 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAKA: An Intelligent Platform for Semi-automated Knowledge Graph Construction and Application
Oct 10, 2024Knowledge graph (KG) technology is extensively utilized in many areas, and many companies offer applications based on KG. Nonetheless, the majority of KG platforms necessitate expertise and tremendous time and effort of users to construct KG records manually, which poses great difficulties for ordinary people to use. Additionally, audio data is abundant and holds valuable information, but it is challenging to transform it into a KG. What's more, the platforms usually do not leverage the full potential of the KGs constructed by users. In this paper, we propose an intelligent and user-friendly platform for Semi-automated KG Construction and Application (SAKA) to address the problems aforementioned. Primarily, users can semi-automatically construct KGs from structured data of numerous areas by interacting with the platform, based on which multi-versions of KG can be stored, viewed, managed, and updated. Moreover, we propose an Audio-based KG Information Extraction (AGIE) method to establish KGs from audio data. Lastly, the platform creates a semantic parsing-based knowledge base question answering (KBQA) system based on the user-created KGs. We prove the feasibility of the semi-automatic KG construction method on the SAKA platform.
DynaThink: Fast or Slow? A Dynamic Decision-Making Framework for Large Language Models
Jul 01, 2024


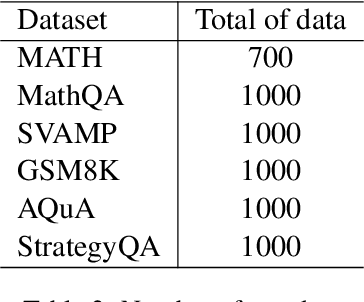
Large language models (LLMs) have demonstrated emergent capabilities across diverse reasoning tasks via popular Chains-of-Thought (COT) prompting. However, such a simple and fast COT approach often encounters limitations in dealing with complicated problems, while a thorough method, which considers multiple reasoning pathways and verifies each step carefully, results in slower inference. This paper addresses the challenge of enabling LLMs to autonomously select between fast and slow inference methods, thereby optimizing both efficiency and effectiveness. We introduce a dynamic decision-making framework that categorizes tasks into two distinct pathways: 'Fast', designated for tasks where the LLM quickly identifies a high-confidence solution, and 'Slow', allocated for tasks that the LLM perceives as complex and for which it has low confidence in immediate solutions as well as requiring more reasoning paths to verify. Experiments on five popular reasoning benchmarks demonstrated the superiority of the DynaThink over baselines.