 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Geometry-Aware Retrieval-Augmented Inference with LLMs over Hyperbolic Representations of Patient Trajectories
Feb 13, 2026Predicting future clinical events from longitudinal electronic health records (EHRs) is challenging due to sparse multi-type clinical events, hierarchical medical vocabularies, and the tendency of large language models (LLMs) to hallucinate when reasoning over long structured histories. We study next-visit event prediction, which aims to forecast a patient's upcoming clinical events based on prior visits. We propose GRAIL, a framework that models longitudinal EHRs using structured geometric representations and structure-aware retrieval. GRAIL constructs a unified clinical graph by combining deterministic coding-system hierarchies with data-driven temporal associations across event types, embeds this graph in hyperbolic space, and summarizes each visit as a probabilistic Central Event that denoises sparse observations. At inference time, GRAIL retrieves a structured set of clinically plausible future events aligned with hierarchical and temporal progression, and optionally refines their ranking using an LLM as a constrained inference-time reranker. Experiments on MIMIC-IV show that GRAIL consistently improves multi-type next-visit prediction and yields more hierarchy-consistent forecasts.
X-VORTEX: Spatio-Temporal Contrastive Learning for Wake Vortex Trajectory Forecasting
Feb 13, 2026Wake vortices are strong, coherent air turbulences created by aircraft, and they pose a major safety and capacity challenge for air traffic management. Tracking how vortices move, weaken, and dissipate over time from LiDAR measurements is still difficult because scans are sparse, vortex signatures fade as the flow breaks down under atmospheric turbulence and instabilities, and point-wise annotation is prohibitively expensive. Existing approaches largely treat each scan as an independent, fully supervised segmentation problem, which overlooks temporal structure and does not scale to the vast unlabeled archives collected in practice. We present X-VORTEX, a spatio-temporal contrastive learning framework grounded in Augmentation Overlap Theory that learns physics-aware representations from unlabeled LiDAR point cloud sequences. X-VORTEX addresses two core challenges: sensor sparsity and time-varying vortex dynamics. It constructs paired inputs from the same underlying flight event by combining a weakly perturbed sequence with a strongly augmented counterpart produced via temporal subsampling and spatial masking, encouraging the model to align representations across missing frames and partial observations. Architecturally, a time-distributed geometric encoder extracts per-scan features and a sequential aggregator models the evolving vortex state across variable-length sequences. We evaluate on a real-world dataset of over one million LiDAR scans. X-VORTEX achieves superior vortex center localization while using only 1% of the labeled data required by supervised baselines, and the learned representations support accurate trajectory forecasting.
TRACE: Temporal Reasoning via Agentic Context Evolution for Streaming Electronic Health Records (EHRs)
Feb 13, 2026Large Language Models (LLMs) encode extensive medical knowledge but struggle to apply it reliably to longitudinal patient trajectories, where evolving clinical states, irregular timing, and heterogeneous events degrade performance over time. Existing adaptation strategies rely on fine-tuning or retrieval-based augmentation, which introduce computational overhead, privacy constraints, or instability under long contexts. We introduce TRACE (Temporal Reasoning via Agentic Context Evolution), a framework that enables temporal clinical reasoning with frozen LLMs by explicitly structuring and maintaining context rather than extending context windows or updating parameters. TRACE operates over a dual-memory architecture consisting of a static Global Protocol encoding institutional clinical rules and a dynamic Individual Protocol tracking patient-specific state. Four agentic components, Router, Reasoner, Auditor, and Steward, coordinate over this structured memory to support temporal inference and state evolution. The framework maintains bounded inference cost via structured state compression and selectively audits safety-critical clinical decisions. Evaluated on longitudinal clinical event streams from MIMIC-IV, TRACE significantly improves next-event prediction accuracy, protocol adherence, and clinical safety over long-context and retrieval-augmented baselines, while producing interpretable and auditable reasoning traces.
MediEval: A Unified Medical Benchmark for Patient-Contextual and Knowledge-Grounded Reasoning in LLMs
Dec 23, 2025Large Language Models (LLMs) are increasingly applied to medicine, yet their adoption is limited by concerns over reliability and safety. Existing evaluations either test factual medical knowledge in isolation or assess patient-level reasoning without verifying correctness, leaving a critical gap. We introduce MediEval, a benchmark that links MIMIC-IV electronic health records (EHRs) to a unified knowledge base built from UMLS and other biomedical vocabularies. MediEval generates diverse factual and counterfactual medical statements within real patient contexts, enabling systematic evaluation across a 4-quadrant framework that jointly considers knowledge grounding and contextual consistency. Using this framework, we identify critical failure modes, including hallucinated support and truth inversion, that current proprietary, open-source, and domain-specific LLMs frequently exhibit. To address these risks, we propose Counterfactual Risk-Aware Fine-tuning (CoRFu), a DPO-based method with an asymmetric penalty targeting unsafe confusions. CoRFu improves by +16.4 macro-F1 points over the base model and eliminates truth inversion errors, demonstrating both higher accuracy and substantially greater safety.
Prioritizing Perception-Guided Self-Supervision: A New Paradigm for Causal Modeling in End-to-End Autonomous Driving
Nov 11, 2025End-to-end autonomous driving systems, predominantly trained through imitation learning, have demonstrated considerable effectiveness in leveraging large-scale expert driving data. Despite their success in open-loop evaluations, these systems often exhibit significant performance degradation in closed-loop scenarios due to causal confusion. This confusion is fundamentally exacerbated by the overreliance of the imitation learning paradigm on expert trajectories, which often contain unattributable noise and interfere with the modeling of causal relationships between environmental contexts and appropriate driving actions. To address this fundamental limitation, we propose Perception-Guided Self-Supervision (PGS) - a simple yet effective training paradigm that leverages perception outputs as the primary supervisory signals, explicitly modeling causal relationships in decision-making. The proposed framework aligns both the inputs and outputs of the decision-making module with perception results, such as lane centerlines and the predicted motions of surrounding agents, by introducing positive and negative self-supervision for the ego trajectory. This alignment is specifically designed to mitigate causal confusion arising from the inherent noise in expert trajectories. Equipped with perception-driven supervision, our method, built on a standard end-to-end architecture, achieves a Driving Score of 78.08 and a mean success rate of 48.64% on the challenging closed-loop Bench2Drive benchmark, significantly outperforming existing state-of-the-art methods, including those employing more complex network architectures and inference pipelines. These results underscore the effectiveness and robustness of the proposed PGS framework and point to a promising direction for addressing causal confusion and enhancing real-world generalization in autonomous driving.
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Apr 28, 2024



Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
GreeDy and CoDy: Counterfactual Explainers for Dynamic Graphs
Mar 25, 2024



Temporal Graph Neural Networks (TGNNs), crucial for modeling dynamic graphs with time-varying interactions, face a significant challenge in explainability due to their complex model structure. Counterfactual explanations, crucial for understanding model decisions, examine how input graph changes affect outcomes. This paper introduces two novel counterfactual explanation methods for TGNNs: GreeDy (Greedy Explainer for Dynamic Graphs) and CoDy (Counterfactual Explainer for Dynamic Graphs). They treat explanations as a search problem, seeking input graph alterations that alter model predictions. GreeDy uses a simple, greedy approach, while CoDy employs a sophisticated Monte Carlo Tree Search algorithm. Experiments show both methods effectively generate clear explanations. Notably, CoDy outperforms GreeDy and existing factual methods, with up to 59\% higher success rate in finding significant counterfactual inputs. This highlights CoDy's potential in clarifying TGNN decision-making, increasing their transparency and trustworthiness in practice.
Diversity Matters: Fully Exploiting Depth Clues for Reliable Monocular 3D Object Detection
May 19, 2022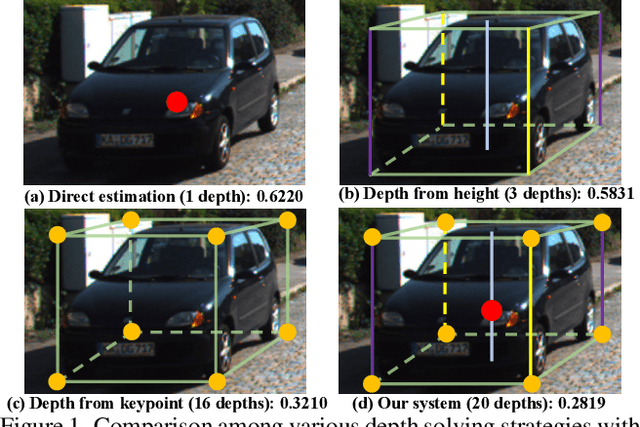
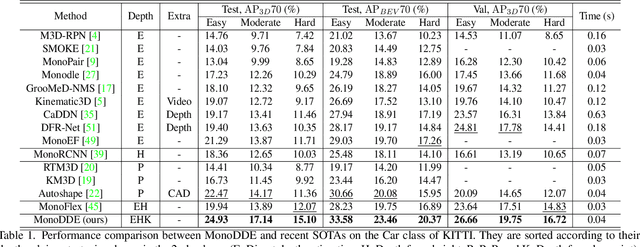
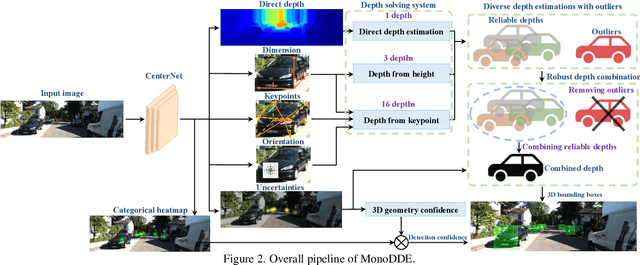
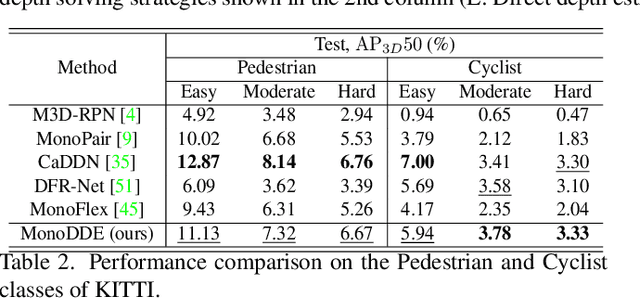
As an inherently ill-posed problem, depth estimation from single images is the most challenging part of monocular 3D object detection (M3OD). Many existing methods rely on preconceived assumptions to bridge the missing spatial information in monocular images, and predict a sole depth value for every object of interest. However, these assumptions do not always hold in practical applications. To tackle this problem, we propose a depth solving system that fully explores the visual clues from the subtasks in M3OD and generates multiple estimations for the depth of each target. Since the depth estimations rely on different assumptions in essence, they present diverse distributions. Even if some assumptions collapse, the estimations established on the remaining assumptions are still reliable. In addition, we develop a depth selection and combination strategy. This strategy is able to remove abnormal estimations caused by collapsed assumptions, and adaptively combine the remaining estimations into a single one. In this way, our depth solving system becomes more precise and robust. Exploiting the clues from multiple subtasks of M3OD and without introducing any extra information, our method surpasses the current best method by more than 20% relatively on the Moderate level of test split in the KITTI 3D object detection benchmark, while still maintaining real-time efficiency.
Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
May 28, 2021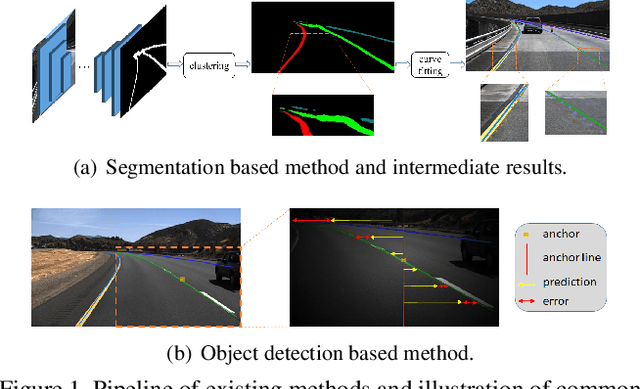
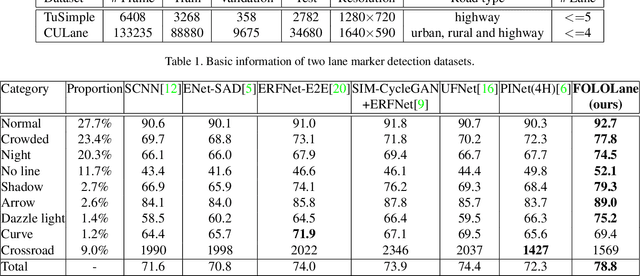
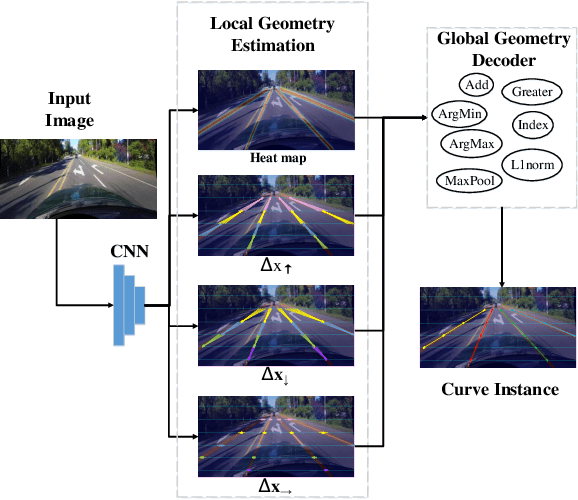

Mainstream lane marker detection methods are implemented by predicting the overall structure and deriving parametric curves through post-processing. Complex lane line shapes require high-dimensional output of CNNs to model global structures, which further increases the demand for model capacity and training data. In contrast, the locality of a lane marker has finite geometric variations and spatial coverage. We propose a novel lane marker detection solution, FOLOLane, that focuses on modeling local patterns and achieving prediction of global structures in a bottom-up manner. Specifically, the CNN models lowcomplexity local patterns with two separate heads, the first one predicts the existence of key points, and the second refines the location of key points in the local range and correlates key points of the same lane line. The locality of the task is consistent with the limited FOV of the feature in CNN, which in turn leads to more stable training and better generalization. In addition, an efficiency-oriented decoding algorithm was proposed as well as a greedy one, which achieving 36% runtime gains at the cost of negligible performance degradation. Both of the two decoders integrated local information into the global geometry of lane markers. In the absence of a complex network architecture design, the proposed method greatly outperforms all existing methods on public datasets while achieving the best state-of-the-art results and real-time processing simultaneously.