 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIR: Enhanced Image Representations for Medical Report Generation
Dec 29, 2025Generating medical reports from chest X-ray images is a critical and time-consuming task for radiologists, especially in emergencies. To alleviate the stress on radiologists and reduce the risk of misdiagnosis, numerous research efforts have been dedicated to automatic medical report generation in recent years. Most recent studies have developed methods that represent images by utilizing various medical metadata, such as the clinical document history of the current patient and the medical graphs constructed from retrieved reports of other similar patients. However, all existing methods integrate additional metadata representations with visual representations through a simple "Add and LayerNorm" operation, which suffers from the information asymmetry problem due to the distinct distributions between them. In addition, chest X-ray images are usually represented using pre-trained models based on natural domain images, which exhibit an obvious domain gap between general and medical domain images. To this end, we propose a novel approach called Enhanced Image Representations (EIR) for generating accurate chest X-ray reports. We utilize cross-modal transformers to fuse metadata representations with image representations, thereby effectively addressing the information asymmetry problem between them, and we leverage medical domain pre-trained models to encode medical images, effectively bridging the domain gap for image representation. Experimental results on the widely used MIMIC and Open-I datasets demonstrate the effectiveness of our proposed method.
Bridging the Gap: Deciphering Tabular Data Using Large Language Model
Aug 28, 2023In the realm of natural language processing, the understanding of tabular data has perpetually stood as a focal point of scholarly inquiry. The emergence of expansive language models, exemplified by the likes of ChatGPT, has ushered in a wave of endeavors wherein researchers aim to harness these models for tasks related to table-based question answering. Central to our investigative pursuits is the elucidation of methodologies that amplify the aptitude of such large language models in discerning both the structural intricacies and inherent content of tables, ultimately facilitating their capacity to provide informed responses to pertinent queries. To this end, we have architected a distinctive module dedicated to the serialization of tables for seamless integration with expansive language models. Additionally, we've instituted a corrective mechanism within the model to rectify potential inaccuracies. Experimental results indicate that, although our proposed method trails the SOTA by approximately 11.7% in overall metrics, it surpasses the SOTA by about 1.2% in tests on specific datasets. This research marks the first application of large language models to table-based question answering tasks, enhancing the model's comprehension of both table structures and content.
Enhancing Dual-Encoders with Question and Answer Cross-Embeddings for Answer Retrieval
Jun 07, 2022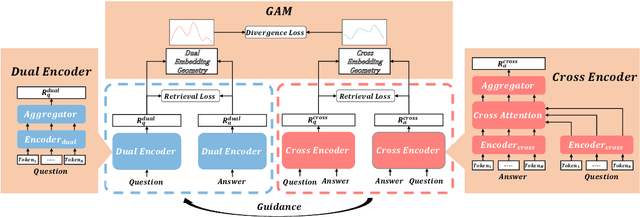

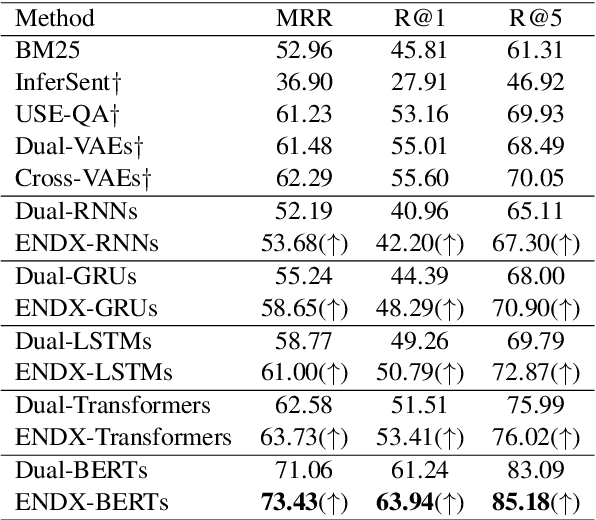
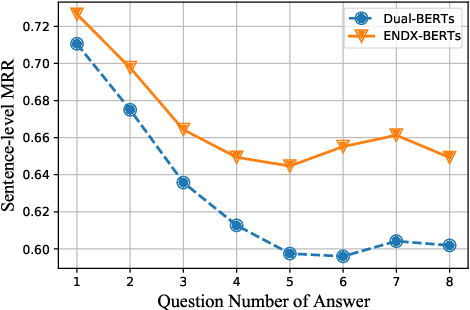
Dual-Encoders is a promising mechanism for answer retrieval in question answering (QA) systems. Currently most conventional Dual-Encoders learn the semantic representations of questions and answers merely through matching score. Researchers proposed to introduce the QA interaction features in scoring function but at the cost of low efficiency in inference stage. To keep independent encoding of questions and answers during inference stage, variational auto-encoder is further introduced to reconstruct answers (questions) from question (answer) embeddings as an auxiliary task to enhance QA interaction in representation learning in training stage. However, the needs of text generation and answer retrieval are different, which leads to hardness in training. In this work, we propose a framework to enhance the Dual-Encoders model with question answer cross-embeddings and a novel Geometry Alignment Mechanism (GAM) to align the geometry of embeddings from Dual-Encoders with that from Cross-Encoders. Extensive experimental results show that our framework significantly improves Dual-Encoders model and outperforms the state-of-the-art method on multiple answer retrieval datasets.
BERT-based Ranking for Biomedical Entity Normalization
Aug 09, 2019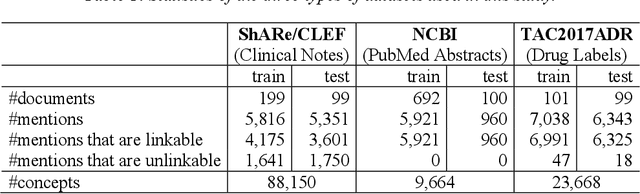
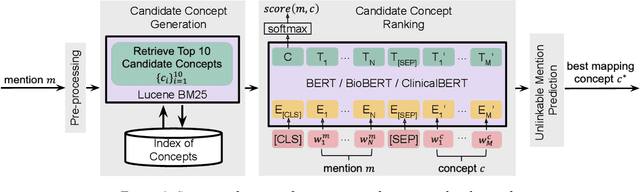
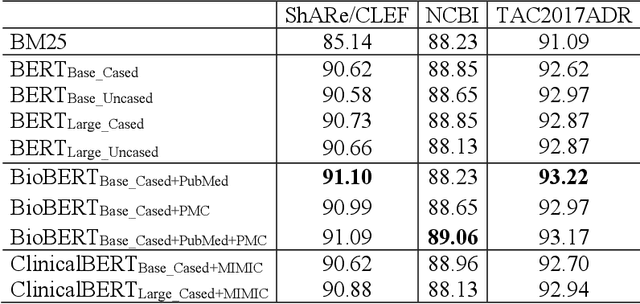
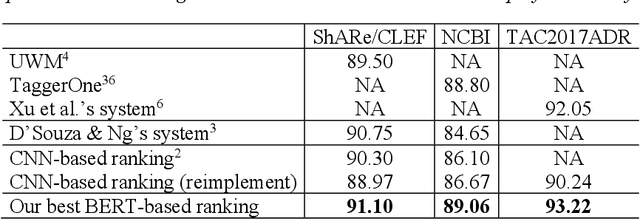
Developing high-performance entity normalization algorithms that can alleviate the term variation problem is of great interest to the biomedical community. Although deep learning-based methods have been successfully applied to biomedical entity normalization, they often depend on traditional context-independent word embeddings. Bidirectional Encoder Representations from Transformers (BERT), BERT for Biomedical Text Mining (BioBERT) and BERT for Clinical Text Mining (ClinicalBERT) were recently introduced to pre-train contextualized word representation models using bidirectional Transformers, advancing the state-of-the-art for many natural language processing tasks. In this study, we proposed an entity normalization architecture by fine-tuning the pre-trained BERT / BioBERT / ClinicalBERT models and conducted extensive experiments to evaluate the effectiveness of the pre-trained models for biomedical entity normalization using three different types of datasets. Our experimental results show that the best fine-tuned models consistently outperformed previous methods and advanced the state-of-the-art for biomedical entity normalization, with up to 1.17% increase in accuracy.
An Information Retrieval Approach to Short Text Conversation
Aug 29, 2014

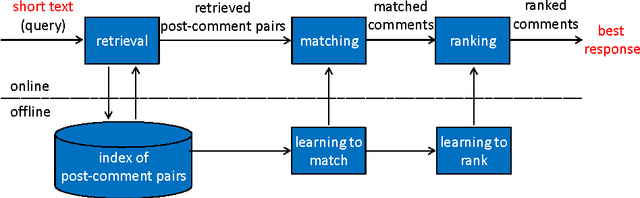
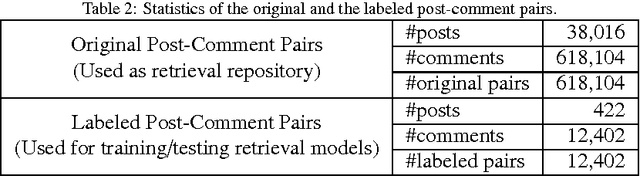
Human computer conversation is regarded as one of the most difficult problems in artificial intelligence. In this paper, we address one of its key sub-problems, referred to as short text conversation, in which given a message from human, the computer returns a reasonable response to the message. We leverage the vast amount of short conversation data available on social media to study the issue. We propose formalizing short text conversation as a search problem at the first step, and employing state-of-the-art information retrieval (IR) techniques to carry out the task. We investigate the significance as well as the limitation of the IR approach. Our experiments demonstrate that the retrieval-based model can make the system behave rather "intelligently", when combined with a huge repository of conversation data from social media.