 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Adaptive Mechanism Design
Dec 25, 2025


We study a sequential mechanism design problem in which a principal seeks to elicit truthful reports from multiple rational agents while starting with no prior knowledge of agents' beliefs. We introduce Distributionally Robust Adaptive Mechanism (DRAM), a general framework combining insights from both mechanism design and online learning to jointly address truthfulness and cost-optimality. Throughout the sequential game, the mechanism estimates agents' beliefs and iteratively updates a distributionally robust linear program with shrinking ambiguity sets to reduce payments while preserving truthfulness. Our mechanism guarantees truthful reporting with high probability while achieving $\tilde{O}(\sqrt{T})$ cumulative regret, and we establish a matching lower bound showing that no truthful adaptive mechanism can asymptotically do better. The framework generalizes to plug-in estimators, supporting structured priors and delayed feedback. To our knowledge, this is the first adaptive mechanism under general settings that maintains truthfulness and achieves optimal regret when incentive constraints are unknown and must be learned.
Frequency-Based Alignment of EEG and Audio Signals Using Contrastive Learning and SincNet for Auditory Attention Detection
Mar 06, 2025Humans exhibit a remarkable ability to focus auditory attention in complex acoustic environments, such as cocktail parties. Auditory attention detection (AAD) aims to identify the attended speaker by analyzing brain signals, such as electroencephalography (EEG) data. Existing AAD algorithms often leverage deep learning's powerful nonlinear modeling capabilities, few consider the neural mechanisms underlying auditory processing in the brain. In this paper, we propose SincAlignNet, a novel network based on an improved SincNet and contrastive learning, designed to align audio and EEG features for auditory attention detection. The SincNet component simulates the brain's processing of audio during auditory attention, while contrastive learning guides the model to learn the relationship between EEG signals and attended speech. During inference, we calculate the cosine similarity between EEG and audio features and also explore direct inference of the attended speaker using EEG data. Cross-trial evaluations results demonstrate that SincAlignNet outperforms state-of-the-art AAD methods on two publicly available datasets, KUL and DTU, achieving average accuracies of 78.3% and 92.2%, respectively, with a 1-second decision window. The model exhibits strong interpretability, revealing that the left and right temporal lobes are more active during both male and female speaker scenarios. Furthermore, we found that using data from only six electrodes near the temporal lobes maintains similar or even better performance compared to using 64 electrodes. These findings indicate that efficient low-density EEG online decoding is achievable, marking an important step toward the practical implementation of neuro-guided hearing aids in real-world applications. Code is available at: https://github.com/LiaoEuan/SincAlignNet.
Storyfier: Exploring Vocabulary Learning Support with Text Generation Models
Aug 07, 2023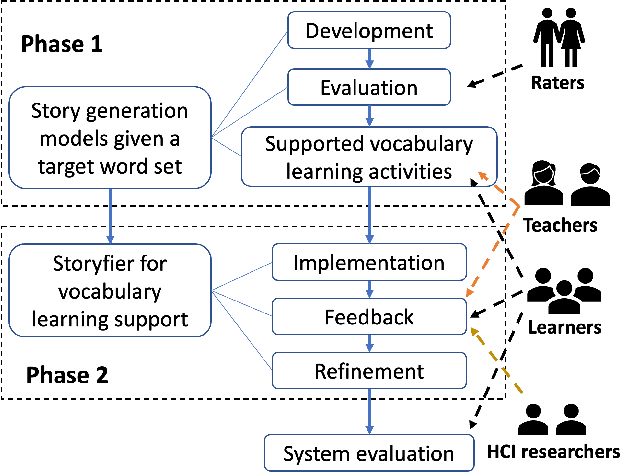
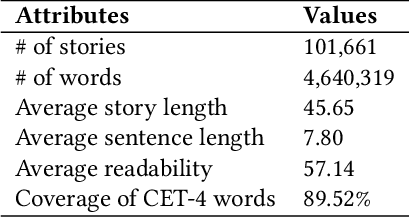
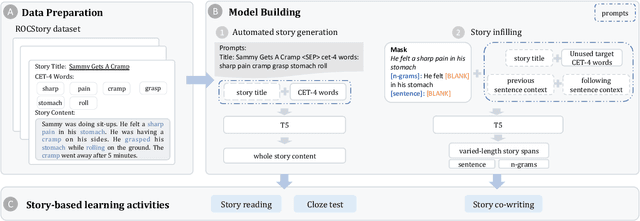

Vocabulary learning support tools have widely exploited existing materials, e.g., stories or video clips, as contexts to help users memorize each target word. However, these tools could not provide a coherent context for any target words of learners' interests, and they seldom help practice word usage. In this paper, we work with teachers and students to iteratively develop Storyfier, which leverages text generation models to enable learners to read a generated story that covers any target words, conduct a story cloze test, and use these words to write a new story with adaptive AI assistance. Our within-subjects study (N=28) shows that learners generally favor the generated stories for connecting target words and writing assistance for easing their learning workload. However, in the read-cloze-write learning sessions, participants using Storyfier perform worse in recalling and using target words than learning with a baseline tool without our AI features. We discuss insights into supporting learning tasks with generative models.