 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Step Distillation for Text-to-Image Generation: A Practical Guide
Dec 15, 2025Diffusion distillation has dramatically accelerated class-conditional image synthesis, but its applicability to open-ended text-to-image (T2I) generation is still unclear. We present the first systematic study that adapts and compares state-of-the-art distillation techniques on a strong T2I teacher model, FLUX.1-lite. By casting existing methods into a unified framework, we identify the key obstacles that arise when moving from discrete class labels to free-form language prompts. Beyond a thorough methodological analysis, we offer practical guidelines on input scaling, network architecture, and hyperparameters, accompanied by an open-source implementation and pretrained student models. Our findings establish a solid foundation for deploying fast, high-fidelity, and resource-efficient diffusion generators in real-world T2I applications. Code is available on github.com/alibaba-damo-academy/T2I-Distill.
RAPID^3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformer
Sep 26, 2025Diffusion Transformers (DiTs) excel at visual generation yet remain hampered by slow sampling. Existing training-free accelerators - step reduction, feature caching, and sparse attention - enhance inference speed but typically rely on a uniform heuristic or a manually designed adaptive strategy for all images, leaving quality on the table. Alternatively, dynamic neural networks offer per-image adaptive acceleration, but their high fine-tuning costs limit broader applicability. To address these limitations, we introduce RAPID3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformers, a framework that delivers image-wise acceleration with zero updates to the base generator. Specifically, three lightweight policy heads - Step-Skip, Cache-Reuse, and Sparse-Attention - observe the current denoising state and independently decide their corresponding speed-up at each timestep. All policy parameters are trained online via Group Relative Policy Optimization (GRPO) while the generator remains frozen. Meanwhile, an adversarially learned discriminator augments the reward signal, discouraging reward hacking by boosting returns only when generated samples stay close to the original model's distribution. Across state-of-the-art DiT backbones, including Stable Diffusion 3 and FLUX, RAPID3 achieves nearly 3x faster sampling with competitive generation quality.
Diffusion Sampling Path Tells More: An Efficient Plug-and-Play Strategy for Sample Filtering
May 29, 2025Diffusion models often exhibit inconsistent sample quality due to stochastic variations inherent in their sampling trajectories. Although training-based fine-tuning (e.g. DDPO [1]) and inference-time alignment techniques[2] aim to improve sample fidelity, they typically necessitate full denoising processes and external reward signals. This incurs substantial computational costs, hindering their broader applicability. In this work, we unveil an intriguing phenomenon: a previously unobserved yet exploitable link between sample quality and characteristics of the denoising trajectory during classifier-free guidance (CFG). Specifically, we identify a strong correlation between high-density regions of the sample distribution and the Accumulated Score Differences (ASD)--the cumulative divergence between conditional and unconditional scores. Leveraging this insight, we introduce CFG-Rejection, an efficient, plug-and-play strategy that filters low-quality samples at an early stage of the denoising process, crucially without requiring external reward signals or model retraining. Importantly, our approach necessitates no modifications to model architectures or sampling schedules and maintains full compatibility with existing diffusion frameworks. We validate the effectiveness of CFG-Rejection in image generation through extensive experiments, demonstrating marked improvements on human preference scores (HPSv2, PickScore) and challenging benchmarks (GenEval, DPG-Bench). We anticipate that CFG-Rejection will offer significant advantages for diverse generative modalities beyond images, paving the way for more efficient and reliable high-quality sample generation.
Safeguarding Text-to-Image Generation via Inference-Time Prompt-Noise Optimization
Dec 05, 2024



Text-to-Image (T2I) diffusion models are widely recognized for their ability to generate high-quality and diverse images based on text prompts. However, despite recent advances, these models are still prone to generating unsafe images containing sensitive or inappropriate content, which can be harmful to users. Current efforts to prevent inappropriate image generation for diffusion models are easy to bypass and vulnerable to adversarial attacks. How to ensure that T2I models align with specific safety goals remains a significant challenge. In this work, we propose a novel, training-free approach, called Prompt-Noise Optimization (PNO), to mitigate unsafe image generation. Our method introduces a novel optimization framework that leverages both the continuous prompt embedding and the injected noise trajectory in the sampling process to generate safe images. Extensive numerical results demonstrate that our framework achieves state-of-the-art performance in suppressing toxic image generations and demonstrates robustness to adversarial attacks, without needing to tune the model parameters. Furthermore, compared with existing methods, PNO uses comparable generation time while offering the best tradeoff between the conflicting goals of safe generation and prompt-image alignment.
Tuning-Free Alignment of Diffusion Models with Direct Noise Optimization
May 29, 2024In this work, we focus on the alignment problem of diffusion models with a continuous reward function, which represents specific objectives for downstream tasks, such as improving human preference. The central goal of the alignment problem is to adjust the distribution learned by diffusion models such that the generated samples maximize the target reward function. We propose a novel alignment approach, named Direct Noise Optimization (DNO), that optimizes the injected noise during the sampling process of diffusion models. By design, DNO is tuning-free and prompt-agnostic, as the alignment occurs in an online fashion during generation. We rigorously study the theoretical properties of DNO and also propose variants to deal with non-differentiable reward functions. Furthermore, we identify that naive implementation of DNO occasionally suffers from the out-of-distribution reward hacking problem, where optimized samples have high rewards but are no longer in the support of the pretrained distribution. To remedy this issue, we leverage classical high-dimensional statistics theory and propose to augment the DNO loss with certain probability regularization. We conduct extensive experiments on several popular reward functions trained on human feedback data and demonstrate that the proposed DNO approach achieves state-of-the-art reward scores as well as high image quality, all within a reasonable time budget for generation.
FedLion: Faster Adaptive Federated Optimization with Fewer Communication
Feb 15, 2024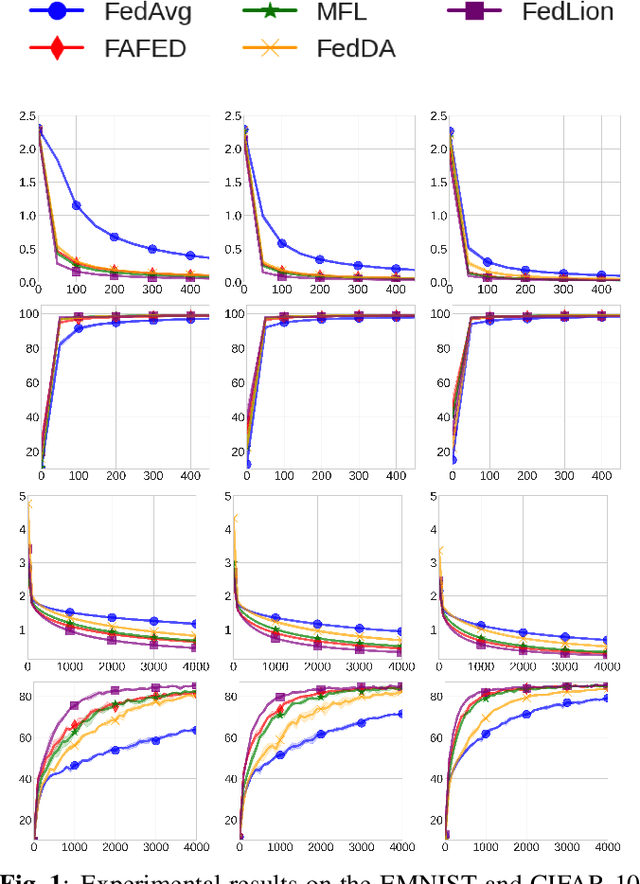
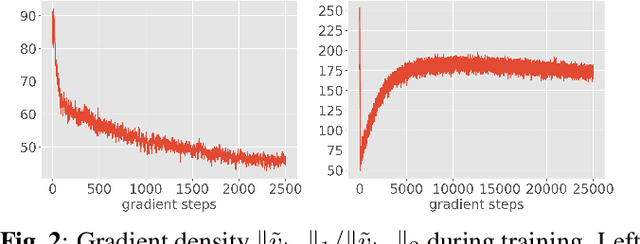
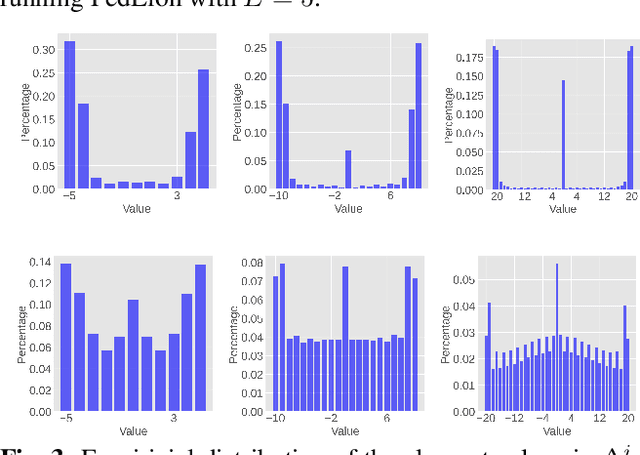
In Federated Learning (FL), a framework to train machine learning models across distributed data, well-known algorithms like FedAvg tend to have slow convergence rates, resulting in high communication costs during training. To address this challenge, we introduce FedLion, an adaptive federated optimization algorithm that seamlessly incorporates key elements from the recently proposed centralized adaptive algorithm, Lion (Chen et al. 2o23), into the FL framework. Through comprehensive evaluations on two widely adopted FL benchmarks, we demonstrate that FedLion outperforms previous state-of-the-art adaptive algorithms, including FAFED (Wu et al. 2023) and FedDA. Moreover, thanks to the use of signed gradients in local training, FedLion substantially reduces data transmission requirements during uplink communication when compared to existing adaptive algorithms, further reducing communication costs. Last but not least, this work also includes a novel theoretical analysis, showcasing that FedLion attains faster convergence rate than established FL algorithms like FedAvg.
Accelerating Parallel Sampling of Diffusion Models
Feb 15, 2024



Diffusion models have emerged as state-of-the-art generative models for image generation. However, sampling from diffusion models is usually time-consuming due to the inherent autoregressive nature of their sampling process. In this work, we propose a novel approach that accelerates the sampling of diffusion models by parallelizing the autoregressive process. Specifically, we reformulate the sampling process as solving a system of triangular nonlinear equations through fixed-point iteration. With this innovative formulation, we explore several systematic techniques to further reduce the iteration steps required by the solving process. Applying these techniques, we introduce ParaTAA, a universal and training-free parallel sampling algorithm that can leverage extra computational and memory resources to increase the sampling speed. Our experiments demonstrate that ParaTAA can decrease the inference steps required by common sequential sampling algorithms such as DDIM and DDPM by a factor of 4~14 times. Notably, when applying ParaTAA with 100 steps DDIM for Stable Diffusion, a widely-used text-to-image diffusion model, it can produce the same images as the sequential sampling in only 7 inference steps.
Zeroth-Order Optimization Meets Human Feedback: Provable Learning via Ranking Oracles
Mar 07, 2023
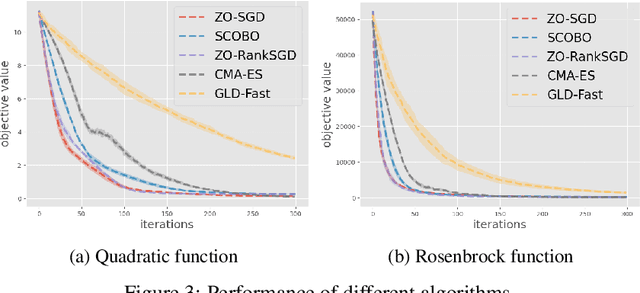

In this paper, we focus on a novel optimization problem in which the objective function is a black-box and can only be evaluated through a ranking oracle. This problem is common in real-world applications, particularly in cases where the function is assessed by human judges. Reinforcement Learning with Human Feedback (RLHF) is a prominent example of such an application, which is adopted by the recent works \cite{ouyang2022training,liu2023languages,chatgpt,bai2022training} to improve the quality of Large Language Models (LLMs) with human guidance. We propose ZO-RankSGD, a first-of-its-kind zeroth-order optimization algorithm, to solve this optimization problem with a theoretical guarantee. Specifically, our algorithm employs a new rank-based random estimator for the descent direction and is proven to converge to a stationary point. ZO-RankSGD can also be directly applied to the policy search problem in reinforcement learning when only a ranking oracle of the episode reward is available. This makes ZO-RankSGD a promising alternative to existing RLHF methods, as it optimizes in an online fashion and thus can work without any pre-collected data. Furthermore, we demonstrate the effectiveness of ZO-RankSGD in a novel application: improving the quality of images generated by a diffusion generative model with human ranking feedback. Throughout experiments, we found that ZO-RankSGD can significantly enhance the detail of generated images with only a few rounds of human feedback. Overall, our work advances the field of zeroth-order optimization by addressing the problem of optimizing functions with only ranking feedback, and offers an effective approach for aligning human and machine intentions in a wide range of domains. Our code is released here \url{https://github.com/TZW1998/Taming-Stable-Diffusion-with-Human-Ranking-Feedback}.
$z$-SignFedAvg: A Unified Stochastic Sign-based Compression for Federated Learning
Feb 06, 2023
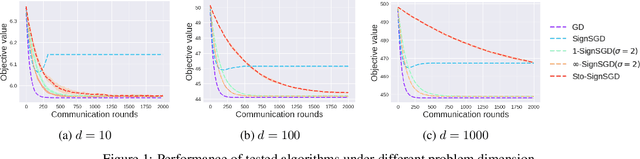
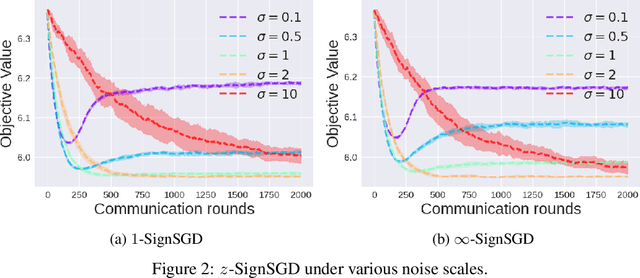

Federated Learning (FL) is a promising privacy-preserving distributed learning paradigm but suffers from high communication cost when training large-scale machine learning models. Sign-based methods, such as SignSGD \cite{bernstein2018signsgd}, have been proposed as a biased gradient compression technique for reducing the communication cost. However, sign-based algorithms could diverge under heterogeneous data, which thus motivated the development of advanced techniques, such as the error-feedback method and stochastic sign-based compression, to fix this issue. Nevertheless, these methods still suffer from slower convergence rates. Besides, none of them allows multiple local SGD updates like FedAvg \cite{mcmahan2017communication}. In this paper, we propose a novel noisy perturbation scheme with a general symmetric noise distribution for sign-based compression, which not only allows one to flexibly control the tradeoff between gradient bias and convergence performance, but also provides a unified viewpoint to existing stochastic sign-based methods. More importantly, the unified noisy perturbation scheme enables the development of the very first sign-based FedAvg algorithm ($z$-SignFedAvg) to accelerate the convergence. Theoretically, we show that $z$-SignFedAvg achieves a faster convergence rate than existing sign-based methods and, under the uniformly distributed noise, can enjoy the same convergence rate as its uncompressed counterpart. Extensive experiments are conducted to demonstrate that the $z$-SignFedAvg can achieve competitive empirical performance on real datasets and outperforms existing schemes.
Low-rank Matrix Recovery With Unknown Correspondence
Oct 18, 2021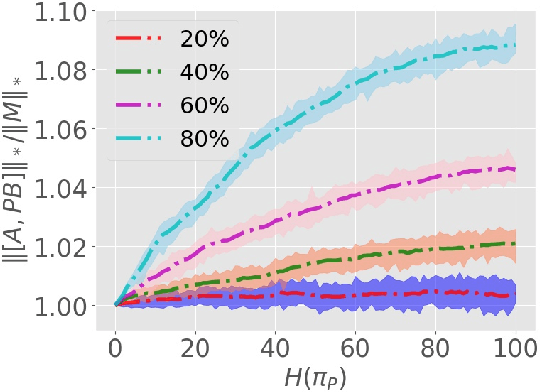

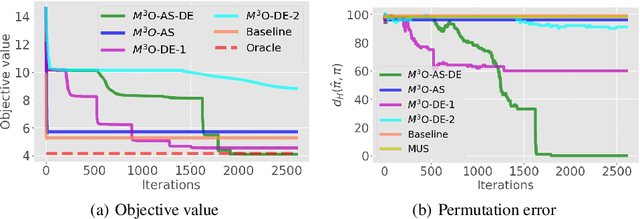
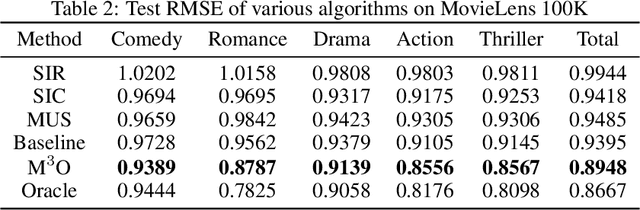
We study a matrix recovery problem with unknown correspondence: given the observation matrix $M_o=[A,\tilde P B]$, where $\tilde P$ is an unknown permutation matrix, we aim to recover the underlying matrix $M=[A,B]$. Such problem commonly arises in many applications where heterogeneous data are utilized and the correspondence among them are unknown, e.g., due to privacy concerns. We show that it is possible to recover $M$ via solving a nuclear norm minimization problem under a proper low-rank condition on $M$, with provable non-asymptotic error bound for the recovery of $M$. We propose an algorithm, $\text{M}^3\text{O}$ (Matrix recovery via Min-Max Optimization) which recasts this combinatorial problem as a continuous minimax optimization problem and solves it by proximal gradient with a Max-Oracle. $\text{M}^3\text{O}$ can also be applied to a more general scenario where we have missing entries in $M_o$ and multiple groups of data with distinct unknown correspondence. Experiments on simulated data, the MovieLens 100K dataset and Yale B database show that $\text{M}^3\text{O}$ achieves state-of-the-art performance over several baselines and can recover the ground-truth correspondence with high accuracy.