 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyBipe: An End-to-End Framework for Training and Deploying Bipedal Robots Guided by Large Language Models
Sep 13, 2024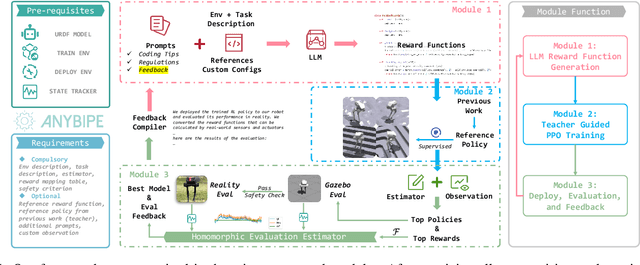


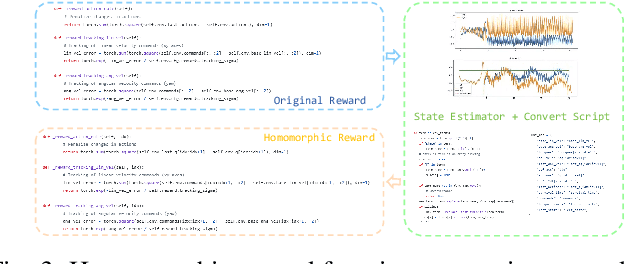
Training and deploying reinforcement learning (RL) policies for robots, especially in accomplishing specific tasks, presents substantial challenges. Recent advancements have explored diverse reward function designs, training techniques, simulation-to-reality (sim-to-real) transfers, and performance analysis methodologies, yet these still require significant human intervention. This paper introduces an end-to-end framework for training and deploying RL policies, guided by Large Language Models (LLMs), and evaluates its effectiveness on bipedal robots. The framework consists of three interconnected modules: an LLM-guided reward function design module, an RL training module leveraging prior work, and a sim-to-real homomorphic evaluation module. This design significantly reduces the need for human input by utilizing only essential simulation and deployment platforms, with the option to incorporate human-engineered strategies and historical data. We detail the construction of these modules, their advantages over traditional approaches, and demonstrate the framework's capability to autonomously develop and refine controlling strategies for bipedal robot locomotion, showcasing its potential to operate independently of human intervention.