 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Apr 28, 2024



Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
Electrocardio Panorama: Synthesizing New ECG Views with Self-supervision
May 12, 2021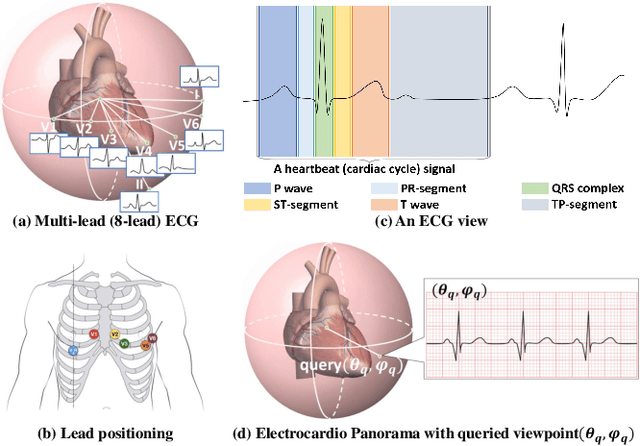
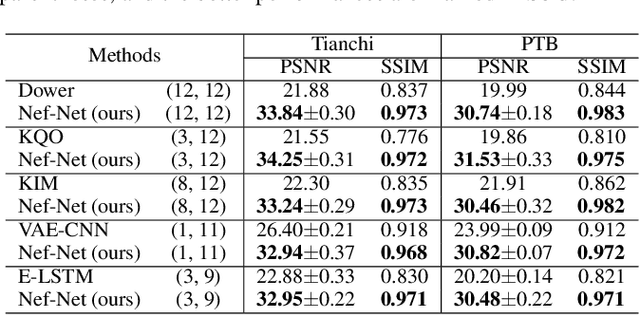
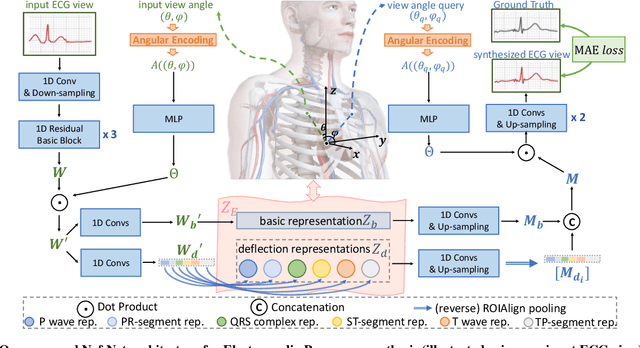
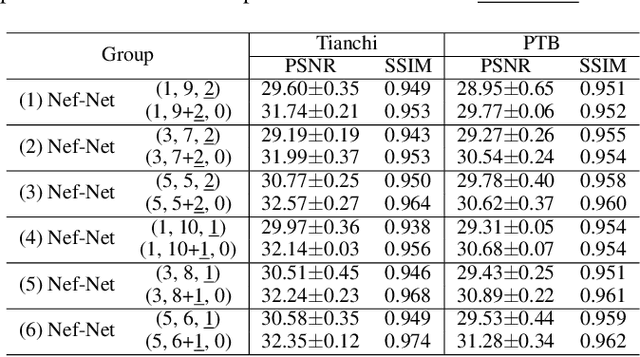
Multi-lead electrocardiogram (ECG) provides clinical information of heartbeats from several fixed viewpoints determined by the lead positioning. However, it is often not satisfactory to visualize ECG signals in these fixed and limited views, as some clinically useful information is represented only from a few specific ECG viewpoints. For the first time, we propose a new concept, Electrocardio Panorama, which allows visualizing ECG signals from any queried viewpoints. To build Electrocardio Panorama, we assume that an underlying electrocardio field exists, representing locations, magnitudes, and directions of ECG signals. We present a Neural electrocardio field Network (Nef-Net), which first predicts the electrocardio field representation by using a sparse set of one or few input ECG views and then synthesizes Electrocardio Panorama based on the predicted representations. Specially, to better disentangle electrocardio field information from viewpoint biases, a new Angular Encoding is proposed to process viewpoint angles. Also, we propose a self-supervised learning approach called Standin Learning, which helps model the electrocardio field without direct supervision. Further, with very few modifications, Nef-Net can also synthesize ECG signals from scratch. Experiments verify that our Nef-Net performs well on Electrocardio Panorama synthesis, and outperforms the previous work on the auxiliary tasks (ECG view transformation and ECG synthesis from scratch). The codes and the division labels of cardiac cycles and ECG deflections on Tianchi ECG and PTB datasets are available at https://github.com/WhatAShot/Electrocardio-Panorama.
Flow-Mixup: Classifying Multi-labeled Medical Images with Corrupted Labels
Feb 09, 2021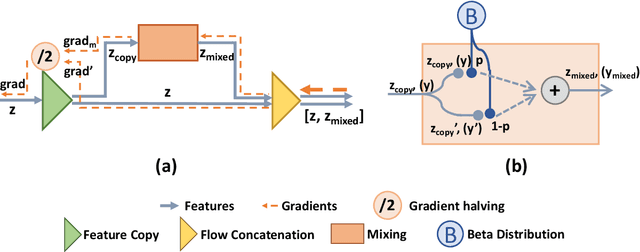
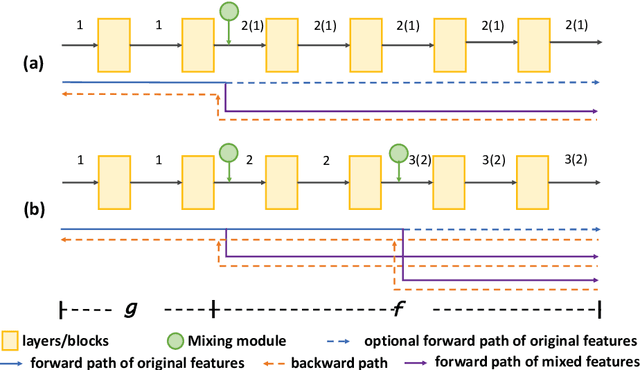
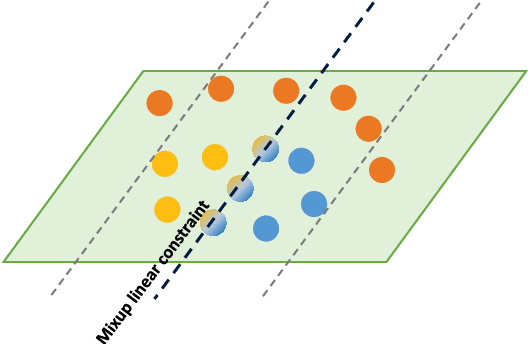
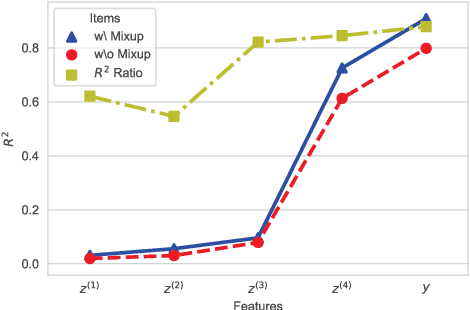
In clinical practice, medical image interpretation often involves multi-labeled classification, since the affected parts of a patient tend to present multiple symptoms or comorbidities. Recently, deep learning based frameworks have attained expert-level performance on medical image interpretation, which can be attributed partially to large amounts of accurate annotations. However, manually annotating massive amounts of medical images is impractical, while automatic annotation is fast but imprecise (possibly introducing corrupted labels). In this work, we propose a new regularization approach, called Flow-Mixup, for multi-labeled medical image classification with corrupted labels. Flow-Mixup guides the models to capture robust features for each abnormality, thus helping handle corrupted labels effectively and making it possible to apply automatic annotation. Specifically, Flow-Mixup decouples the extracted features by adding constraints to the hidden states of the models. Also, Flow-Mixup is more stable and effective comparing to other known regularization methods, as shown by theoretical and empirical analyses. Experiments on two electrocardiogram datasets and a chest X-ray dataset containing corrupted labels verify that Flow-Mixup is effective and insensitive to corrupted labels.