 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: Activation-Space Tail-Eigenvector Low-Rank Adaptation of Large Language Models
Feb 22, 2026Parameter-Efficient Fine-Tuning (PEFT) methods, especially LoRA, are widely used for adapting pre-trained models to downstream tasks due to their computational and storage efficiency. However, in the context of LoRA and its variants, the potential of activation subspaces corresponding to tail eigenvectors remains substantially under-exploited, which may lead to suboptimal fine-tuning performance. In this work, we propose Astra (Activation-Space Tail-Eigenvector Low-Rank Adaptation), a novel PEFT method that leverages the tail eigenvectors of the model output activations-estimated from a small task-specific calibration set-to construct task-adaptive low-rank adapters. By constraining updates to the subspace spanned by these tail eigenvectors, Astra achieves faster convergence and improved downstream performance with a significantly reduced parameter budget. Extensive experiments across natural language understanding (NLU) and natural language generation (NLG) tasks demonstrate that Astra consistently outperforms existing PEFT baselines across 16 benchmarks and even surpasses full fine-tuning (FFT) in certain scenarios.
Rethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry
Jan 30, 2026Large language models (LLMs) are widely used as reference-free evaluators via prompting, but this "LLM-as-a-Judge" paradigm is costly, opaque, and sensitive to prompt design. In this work, we investigate whether smaller models can serve as efficient evaluators by leveraging internal representations instead of surface generation. We uncover a consistent empirical pattern: small LMs, despite with weak generative ability, encode rich evaluative signals in their hidden states. This motivates us to propose the Semantic Capacity Asymmetry Hypothesis: evaluation requires significantly less semantic capacity than generation and can be grounded in intermediate representations, suggesting that evaluation does not necessarily need to rely on large-scale generative models but can instead leverage latent features from smaller ones. Our findings motivate a paradigm shift from LLM-as-a-Judge to Representation-as-a-Judge, a decoding-free evaluation strategy that probes internal model structure rather than relying on prompted output. We instantiate this paradigm through INSPECTOR, a probing-based framework that predicts aspect-level evaluation scores from small model representations. Experiments on reasoning benchmarks (GSM8K, MATH, GPQA) show that INSPECTOR substantially outperforms prompting-based small LMs and closely approximates full LLM judges, while offering a more efficient, reliable, and interpretable alternative for scalable evaluation.
SSPO: Subsentence-level Policy Optimization
Nov 06, 2025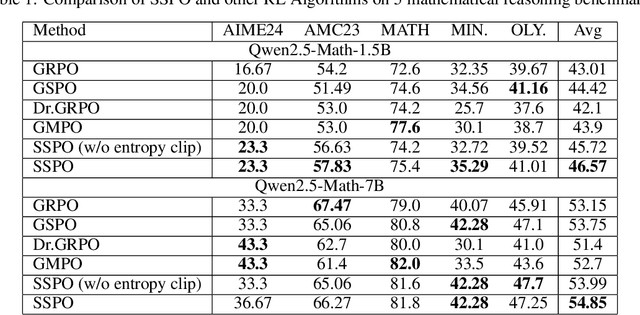
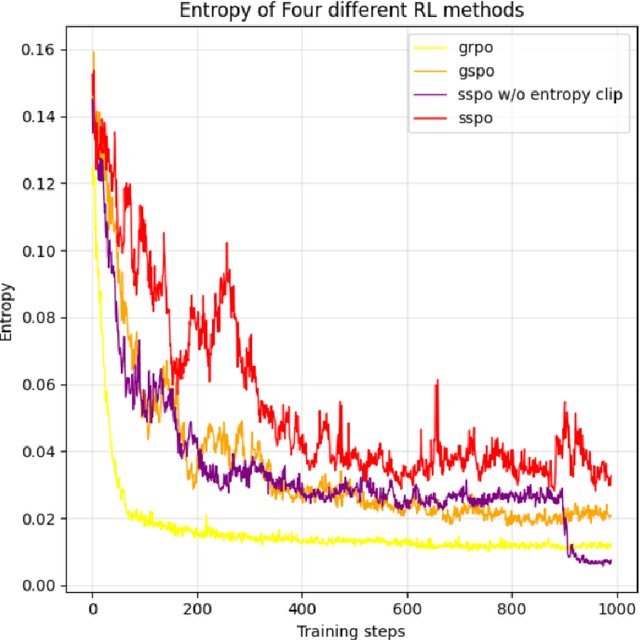
As a significant part of post-training of the Large Language Models (LLMs), Reinforcement Learning from Verifiable Reward (RLVR) has greatly improved LLMs' reasoning skills. However, some RLVR algorithms, such as GRPO (Group Relative Policy Optimization) and GSPO (Group Sequence Policy Optimization), are observed to suffer from unstable policy updates and low usage of sampling data, respectively. The importance ratio of GRPO is calculated at the token level, which focuses more on optimizing a single token. This will be easily affected by outliers, leading to model training collapse. GSPO proposed the calculation of the response level importance ratio, which solves the problem of high variance and training noise accumulation in the calculation of the GRPO importance ratio. However, since all the response tokens share a common importance ratio, extreme values can easily raise or lower the overall mean, leading to the entire response being mistakenly discarded, resulting in a decrease in the utilization of sampled data. This paper introduces SSPO, which applies sentence-level importance ratio, taking the balance between GRPO and GSPO. SSPO not only avoids training collapse and high variance, but also prevents the whole response tokens from being abandoned by the clipping mechanism. Furthermore, we apply sentence entropy to PPO-CLIP to steadily adjust the clipping bounds, encouraging high-entropy tokens to explore and narrow the clipping range of low-entropy tokens. In particular, SSPO achieves an average score of 46.57 across five datasets, surpassing GRPO (43.01) and GSPO (44.42), and wins state-of-the-art performance on three datasets. These results highlight SSPO's effectiveness in leveraging generated data by taking the essence of GSPO but rejecting its shortcomings.
Selecting Demonstrations for Many-Shot In-Context Learning via Gradient Matching
Jun 05, 2025



In-Context Learning (ICL) empowers Large Language Models (LLMs) for rapid task adaptation without Fine-Tuning (FT), but its reliance on demonstration selection remains a critical challenge. While many-shot ICL shows promising performance through scaled demonstrations, the selection method for many-shot demonstrations remains limited to random selection in existing work. Since the conventional instance-level retrieval is not suitable for many-shot scenarios, we hypothesize that the data requirements for in-context learning and fine-tuning are analogous. To this end, we introduce a novel gradient matching approach that selects demonstrations by aligning fine-tuning gradients between the entire training set of the target task and the selected examples, so as to approach the learning effect on the entire training set within the selected examples. Through gradient matching on relatively small models, e.g., Qwen2.5-3B or Llama3-8B, our method consistently outperforms random selection on larger LLMs from 4-shot to 128-shot scenarios across 9 diverse datasets. For instance, it surpasses random selection by 4% on Qwen2.5-72B and Llama3-70B, and by around 2% on 5 closed-source LLMs. This work unlocks more reliable and effective many-shot ICL, paving the way for its broader application.
Sentinel: Attention Probing of Proxy Models for LLM Context Compression with an Understanding Perspective
May 29, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with external context, but retrieved passages are often lengthy, noisy, or exceed input limits. Existing compression methods typically require supervised training of dedicated compression models, increasing cost and reducing portability. We propose Sentinel, a lightweight sentence-level compression framework that reframes context filtering as an attention-based understanding task. Rather than training a compression model, Sentinel probes decoder attention from an off-the-shelf 0.5B proxy LLM using a lightweight classifier to identify sentence relevance. Empirically, we find that query-context relevance estimation is consistent across model scales, with 0.5B proxies closely matching the behaviors of larger models. On the LongBench benchmark, Sentinel achieves up to 5$\times$ compression while matching the QA performance of 7B-scale compression systems. Our results suggest that probing native attention signals enables fast, effective, and question-aware context compression. Code available at: https://github.com/yzhangchuck/Sentinel.
Robust Federated Learning in Unreliable Wireless Networks: A Client Selection Approach
Feb 26, 2025Federated learning (FL) has emerged as a promising distributed learning paradigm for training deep neural networks (DNNs) at the wireless edge, but its performance can be severely hindered by unreliable wireless transmission and inherent data heterogeneity among clients. Existing solutions primarily address these challenges by incorporating wireless resource optimization strategies, often focusing on uplink resource allocation across clients under the assumption of homogeneous client-server network standards. However, these approaches overlooked the fact that mobile clients may connect to the server via diverse network standards (e.g., 4G, 5G, Wi-Fi) with customized configurations, limiting the flexibility of server-side modifications and restricting applicability in real-world commercial networks. This paper presents a novel theoretical analysis about how transmission failures in unreliable networks distort the effective label distributions of local samples, causing deviations from the global data distribution and introducing convergence bias in FL. Our analysis reveals that a carefully designed client selection strategy can mitigate biases induced by network unreliability and data heterogeneity. Motivated by this insight, we propose FedCote, a client selection approach that optimizes client selection probabilities without relying on wireless resource scheduling. Experimental results demonstrate the robustness of FedCote in DNN-based classification tasks under unreliable networks with frequent transmission failures.
Disentangling Preference Representation and Text Generation for Efficient Individual Preference Alignment
Dec 30, 2024Aligning Large Language Models (LLMs) with general human preferences has been proved crucial in improving the interaction quality between LLMs and human. However, human values are inherently diverse among different individuals, making it insufficient to align LLMs solely with general preferences. To address this, personalizing LLMs according to individual feedback emerges as a promising solution. Nonetheless, this approach presents challenges in terms of the efficiency of alignment algorithms. In this work, we introduce a flexible paradigm for individual preference alignment. Our method fundamentally improves efficiency by disentangling preference representation from text generation in LLMs. We validate our approach across multiple text generation tasks and demonstrate that it can produce aligned quality as well as or better than PEFT-based methods, while reducing additional training time for each new individual preference by $80\%$ to $90\%$ in comparison with them.
Learning to Adapt to Low-Resource Paraphrase Generation
Dec 22, 2024Paraphrase generation is a longstanding NLP task and achieves great success with the aid of large corpora. However, transferring a paraphrasing model to another domain encounters the problem of domain shifting especially when the data is sparse. At the same time, widely using large pre-trained language models (PLMs) faces the overfitting problem when training on scarce labeled data. To mitigate these two issues, we propose, LAPA, an effective adapter for PLMs optimized by meta-learning. LAPA has three-stage training on three types of related resources to solve this problem: 1. pre-training PLMs on unsupervised corpora, 2. inserting an adapter layer and meta-training on source domain labeled data, and 3. fine-tuning adapters on a small amount of target domain labeled data. This method enables paraphrase generation models to learn basic language knowledge first, then learn the paraphrasing task itself later, and finally adapt to the target task. Our experimental results demonstrate that LAPA achieves state-of-the-art in supervised, unsupervised, and low-resource settings on three benchmark datasets. With only 2\% of trainable parameters and 1\% labeled data of the target task, our approach can achieve a competitive performance with previous work.
Planning with Large Language Models for Conversational Agents
Jul 04, 2024Controllability and proactivity are crucial properties of autonomous conversational agents (CAs). Controllability requires the CAs to follow the standard operating procedures (SOPs), such as verifying identity before activating credit cards. Proactivity requires the CAs to guide the conversation towards the goal during user uncooperation, such as persuasive dialogue. Existing research cannot be unified with controllability, proactivity, and low manual annotation. To bridge this gap, we propose a new framework for planning-based conversational agents (PCA) powered by large language models (LLMs), which only requires humans to define tasks and goals for the LLMs. Before conversation, LLM plans the core and necessary SOP for dialogue offline. During the conversation, LLM plans the best action path online referring to the SOP, and generates responses to achieve process controllability. Subsequently, we propose a semi-automatic dialogue data creation framework and curate a high-quality dialogue dataset (PCA-D). Meanwhile, we develop multiple variants and evaluation metrics for PCA, e.g., planning with Monte Carlo Tree Search (PCA-M), which searches for the optimal dialogue action while satisfying SOP constraints and achieving the proactive of the dialogue. Experiment results show that LLMs finetuned on PCA-D can significantly improve the performance and generalize to unseen domains. PCA-M outperforms other CoT and ToT baselines in terms of conversation controllability, proactivity, task success rate, and overall logical coherence, and is applicable in industry dialogue scenarios. The dataset and codes are available at XXXX.
$z$-SignFedAvg: A Unified Stochastic Sign-based Compression for Federated Learning
Feb 06, 2023
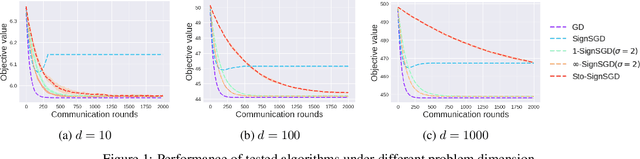
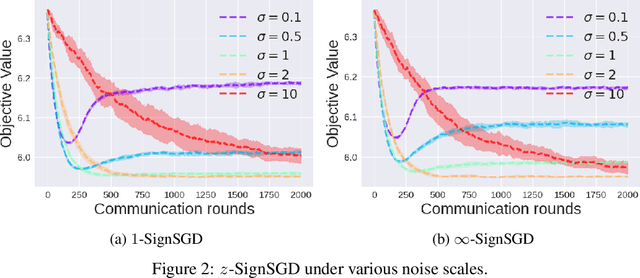

Federated Learning (FL) is a promising privacy-preserving distributed learning paradigm but suffers from high communication cost when training large-scale machine learning models. Sign-based methods, such as SignSGD \cite{bernstein2018signsgd}, have been proposed as a biased gradient compression technique for reducing the communication cost. However, sign-based algorithms could diverge under heterogeneous data, which thus motivated the development of advanced techniques, such as the error-feedback method and stochastic sign-based compression, to fix this issue. Nevertheless, these methods still suffer from slower convergence rates. Besides, none of them allows multiple local SGD updates like FedAvg \cite{mcmahan2017communication}. In this paper, we propose a novel noisy perturbation scheme with a general symmetric noise distribution for sign-based compression, which not only allows one to flexibly control the tradeoff between gradient bias and convergence performance, but also provides a unified viewpoint to existing stochastic sign-based methods. More importantly, the unified noisy perturbation scheme enables the development of the very first sign-based FedAvg algorithm ($z$-SignFedAvg) to accelerate the convergence. Theoretically, we show that $z$-SignFedAvg achieves a faster convergence rate than existing sign-based methods and, under the uniformly distributed noise, can enjoy the same convergence rate as its uncompressed counterpart. Extensive experiments are conducted to demonstrate that the $z$-SignFedAvg can achieve competitive empirical performance on real datasets and outperforms existing schemes.