 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneity-aware Personalized Federated Learning via Adaptive Dual-Agent Reinforcement Learning
Jan 28, 2025



Federated Learning (FL) empowers multiple clients to collaboratively train machine learning models without sharing local data, making it highly applicable in heterogeneous Internet of Things (IoT) environments. However, intrinsic heterogeneity in clients' model architectures and computing capabilities often results in model accuracy loss and the intractable straggler problem, which significantly impairs training effectiveness. To tackle these challenges, this paper proposes a novel Heterogeneity-aware Personalized Federated Learning method, named HAPFL, via multi-level Reinforcement Learning (RL) mechanisms. HAPFL optimizes the training process by incorporating three strategic components: 1) An RL-based heterogeneous model allocation mechanism. The parameter server employs a Proximal Policy Optimization (PPO)-based RL agent to adaptively allocate appropriately sized, differentiated models to clients based on their performance, effectively mitigating performance disparities. 2) An RL-based training intensity adjustment scheme. The parameter server leverages another PPO-based RL agent to dynamically fine-tune the training intensity for each client to further enhance training efficiency and reduce straggling latency. 3) A knowledge distillation-based mutual learning mechanism. Each client deploys both a heterogeneous local model and a homogeneous lightweight model named LiteModel, where these models undergo mutual learning through knowledge distillation. This uniform LiteModel plays a pivotal role in aggregating and sharing global knowledge, significantly enhancing the effectiveness of personalized local training. Experimental results across multiple benchmark datasets demonstrate that HAPFL not only achieves high accuracy but also substantially reduces the overall training time by 20.9%-40.4% and decreases straggling latency by 19.0%-48.0% compared to existing solutions.
Brain-Inspired Decentralized Satellite Learning in Space Computing Power Networks
Jan 27, 2025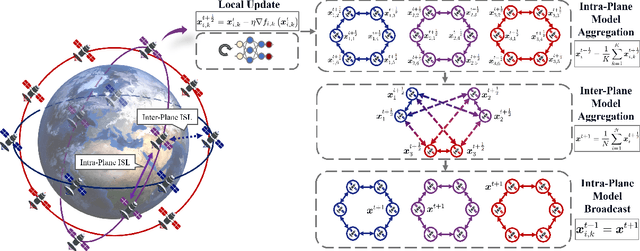
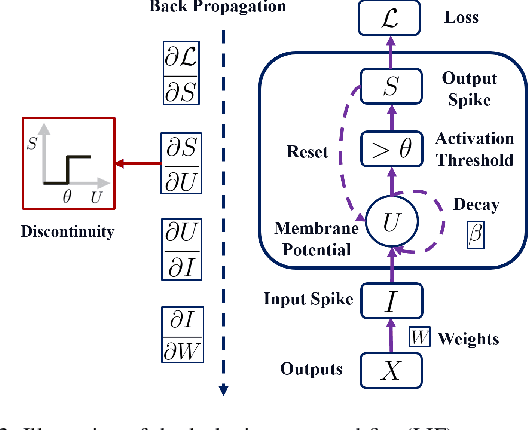
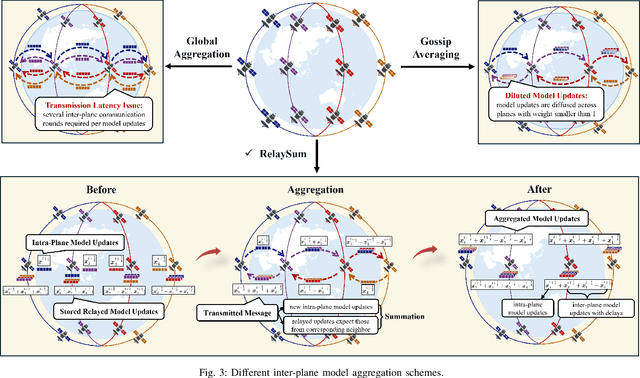
Satellite networks are able to collect massive space information with advanced remote sensing technologies, which is essential for real-time applications such as natural disaster monitoring. However, traditional centralized processing by the ground server incurs a severe timeliness issue caused by the transmission bottleneck of raw data. To this end, Space Computing Power Networks (Space-CPN) emerges as a promising architecture to coordinate the computing capability of satellites and enable on board data processing. Nevertheless, due to the natural limitations of solar panels, satellite power system is difficult to meet the energy requirements for ever-increasing intelligent computation tasks of artificial neural networks. To tackle this issue, we propose to employ spiking neural networks (SNNs), which is supported by the neuromorphic computing architecture, for on-board data processing. The extreme sparsity in its computation enables a high energy efficiency. Furthermore, to achieve effective training of these on-board models, we put forward a decentralized neuromorphic learning framework, where a communication-efficient inter-plane model aggregation method is developed with the inspiration from RelaySum. We provide a theoretical analysis to characterize the convergence behavior of the proposed algorithm, which reveals a network diameter related convergence speed. We then formulate a minimum diameter spanning tree problem on the inter-plane connectivity topology and solve it to further improve the learning performance. Extensive experiments are conducted to evaluate the superiority of the proposed method over benchmarks.
FedCFA: Alleviating Simpson's Paradox in Model Aggregation with Counterfactual Federated Learning
Dec 25, 2024Federated learning (FL) is a promising technology for data privacy and distributed optimization, but it suffers from data imbalance and heterogeneity among clients. Existing FL methods try to solve the problems by aligning client with server model or by correcting client model with control variables. These methods excel on IID and general Non-IID data but perform mediocrely in Simpson's Paradox scenarios. Simpson's Paradox refers to the phenomenon that the trend observed on the global dataset disappears or reverses on a subset, which may lead to the fact that global model obtained through aggregation in FL does not accurately reflect the distribution of global data. Thus, we propose FedCFA, a novel FL framework employing counterfactual learning to generate counterfactual samples by replacing local data critical factors with global average data, aligning local data distributions with the global and mitigating Simpson's Paradox effects. In addition, to improve the quality of counterfactual samples, we introduce factor decorrelation (FDC) loss to reduce the correlation among features and thus improve the independence of extracted factors. We conduct extensive experiments on six datasets and verify that our method outperforms other FL methods in terms of efficiency and global model accuracy under limited communication rounds.