 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth-Order Optimization Meets Human Feedback: Provable Learning via Ranking Oracles
Paper and Code

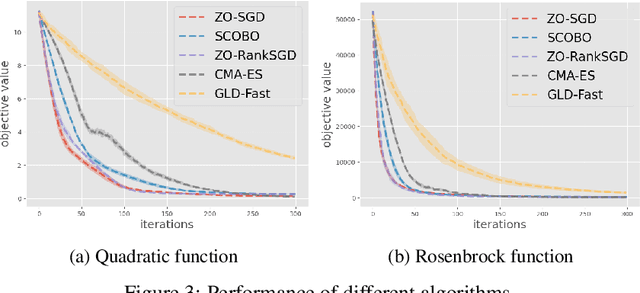

In this paper, we focus on a novel optimization problem in which the objective function is a black-box and can only be evaluated through a ranking oracle. This problem is common in real-world applications, particularly in cases where the function is assessed by human judges. Reinforcement Learning with Human Feedback (RLHF) is a prominent example of such an application, which is adopted by the recent works \cite{ouyang2022training,liu2023languages,chatgpt,bai2022training} to improve the quality of Large Language Models (LLMs) with human guidance. We propose ZO-RankSGD, a first-of-its-kind zeroth-order optimization algorithm, to solve this optimization problem with a theoretical guarantee. Specifically, our algorithm employs a new rank-based random estimator for the descent direction and is proven to converge to a stationary point. ZO-RankSGD can also be directly applied to the policy search problem in reinforcement learning when only a ranking oracle of the episode reward is available. This makes ZO-RankSGD a promising alternative to existing RLHF methods, as it optimizes in an online fashion and thus can work without any pre-collected data. Furthermore, we demonstrate the effectiveness of ZO-RankSGD in a novel application: improving the quality of images generated by a diffusion generative model with human ranking feedback. Throughout experiments, we found that ZO-RankSGD can significantly enhance the detail of generated images with only a few rounds of human feedback. Overall, our work advances the field of zeroth-order optimization by addressing the problem of optimizing functions with only ranking feedback, and offers an effective approach for aligning human and machine intentions in a wide range of domains. Our code is released here \url{https://github.com/TZW1998/Taming-Stable-Diffusion-with-Human-Ranking-Feedback}.