 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Contrastive Learning for Generalized Out-of-distribution Fault Diagnosis (GOOFD) Framework
Jun 27, 2023Fault diagnosis is essential in industrial processes for monitoring the conditions of important machines. With the ever-increasing complexity of working conditions and demand for safety during production and operation, different diagnosis methods are required, and more importantly, an integrated fault diagnosis system that can cope with multiple tasks is highly desired. However, the diagnosis subtasks are often studied separately, and the currently available methods still need improvement for such a generalized system. To address this issue, we propose the Generalized Out-of-distribution Fault Diagnosis (GOOFD) framework to integrate diagnosis subtasks, such as fault detection, fault classification, and novel fault diagnosis. Additionally, a unified fault diagnosis method based on internal contrastive learning is put forward to underpin the proposed generalized framework. The method extracts features utilizing the internal contrastive learning technique and then recognizes the outliers based on the Mahalanobis distance. Experiments are conducted on a simulated benchmark dataset as well as two practical process datasets to evaluate the proposed framework. As demonstrated in the experiments, the proposed method achieves better performance compared with several existing techniques and thus verifies the effectiveness of the proposed framework.
Supervised Contrastive Learning with TPE-based Bayesian Optimization of Tabular Data for Imbalanced Learning
Oct 19, 2022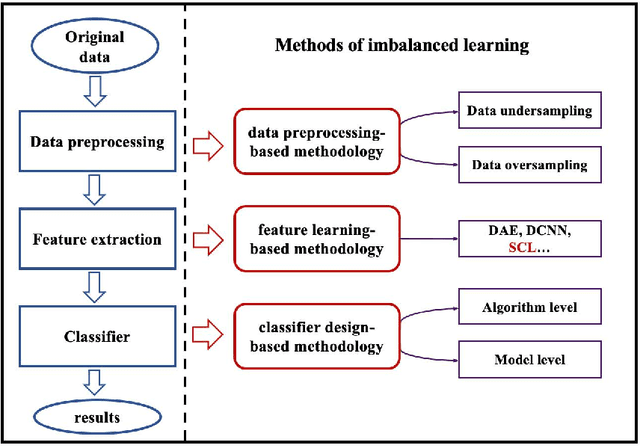
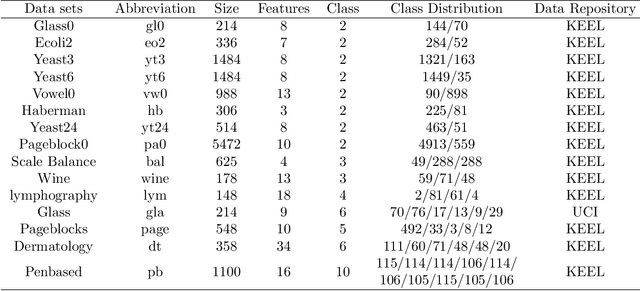
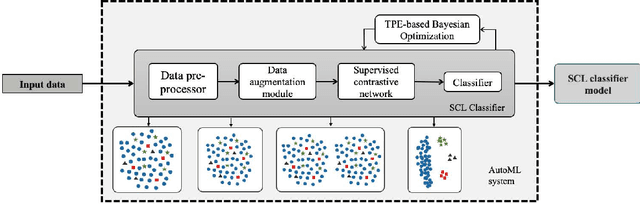
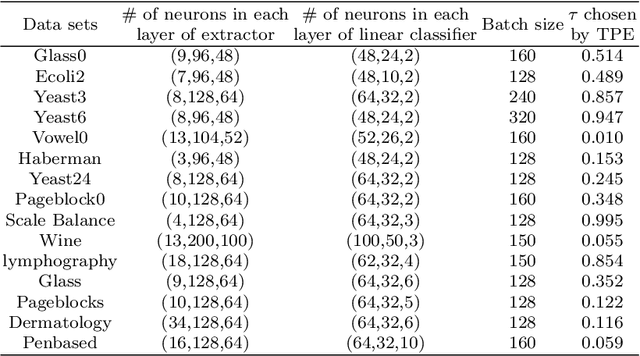
Class imbalance has a detrimental effect on the predictive performance of most supervised learning algorithms as the imbalanced distribution can lead to a bias preferring the majority class. To solve this problem, we propose a Supervised Contrastive Learning (SCL) method with Bayesian optimization technique based on Tree-structured Parzen Estimator (TPE) for imbalanced tabular datasets. Compared with supervised learning, contrastive learning can avoid "label bias" by extracting the information hidden in data. Based on contrastive loss, SCL can exploit the label information to address insufficient data augmentation of tabular data, and is thus used in the proposed SCL-TPE method to learn a discriminative representation of data. Additionally, as the hyper-parameter temperature has a decisive influence on the SCL performance and is difficult to tune, TPE-based Bayesian optimization is introduced to automatically select the best temperature. Experiments are conducted on both binary and multi-class imbalanced tabular datasets. As shown in the results obtained, TPE outperforms other hyper-parameter optimization (HPO) methods such as grid search, random search, and genetic algorithm. More importantly, the proposed SCL-TPE method achieves much-improved performance compared with the state-of-the-art methods.