 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeGaussian: High-Fidelity 4D Human Reconstruction in Monocular Videos via Vision Priors
Feb 05, 2026We introduce ShapeGaussian, a high-fidelity, template-free method for 4D human reconstruction from casual monocular videos. Generic reconstruction methods lacking robust vision priors, such as 4DGS, struggle to capture high-deformation human motion without multi-view cues. While template-based approaches, primarily relying on SMPL, such as HUGS, can produce photorealistic results, they are highly susceptible to errors in human pose estimation, often leading to unrealistic artifacts. In contrast, ShapeGaussian effectively integrates template-free vision priors to achieve both high-fidelity and robust scene reconstructions. Our method follows a two-step pipeline: first, we learn a coarse, deformable geometry using pretrained models that estimate data-driven priors, providing a foundation for reconstruction. Then, we refine this geometry using a neural deformation model to capture fine-grained dynamic details. By leveraging 2D vision priors, we mitigate artifacts from erroneous pose estimation in template-based methods and employ multiple reference frames to resolve the invisibility issue of 2D keypoints in a template-free manner. Extensive experiments demonstrate that ShapeGaussian surpasses template-based methods in reconstruction accuracy, achieving superior visual quality and robustness across diverse human motions in casual monocular videos.
EIR: Enhanced Image Representations for Medical Report Generation
Dec 29, 2025Generating medical reports from chest X-ray images is a critical and time-consuming task for radiologists, especially in emergencies. To alleviate the stress on radiologists and reduce the risk of misdiagnosis, numerous research efforts have been dedicated to automatic medical report generation in recent years. Most recent studies have developed methods that represent images by utilizing various medical metadata, such as the clinical document history of the current patient and the medical graphs constructed from retrieved reports of other similar patients. However, all existing methods integrate additional metadata representations with visual representations through a simple "Add and LayerNorm" operation, which suffers from the information asymmetry problem due to the distinct distributions between them. In addition, chest X-ray images are usually represented using pre-trained models based on natural domain images, which exhibit an obvious domain gap between general and medical domain images. To this end, we propose a novel approach called Enhanced Image Representations (EIR) for generating accurate chest X-ray reports. We utilize cross-modal transformers to fuse metadata representations with image representations, thereby effectively addressing the information asymmetry problem between them, and we leverage medical domain pre-trained models to encode medical images, effectively bridging the domain gap for image representation. Experimental results on the widely used MIMIC and Open-I datasets demonstrate the effectiveness of our proposed method.
COGNOS: Universal Enhancement for Time Series Anomaly Detection via Constrained Gaussian-Noise Optimization and Smoothing
Nov 10, 2025Reconstruction-based methods are a dominant paradigm in time series anomaly detection (TSAD), however, their near-universal reliance on Mean Squared Error (MSE) loss results in statistically flawed reconstruction residuals. This fundamental weakness leads to noisy, unstable anomaly scores with a poor signal-to-noise ratio, hindering reliable detection. To address this, we propose Constrained Gaussian-Noise Optimization and Smoothing (COGNOS), a universal, model-agnostic enhancement framework that tackles this issue at its source. COGNOS introduces a novel Gaussian-White Noise Regularization strategy during training, which directly constrains the model's output residuals to conform to a Gaussian white noise distribution. This engineered statistical property creates the ideal precondition for our second contribution: a Kalman Smoothing Post-processor that provably operates as a statistically optimal estimator to denoise the raw anomaly scores. The synergy between these two components allows COGNOS to robustly separate the true anomaly signal from random fluctuations. Extensive experiments demonstrate that COGNOS is highly effective, delivering an average F-score uplift of 57.9% when applied to 12 diverse backbone models across multiple real-world benchmark datasets. Our work reveals that directly regularizing output statistics is a powerful and generalizable strategy for significantly improving anomaly detection systems.
EasyGenNet: An Efficient Framework for Audio-Driven Gesture Video Generation Based on Diffusion Model
Apr 11, 2025Audio-driven cospeech video generation typically involves two stages: speech-to-gesture and gesture-to-video. While significant advances have been made in speech-to-gesture generation, synthesizing natural expressions and gestures remains challenging in gesture-to-video systems. In order to improve the generation effect, previous works adopted complex input and training strategies and required a large amount of data sets for pre-training, which brought inconvenience to practical applications. We propose a simple one-stage training method and a temporal inference method based on a diffusion model to synthesize realistic and continuous gesture videos without the need for additional training of temporal modules.The entire model makes use of existing pre-trained weights, and only a few thousand frames of data are needed for each character at a time to complete fine-tuning. Built upon the video generator, we introduce a new audio-to-video pipeline to synthesize co-speech videos, using 2D human skeleton as the intermediate motion representation. Our experiments show that our method outperforms existing GAN-based and diffusion-based methods.
Data-free Knowledge Distillation with Diffusion Models
Apr 01, 2025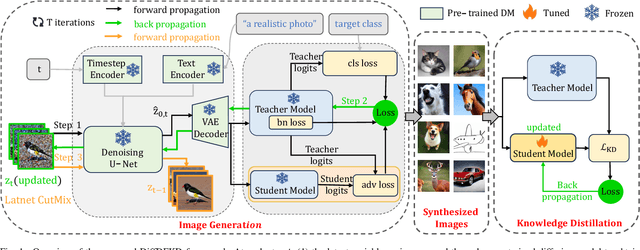
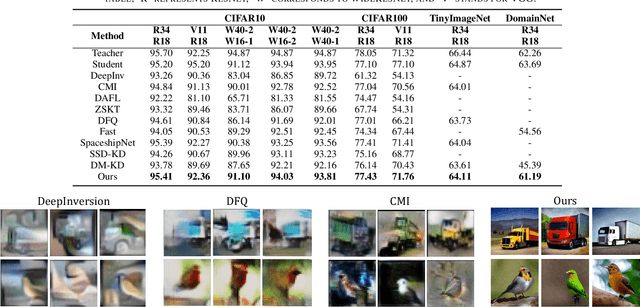
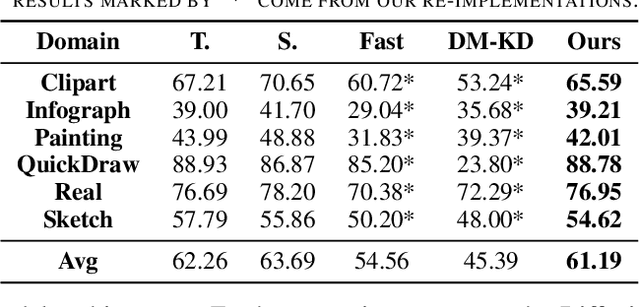

Recently Data-Free Knowledge Distillation (DFKD) has garnered attention and can transfer knowledge from a teacher neural network to a student neural network without requiring any access to training data. Although diffusion models are adept at synthesizing high-fidelity photorealistic images across various domains, existing methods cannot be easiliy implemented to DFKD. To bridge that gap, this paper proposes a novel approach based on diffusion models, DiffDFKD. Specifically, DiffDFKD involves targeted optimizations in two key areas. Firstly, DiffDFKD utilizes valuable information from teacher models to guide the pre-trained diffusion models' data synthesis, generating datasets that mirror the training data distribution and effectively bridge domain gaps. Secondly, to reduce computational burdens, DiffDFKD introduces Latent CutMix Augmentation, an efficient technique, to enhance the diversity of diffusion model-generated images for DFKD while preserving key attributes for effective knowledge transfer. Extensive experiments validate the efficacy of DiffDFKD, yielding state-of-the-art results exceeding existing DFKD approaches. We release our code at https://github.com/xhqi0109/DiffDFKD.
SyncDiff: Diffusion-based Talking Head Synthesis with Bottlenecked Temporal Visual Prior for Improved Synchronization
Mar 17, 2025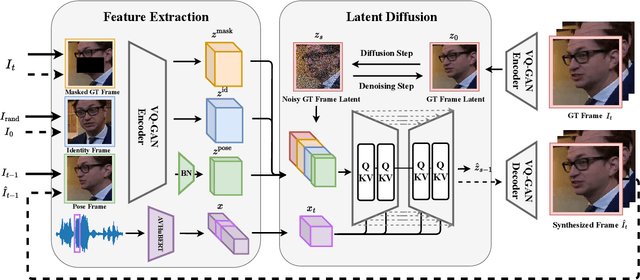
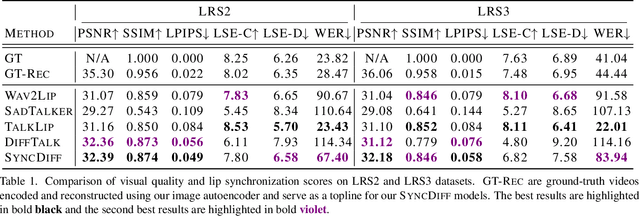
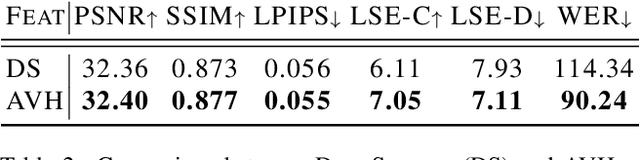
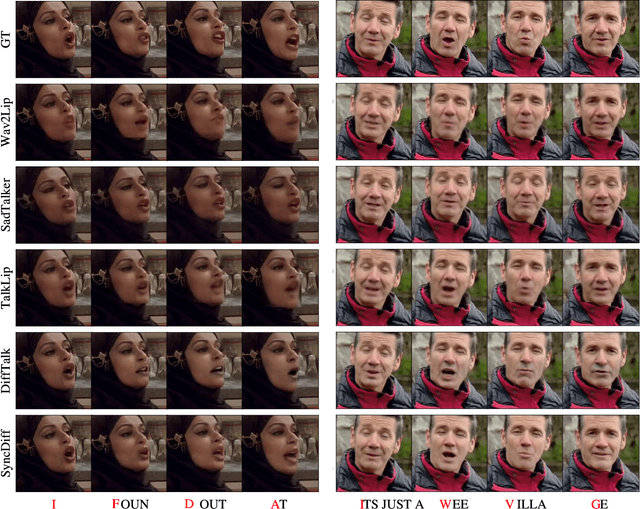
Talking head synthesis, also known as speech-to-lip synthesis, reconstructs the facial motions that align with the given audio tracks. The synthesized videos are evaluated on mainly two aspects, lip-speech synchronization and image fidelity. Recent studies demonstrate that GAN-based and diffusion-based models achieve state-of-the-art (SOTA) performance on this task, with diffusion-based models achieving superior image fidelity but experiencing lower synchronization compared to their GAN-based counterparts. To this end, we propose SyncDiff, a simple yet effective approach to improve diffusion-based models using a temporal pose frame with information bottleneck and facial-informative audio features extracted from AVHuBERT, as conditioning input into the diffusion process. We evaluate SyncDiff on two canonical talking head datasets, LRS2 and LRS3 for direct comparison with other SOTA models. Experiments on LRS2/LRS3 datasets show that SyncDiff achieves a synchronization score 27.7%/62.3% relatively higher than previous diffusion-based methods, while preserving their high-fidelity characteristics.
Bridging the Gap: Deciphering Tabular Data Using Large Language Model
Aug 28, 2023In the realm of natural language processing, the understanding of tabular data has perpetually stood as a focal point of scholarly inquiry. The emergence of expansive language models, exemplified by the likes of ChatGPT, has ushered in a wave of endeavors wherein researchers aim to harness these models for tasks related to table-based question answering. Central to our investigative pursuits is the elucidation of methodologies that amplify the aptitude of such large language models in discerning both the structural intricacies and inherent content of tables, ultimately facilitating their capacity to provide informed responses to pertinent queries. To this end, we have architected a distinctive module dedicated to the serialization of tables for seamless integration with expansive language models. Additionally, we've instituted a corrective mechanism within the model to rectify potential inaccuracies. Experimental results indicate that, although our proposed method trails the SOTA by approximately 11.7% in overall metrics, it surpasses the SOTA by about 1.2% in tests on specific datasets. This research marks the first application of large language models to table-based question answering tasks, enhancing the model's comprehension of both table structures and content.
A CTC Alignment-based Non-autoregressive Transformer for End-to-end Automatic Speech Recognition
Apr 15, 2023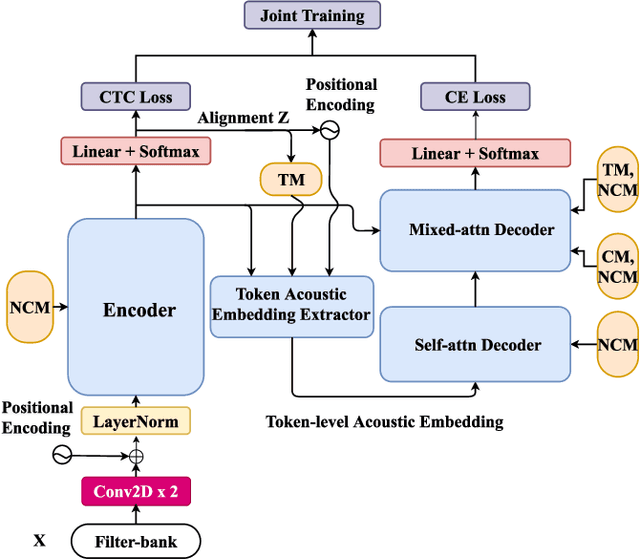



Recently, end-to-end models have been widely used in automatic speech recognition (ASR) systems. Two of the most representative approaches are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. Autoregressive transformers, variants of AED, adopt an autoregressive mechanism for token generation and thus are relatively slow during inference. In this paper, we present a comprehensive study of a CTC Alignment-based Single-Step Non-Autoregressive Transformer (CASS-NAT) for end-to-end ASR. In CASS-NAT, word embeddings in the autoregressive transformer (AT) are substituted with token-level acoustic embeddings (TAE) that are extracted from encoder outputs with the acoustical boundary information offered by the CTC alignment. TAE can be obtained in parallel, resulting in a parallel generation of output tokens. During training, Viterbi-alignment is used for TAE generation, and multiple training strategies are further explored to improve the word error rate (WER) performance. During inference, an error-based alignment sampling method is investigated in depth to reduce the alignment mismatch in the training and testing processes. Experimental results show that the CASS-NAT has a WER that is close to AT on various ASR tasks, while providing a ~24x inference speedup. With and without self-supervised learning, we achieve new state-of-the-art results for non-autoregressive models on several datasets. We also analyze the behavior of the CASS-NAT decoder to explain why it can perform similarly to AT. We find that TAEs have similar functionality to word embeddings for grammatical structures, which might indicate the possibility of learning some semantic information from TAEs without a language model.
Transformer-Based Multi-Aspect Multi-Granularity Non-Native English Speaker Pronunciation Assessment
May 06, 2022
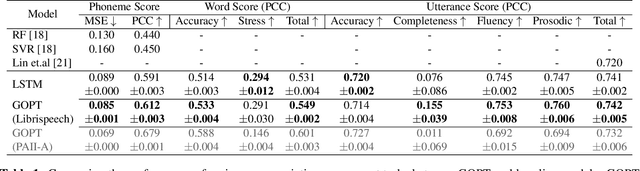
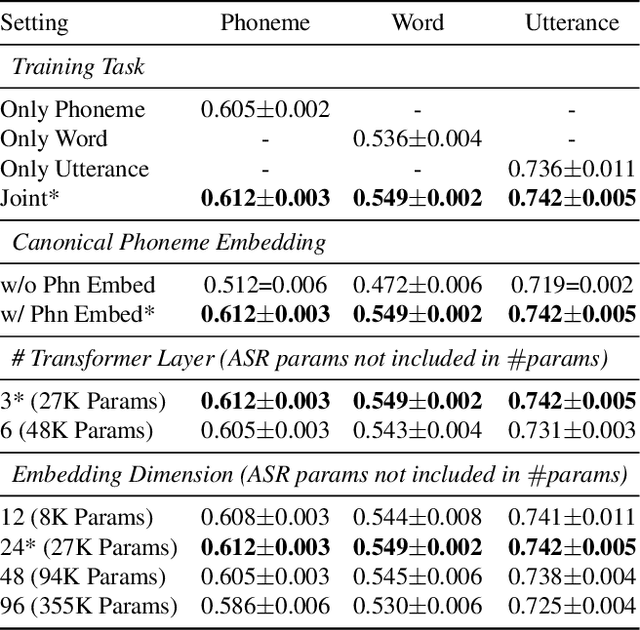
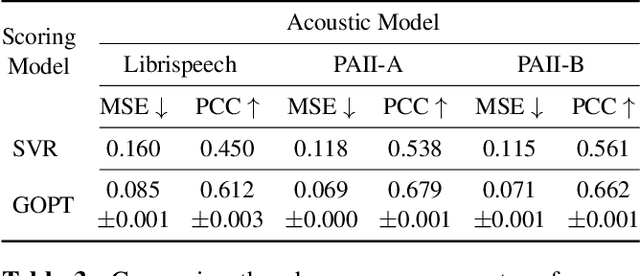
Automatic pronunciation assessment is an important technology to help self-directed language learners. While pronunciation quality has multiple aspects including accuracy, fluency, completeness, and prosody, previous efforts typically only model one aspect (e.g., accuracy) at one granularity (e.g., at the phoneme-level). In this work, we explore modeling multi-aspect pronunciation assessment at multiple granularities. Specifically, we train a Goodness Of Pronunciation feature-based Transformer (GOPT) with multi-task learning. Experiments show that GOPT achieves the best results on speechocean762 with a public automatic speech recognition (ASR) acoustic model trained on Librispeech.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jul 22, 2021
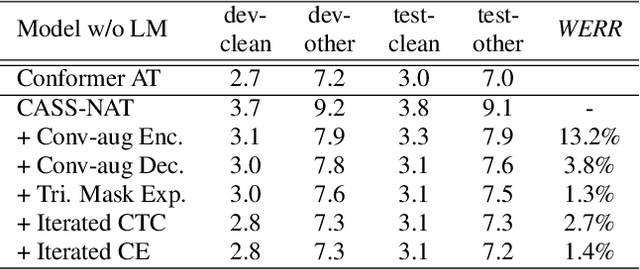
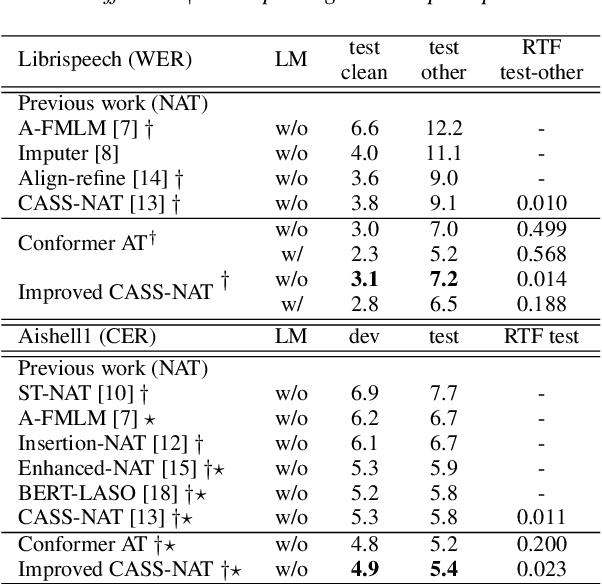
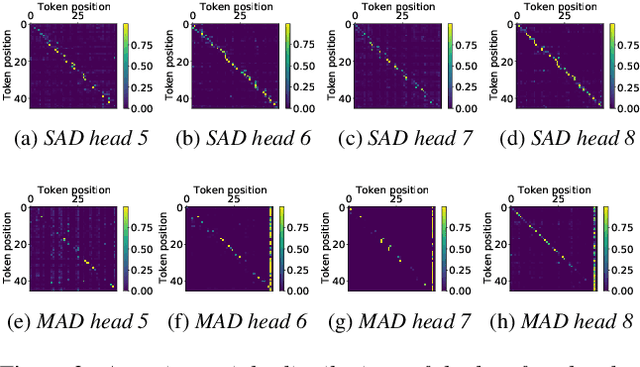
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.