 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccKV: Towards Efficient Audio-Video LLMs Inference via Adaptive-Focusing and Cross-Calibration KV Cache Optimization
Nov 14, 2025

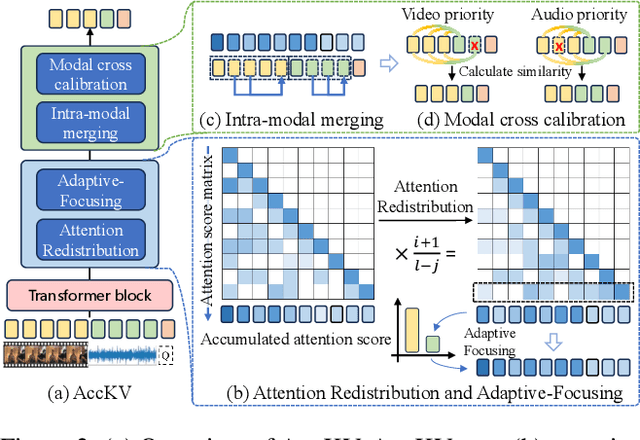

Recent advancements in Audio-Video Large Language Models (AV-LLMs) have enhanced their capabilities in tasks like audio-visual question answering and multimodal dialog systems. Video and audio introduce an extended temporal dimension, resulting in a larger key-value (KV) cache compared to static image embedding. A naive optimization strategy is to selectively focus on and retain KV caches of audio or video based on task. However, in the experiment, we observed that the attention of AV-LLMs to various modalities in the high layers is not strictly dependent on the task. In higher layers, the attention of AV-LLMs shifts more towards the video modality. In addition, we also found that directly integrating temporal KV of audio and spatial-temporal KV of video may lead to information confusion and significant performance degradation of AV-LLMs. If audio and video are processed indiscriminately, it may also lead to excessive compression or reservation of a certain modality, thereby disrupting the alignment between modalities. To address these challenges, we propose AccKV, an Adaptive-Focusing and Cross-Calibration KV cache optimization framework designed specifically for efficient AV-LLMs inference. Our method is based on layer adaptive focusing technology, selectively focusing on key modalities according to the characteristics of different layers, and enhances the recognition of heavy hitter tokens through attention redistribution. In addition, we propose a Cross-Calibration technique that first integrates inefficient KV caches within the audio and video modalities, and then aligns low-priority modalities with high-priority modalities to selectively evict KV cache of low-priority modalities. The experimental results show that AccKV can significantly improve the computational efficiency of AV-LLMs while maintaining accuracy.
FedCFA: Alleviating Simpson's Paradox in Model Aggregation with Counterfactual Federated Learning
Dec 25, 2024Federated learning (FL) is a promising technology for data privacy and distributed optimization, but it suffers from data imbalance and heterogeneity among clients. Existing FL methods try to solve the problems by aligning client with server model or by correcting client model with control variables. These methods excel on IID and general Non-IID data but perform mediocrely in Simpson's Paradox scenarios. Simpson's Paradox refers to the phenomenon that the trend observed on the global dataset disappears or reverses on a subset, which may lead to the fact that global model obtained through aggregation in FL does not accurately reflect the distribution of global data. Thus, we propose FedCFA, a novel FL framework employing counterfactual learning to generate counterfactual samples by replacing local data critical factors with global average data, aligning local data distributions with the global and mitigating Simpson's Paradox effects. In addition, to improve the quality of counterfactual samples, we introduce factor decorrelation (FDC) loss to reduce the correlation among features and thus improve the independence of extracted factors. We conduct extensive experiments on six datasets and verify that our method outperforms other FL methods in terms of efficiency and global model accuracy under limited communication rounds.
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Apr 28, 2024



Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.