 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSkill: Open-World Self-Evolution for LLM Agents
Jun 04, 2026Self-evolving agents requires adaptation after deployment, but existing approaches assume a usable learning loop, such as curated skills, successful trajectories, or verifier signals. Real open-world deployments may provide none of these, offering only a task prompt. In this work, we study open-world self-evolution, where an agent must build both its skills and its own verification signals from scratch, using open-world resources but no target-task supervision. We propose OpenSkill, a framework that bootstraps this loop: it acquires grounded knowledge and verification anchors from documentation, repositories, and the web, synthesizes them into transferable skills, and refines those skills against self-built virtual tasks grounded in the anchors rather than in target answers. The open world thus supplies both the knowledge to be learned and a supervision-independent practice environment, with target-task supervision reserved for final evaluation. Across three benchmarks and two target agents, OpenSkill attains the best automated pass rate while satisfying the no-supervision constraint. Analysis shows its skills transfer across models without model-specific adaptation, and its self-built verifier aligns with ground-truth outcomes despite never accessing them.
Distributionally Robust Set Representation Learning Under Inference-Time Element Corruption
May 28, 2026Standard Set Representation Learning methods typically excel on curated data but often overlook the challenge of inference-time element corruption. This refers to scenarios where deployed models encounter element-level degradations, such as outliers or missing components, that may distort set representation and degrade performance. We propose SW-DRSO, a distributionally robust optimization framework tailored for sets. Rather than minimizing loss solely on observed training data, SW-DRSO optimizes a tractable surrogate of the worst-case expected loss over a family of plausible inference-time variations. We introduce a barycentric adversary that approximates the intractable search over corrupted sets by a differentiable training-time optimization over simplex weights. Extensive experiments across four tasks demonstrate that SW-DRSO effectively enhances robustness against corruption while maintaining high overall performance.
A Deployment Audit of Release-Side Risk in Conformal Triage under Prevalence Shift
May 20, 2026Conformal triage converts predictive scores into deployment actions that either release a case, flag it for urgent attention, or defer it to human review. Under prevalence shift, however, the usual summaries of marginal coverage and human-review rate can miss the safety-critical question of whether patients who truly experience the target event are released without review. To address this gap, we introduce a leakage-aware deployment audit for release-side conformal triage. It first assigns target subjects to three non-overlapping roles: prevalence correction, conformal calibration, and held-out release-safety evaluation. This separation then lets the audit evaluate release directly: how many event-positive patients are cleared without review, whether the pilot has enough event labels for calibration, and how the safety-review trade-off shifts. Applying this audit to a retrospective NSCLC pilot shows why lower review can be misleading: after prevalence correction, the pooled conformal branch lowers review by releasing more patients, some of whom are event-positive. Within the audit, the classwise branch acts as a scarcity diagnostic: the pilot has too few event labels to certify safe low-review release.
Vision-Language-Action in Robotics: A Survey of Datasets, Benchmarks, and Data Engines
Apr 24, 2026Despite remarkable progress in Vision--Language--Action (VLA) models, a central bottleneck remains underexamined: the data infrastructure that underlies embodied learning. In this survey, we argue that future advances in VLA will depend less on model architecture and more on the co-design of high-fidelity data engines and structured evaluation protocols. To this end, we present a systematic, data-centric analysis of VLA research organized around three pillars: datasets, benchmarks, and data engines. For datasets, we categorize real-world and synthetic corpora along embodiment diversity, modality composition, and action space formulation, revealing a persistent fidelity-cost trade-off that fundamentally constrains large-scale collection. For benchmarks, we analyze task complexity and environment structure jointly, exposing structural gaps in compositional generalization and long-horizon reasoning evaluation that existing protocols fail to address. For data engines, we examine simulation-based, video-reconstruction, and automated task-generation paradigms, identifying their shared limitations in physical grounding and sim-to-real transfer. Synthesizing these analyses, we distill four open challenges: representation alignment, multimodal supervision, reasoning assessment, and scalable data generation. Addressing them, we argue, requires treating data infrastructure as a first-class research problem rather than a background concern.
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
Apr 14, 2026To sustain coherent long-term interactions, Large Language Model (LLM) agents must navigate the tension between acquiring new information and retaining prior knowledge. Current unified stream-based memory systems facilitate context updates but remain vulnerable to interference from transient noise. Conversely, discrete structured memory architectures provide robust knowledge retention but often struggle to adapt to evolving narratives. To address this, we propose GAM, a hierarchical Graph-based Agentic Memory framework that explicitly decouples memory encoding from consolidation to effectively resolve the conflict between rapid context perception and stable knowledge retention. By isolating ongoing dialogue in an event progression graph and integrating it into a topic associative network only upon semantic shifts, our approach minimizes interference while preserving long-term consistency. Additionally, we introduce a graph-guided, multi-factor retrieval strategy to enhance context precision. Experiments on LoCoMo and LongDialQA indicate that our method consistently outperforms state-of-the-art baselines in both reasoning accuracy and efficiency.
Unveiling Language Routing Isolation in Multilingual MoE Models for Interpretable Subnetwork Adaptation
Apr 04, 2026Mixture-of-Experts (MoE) models exhibit striking performance disparities across languages, yet the internal mechanisms driving these gaps remain poorly understood. In this work, we conduct a systematic analysis of expert routing patterns in MoE models, revealing a phenomenon we term Language Routing Isolation, in which high- and low-resource languages tend to activate largely disjoint expert sets. Through layer-stratified analysis, we further show that routing patterns exhibit a layer-wise convergence-divergence pattern across model depth. Building on these findings, we propose RISE (Routing Isolation-guided Subnetwork Enhancement), a framework that exploits routing isolation to identify and adapt language-specific expert subnetworks. RISE applies a tripartite selection strategy, using specificity scores to identify language-specific experts in shallow and deep layers and overlap scores to select universal experts in middle layers. By training only the selected subnetwork while freezing all other parameters, RISE substantially improves low-resource language performance while preserving capabilities in other languages. Experiments on 10 languages demonstrate that RISE achieves target-language F1 gains of up to 10.85% with minimal cross-lingual degradation.
EvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Apr 02, 2026Anthropic proposes the concept of skills for LLM agents to tackle multi-step professional tasks that simple tool invocations cannot address. A tool is a single, self-contained function, whereas a skill is a structured bundle of interdependent multi-file artifacts. Currently, skill generation is not only label-intensive due to manual authoring, but also may suffer from human--machine cognitive misalignment, which can lead to degraded agent performance, as evidenced by evaluations on SkillsBench. Therefore, we aim to enable agents to autonomously generate skills. However, existing self-evolving methods designed for tools cannot be directly applied to skills due to their increased complexity. To address these issues, we propose EvoSkills, a self-evolving skills framework that enables agents to autonomously construct complex, multi-file skill packages. Specifically, EvoSkills couples a Skill Generator that iteratively refines skills with a Surrogate Verifier that co-evolves to provide informative and actionable feedback without access to ground-truth test content. On SkillsBench, EvoSkills achieves the highest pass rate among five baselines on both Claude Code and Codex, and also exhibits strong generalization capabilities to six additional LLMs.
When Users Change Their Mind: Evaluating Interruptible Agents in Long-Horizon Web Navigation
Apr 01, 2026As LLM agents transition from short, static problem solving to executing complex, long-horizon tasks in dynamic environments, the ability to handle user interruptions, such as adding requirement or revising goals, during mid-task execution is becoming a core requirement for realistic deployment. However, existing benchmarks largely assume uninterrupted agent behavior or study interruptions only in short, unconstrained language tasks. In this paper, we present the first systematic study of interruptible agents in long-horizon, environmentally grounded web navigation tasks, where actions induce persistent state changes. We formalize three realistic interruption types, including addition, revision, and retraction, and introduce InterruptBench, a benchmark derived from WebArena-Lite that synthesizes high-quality interruption scenarios under strict semantic constraints. Using a unified interruption simulation framework, we evaluate six strong LLM backbones across single- and multi-turn interruption settings, analyzing both their effectiveness in adapting to updated intents and their efficiency in recovering from mid-task changes. Our results show that handling user interruptions effectively and efficiently during long-horizon agentic tasks remains challenging for powerful large-scale LLMs. Code and dataset are available at https://github.com/HenryPengZou/InterruptBench.
Class Incremental Fault Diagnosis under Limited Fault Data via Supervised Contrastive Knowledge Distillation
Jan 16, 2025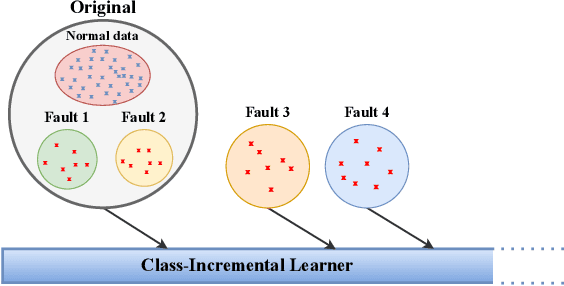
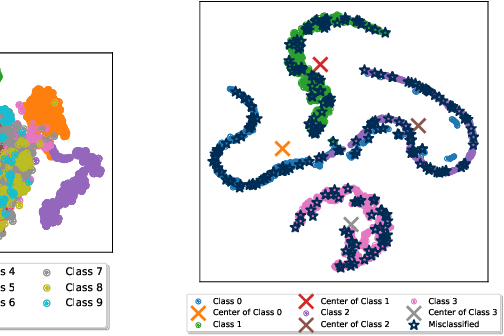
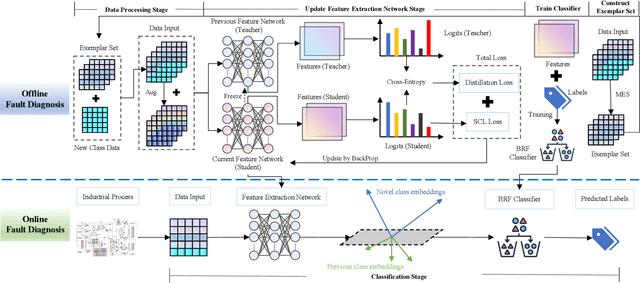
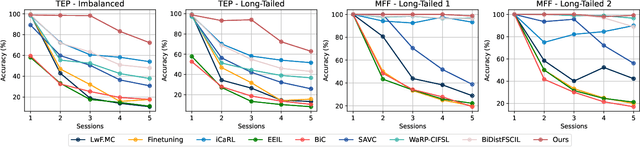
Class-incremental fault diagnosis requires a model to adapt to new fault classes while retaining previous knowledge. However, limited research exists for imbalanced and long-tailed data. Extracting discriminative features from few-shot fault data is challenging, and adding new fault classes often demands costly model retraining. Moreover, incremental training of existing methods risks catastrophic forgetting, and severe class imbalance can bias the model's decisions toward normal classes. To tackle these issues, we introduce a Supervised Contrastive knowledge distiLlation for class Incremental Fault Diagnosis (SCLIFD) framework proposing supervised contrastive knowledge distillation for improved representation learning capability and less forgetting, a novel prioritized exemplar selection method for sample replay to alleviate catastrophic forgetting, and the Random Forest Classifier to address the class imbalance. Extensive experimentation on simulated and real-world industrial datasets across various imbalance ratios demonstrates the superiority of SCLIFD over existing approaches. Our code can be found at https://github.com/Zhang-Henry/SCLIFD_TII.
SAKA: An Intelligent Platform for Semi-automated Knowledge Graph Construction and Application
Oct 10, 2024Knowledge graph (KG) technology is extensively utilized in many areas, and many companies offer applications based on KG. Nonetheless, the majority of KG platforms necessitate expertise and tremendous time and effort of users to construct KG records manually, which poses great difficulties for ordinary people to use. Additionally, audio data is abundant and holds valuable information, but it is challenging to transform it into a KG. What's more, the platforms usually do not leverage the full potential of the KGs constructed by users. In this paper, we propose an intelligent and user-friendly platform for Semi-automated KG Construction and Application (SAKA) to address the problems aforementioned. Primarily, users can semi-automatically construct KGs from structured data of numerous areas by interacting with the platform, based on which multi-versions of KG can be stored, viewed, managed, and updated. Moreover, we propose an Audio-based KG Information Extraction (AGIE) method to establish KGs from audio data. Lastly, the platform creates a semantic parsing-based knowledge base question answering (KBQA) system based on the user-created KGs. We prove the feasibility of the semi-automatic KG construction method on the SAKA platform.