 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Average Stability of Multipass Preconditioned SGD and Effective Dimension
Mar 12, 2026We study trade-offs between the population risk curvature, geometry of the noise, and preconditioning on the generalisation ability of the multipass Preconditioned Stochastic Gradient Descent (PSGD). Many practical optimisation heuristics implicitly navigate this trade-off in different ways -- for instance, some aim to whiten gradient noise, while others aim to align updates with expected loss curvature. When the geometry of the population risk curvature and the geometry of the gradient noise do not match, an aggressive choice that improves one aspect can amplify instability along the other, leading to suboptimal statistical behavior. In this paper we employ on-average algorithmic stability to connect generalisation of PSGD to the effective dimension that depends on these sources of curvature. While existing techniques for on-average stability of SGD are limited to a single pass, as first contribution we develop a new on-average stability analysis for multipass SGD that handles the correlations induced by data reuse. This allows us to derive excess risk bounds that depend on the effective dimension. In particular, we show that an improperly chosen preconditioner can yield suboptimal effective dimension dependence in both optimisation and generalisation. Finally, we complement our upper bounds with matching, instance-dependent lower bounds.
Black-Box Uniform Stability for Non-Euclidean Empirical Risk Minimization
Dec 20, 2024
We study first-order algorithms that are uniformly stable for empirical risk minimization (ERM) problems that are convex and smooth with respect to $p$-norms, $p \geq 1$. We propose a black-box reduction method that, by employing properties of uniformly convex regularizers, turns an optimization algorithm for H\"older smooth convex losses into a uniformly stable learning algorithm with optimal statistical risk bounds on the excess risk, up to a constant factor depending on $p$. Achieving a black-box reduction for uniform stability was posed as an open question by (Attia and Koren, 2022), which had solved the Euclidean case $p=2$. We explore applications that leverage non-Euclidean geometry in addressing binary classification problems.
Optimization without retraction on the random generalized Stiefel manifold
May 02, 2024



Optimization over the set of matrices that satisfy $X^\top B X = I_p$, referred to as the generalized Stiefel manifold, appears in many applications involving sampled covariance matrices such as canonical correlation analysis (CCA), independent component analysis (ICA), and the generalized eigenvalue problem (GEVP). Solving these problems is typically done by iterative methods, such as Riemannian approaches, which require a computationally expensive eigenvalue decomposition involving fully formed $B$. We propose a cheap stochastic iterative method that solves the optimization problem while having access only to a random estimate of the feasible set. Our method does not enforce the constraint in every iteration exactly, but instead it produces iterations that converge to a critical point on the generalized Stiefel manifold defined in expectation. The method has lower per-iteration cost, requires only matrix multiplications, and has the same convergence rates as its Riemannian counterparts involving the full matrix $B$. Experiments demonstrate its effectiveness in various machine learning applications involving generalized orthogonality constraints, including CCA, ICA, and GEVP.
Infeasible Deterministic, Stochastic, and Variance-Reduction Algorithms for Optimization under Orthogonality Constraints
Mar 29, 2023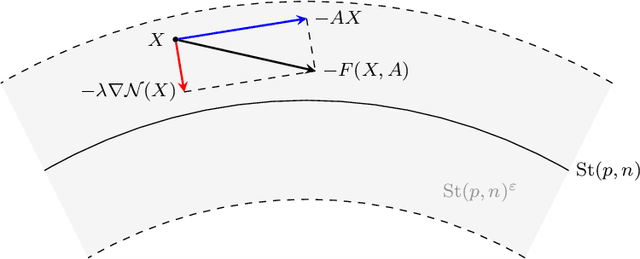
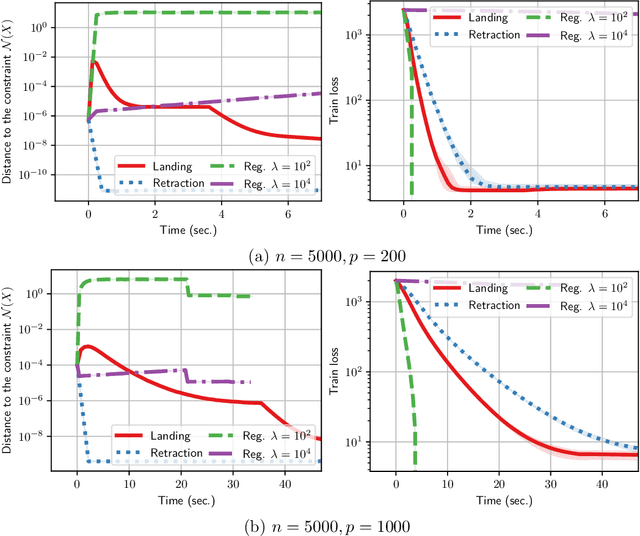


Orthogonality constraints naturally appear in many machine learning problems, from Principal Components Analysis to robust neural network training. They are usually solved using Riemannian optimization algorithms, which minimize the objective function while enforcing the constraint. However, enforcing the orthogonality constraint can be the most time-consuming operation in such algorithms. Recently, Ablin & Peyr\'e (2022) proposed the Landing algorithm, a method with cheap iterations that does not enforce the orthogonality constraint but is attracted towards the manifold in a smooth manner. In this article, we provide new practical and theoretical developments for the landing algorithm. First, the method is extended to the Stiefel manifold, the set of rectangular orthogonal matrices. We also consider stochastic and variance reduction algorithms when the cost function is an average of many functions. We demonstrate that all these methods have the same rate of convergence as their Riemannian counterparts that exactly enforce the constraint. Finally, our experiments demonstrate the promise of our approach to an array of machine-learning problems that involve orthogonality constraints.
Compressed sensing of low-rank plus sparse matrices
Jul 18, 2020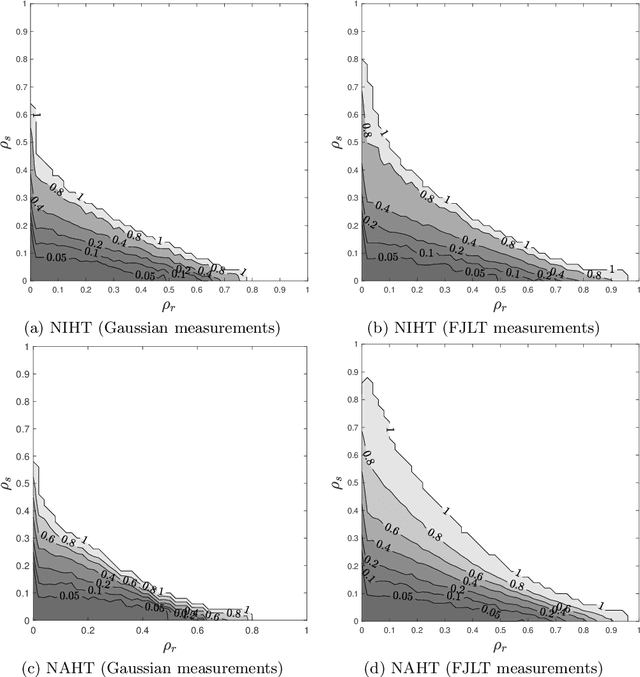



Expressing a matrix as the sum of a low-rank matrix plus a sparse matrix is a flexible model capturing global and local features in data. This model is the foundation of robust principle component analysis (Candes et al., 2011) (Chandrasekaran et al., 2009), and popularized by dynamic-foreground/static-background separation (Bouwmans et al., 2016) amongst other applications. Compressed sensing, matrix completion, and their variants (Eldar and Kutyniok, 2012) (Foucart and Rauhut, 2013) have established that data satisfying low complexity models can be efficiently measured and recovered from a number of measurements proportional to the model complexity rather than the ambient dimension. This manuscript develops similar guarantees showing that $m\times n$ matrices that can be expressed as the sum of a rank-$r$ matrix and a $s$-sparse matrix can be recovered by computationally tractable methods from $\mathcal{O}(r(m+n-r)+s)\log(mn/s)$ linear measurements. More specifically, we establish that the restricted isometry constants for the aforementioned matrices remain bounded independent of problem size provided $p/mn$, $s/p$, and $r(m+n-r)/p$ reman fixed. Additionally, we show that semidefinite programming and two hard threshold gradient descent algorithms, NIHT and NAHT, converge to the measured matrix provided the measurement operator's RIC's are sufficiently small. Numerical experiments illustrating these results are shown for synthetic problems, dynamic-foreground/static-background separation, and multispectral imaging.
Multilspectral snapshot demosaicing via non-convex matrix completion
Feb 28, 2019


Snapshot mosaic multispectral imagery acquires an undersampled data cube by acquiring a single spectral measurement per spatial pixel. Sensors which acquire $p$ frequencies, therefore, suffer from severe $1/p$ undersampling of the full data cube. We show that the missing entries can be accurately imputed using non-convex techniques from sparse approximation and matrix completion initialised with traditional demosaicing algorithms. In particular, we observe the peak signal-to-noise ratio can typically be improved by 2 to 5 dB over current state-of-the-art methods when simulating a $p=16$ mosaic sensor measuring both high and low altitude urban and rural scenes as well as ground-based scenes.