset analysis and benchmark multiple tasks$\unicode{x2014}$ranging from motion prediction to motion generation and human behavior question answering$\unicode{x2014}$thereby offering a broad evaluation suite. Project page : https://MMHU-Benchmark.github.io.
HumanMM: Global Human Motion Recovery from Multi-shot Videos
Mar 10, 2025In this paper, we present a novel framework designed to reconstruct long-sequence 3D human motion in the world coordinates from in-the-wild videos with multiple shot transitions. Such long-sequence in-the-wild motions are highly valuable to applications such as motion generation and motion understanding, but are of great challenge to be recovered due to abrupt shot transitions, partial occlusions, and dynamic backgrounds presented in such videos. Existing methods primarily focus on single-shot videos, where continuity is maintained within a single camera view, or simplify multi-shot alignment in camera space only. In this work, we tackle the challenges by integrating an enhanced camera pose estimation with Human Motion Recovery (HMR) by incorporating a shot transition detector and a robust alignment module for accurate pose and orientation continuity across shots. By leveraging a custom motion integrator, we effectively mitigate the problem of foot sliding and ensure temporal consistency in human pose. Extensive evaluations on our created multi-shot dataset from public 3D human datasets demonstrate the robustness of our method in reconstructing realistic human motion in world coordinates.
A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models
Oct 08, 2024

The rapid development of large language models (LLMs) has significantly transformed the field of artificial intelligence, demonstrating remarkable capabilities in natural language processing and moving towards multi-modal functionality. These models are increasingly integrated into diverse applications, impacting both research and industry. However, their development and deployment present substantial challenges, including the need for extensive computational resources, high energy consumption, and complex software optimizations. Unlike traditional deep learning systems, LLMs require unique optimization strategies for training and inference, focusing on system-level efficiency. This paper surveys hardware and software co-design approaches specifically tailored to address the unique characteristics and constraints of large language models. This survey analyzes the challenges and impacts of LLMs on hardware and algorithm research, exploring algorithm optimization, hardware design, and system-level innovations. It aims to provide a comprehensive understanding of the trade-offs and considerations in LLM-centric computing systems, guiding future advancements in AI. Finally, we summarize the existing efforts in this space and outline future directions toward realizing production-grade co-design methodologies for the next generation of large language models and AI systems.
MLLM-FL: Multimodal Large Language Model Assisted Federated Learning on Heterogeneous and Long-tailed Data
Sep 09, 2024



Previous studies on federated learning (FL) often encounter performance degradation due to data heterogeneity among different clients. In light of the recent advances in multimodal large language models (MLLMs), such as GPT-4v and LLaVA, which demonstrate their exceptional proficiency in multimodal tasks, such as image captioning and multimodal question answering. We introduce a novel federated learning framework, named Multimodal Large Language Model Assisted Federated Learning (MLLM-FL), which which employs powerful MLLMs at the server end to address the heterogeneous and long-tailed challenges. Owing to the advanced cross-modality representation capabilities and the extensive open-vocabulary prior knowledge of MLLMs, our framework is adept at harnessing the extensive, yet previously underexploited, open-source data accessible from websites and powerful server-side computational resources. Hence, the MLLM-FL not only enhances the performance but also avoids increasing the risk of privacy leakage and the computational burden on local devices, distinguishing it from prior methodologies. Our framework has three key stages. Initially, prior to local training on local datasets of clients, we conduct global visual-text pretraining of the model. This pretraining is facilitated by utilizing the extensive open-source data available online, with the assistance of multimodal large language models. Subsequently, the pretrained model is distributed among various clients for local training. Finally, once the locally trained models are transmitted back to the server, a global alignment is carried out under the supervision of MLLMs to further enhance the performance. Experimental evaluations on established benchmarks, show that our framework delivers promising performance in the typical scenarios with data heterogeneity and long-tail distribution across different clients in FL.
Learning Traffic Crashes as Language: Datasets, Benchmarks, and What-if Causal Analyses
Jun 16, 2024


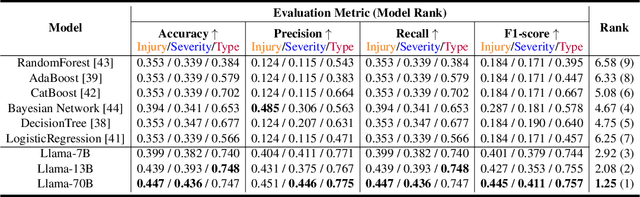
The increasing rate of road accidents worldwide results not only in significant loss of life but also imposes billions financial burdens on societies. Current research in traffic crash frequency modeling and analysis has predominantly approached the problem as classification tasks, focusing mainly on learning-based classification or ensemble learning methods. These approaches often overlook the intricate relationships among the complex infrastructure, environmental, human and contextual factors related to traffic crashes and risky situations. In contrast, we initially propose a large-scale traffic crash language dataset, named CrashEvent, summarizing 19,340 real-world crash reports and incorporating infrastructure data, environmental and traffic textual and visual information in Washington State. Leveraging this rich dataset, we further formulate the crash event feature learning as a novel text reasoning problem and further fine-tune various large language models (LLMs) to predict detailed accident outcomes, such as crash types, severity and number of injuries, based on contextual and environmental factors. The proposed model, CrashLLM, distinguishes itself from existing solutions by leveraging the inherent text reasoning capabilities of LLMs to parse and learn from complex, unstructured data, thereby enabling a more nuanced analysis of contributing factors. Our experiments results shows that our LLM-based approach not only predicts the severity of accidents but also classifies different types of accidents and predicts injury outcomes, all with averaged F1 score boosted from 34.9% to 53.8%. Furthermore, CrashLLM can provide valuable insights for numerous open-world what-if situational-awareness traffic safety analyses with learned reasoning features, which existing models cannot offer. We make our benchmark, datasets, and model public available for further exploration.
Advancing Real-time Pandemic Forecasting Using Large Language Models: A COVID-19 Case Study
Apr 10, 2024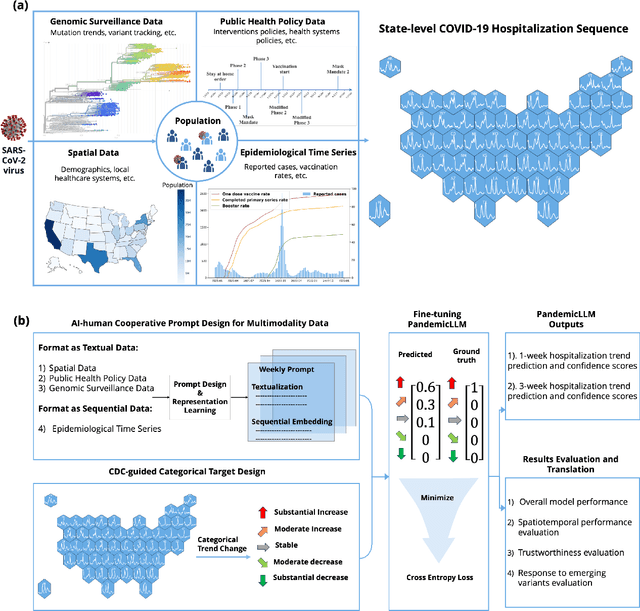
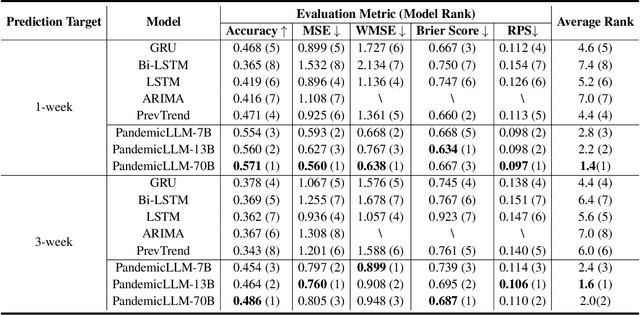

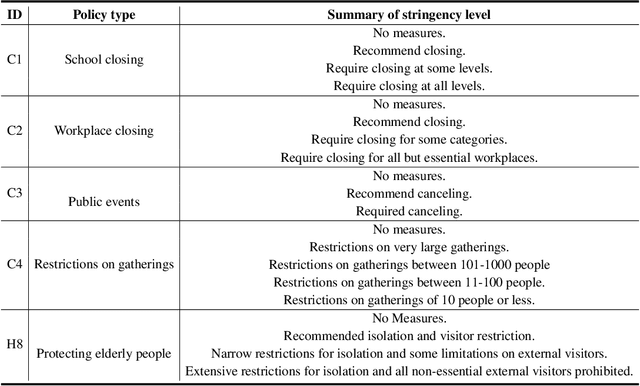
Forecasting the short-term spread of an ongoing disease outbreak is a formidable challenge due to the complexity of contributing factors, some of which can be characterized through interlinked, multi-modality variables such as epidemiological time series data, viral biology, population demographics, and the intersection of public policy and human behavior. Existing forecasting model frameworks struggle with the multifaceted nature of relevant data and robust results translation, which hinders their performances and the provision of actionable insights for public health decision-makers. Our work introduces PandemicLLM, a novel framework with multi-modal Large Language Models (LLMs) that reformulates real-time forecasting of disease spread as a text reasoning problem, with the ability to incorporate real-time, complex, non-numerical information that previously unattainable in traditional forecasting models. This approach, through a unique AI-human cooperative prompt design and time series representation learning, encodes multi-modal data for LLMs. The model is applied to the COVID-19 pandemic, and trained to utilize textual public health policies, genomic surveillance, spatial, and epidemiological time series data, and is subsequently tested across all 50 states of the U.S. Empirically, PandemicLLM is shown to be a high-performing pandemic forecasting framework that effectively captures the impact of emerging variants and can provide timely and accurate predictions. The proposed PandemicLLM opens avenues for incorporating various pandemic-related data in heterogeneous formats and exhibits performance benefits over existing models. This study illuminates the potential of adapting LLMs and representation learning to enhance pandemic forecasting, illustrating how AI innovations can strengthen pandemic responses and crisis management in the future.