 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFlare: Scaling Up Draft Capacity for Block Diffusion Speculative Decoding
Jun 01, 2026Block diffusion speculative decoding accelerates LLM inference by predicting all tokens within a block simultaneously for the target model to verify in parallel. Predicting an entire block at once requires a sufficiently capable draft model and effective utilization of the target model's internal knowledge. However, the state-of-the-art method DFlash constrains all draft layers to share a single fused representation derived from only a few target layers, limiting per-layer expressiveness and hindering further scaling of draft capacity. In this paper, we present \modelname, which flares out the narrow conditioning bottleneck of DFlash through a lightweight layer-wise fusion mechanism: each draft layer attends to its own learnable combination of a broad set of target layers at negligible overhead, simultaneously injecting richer target knowledge and providing every draft layer with a distinct input. This enhanced per-layer expressiveness enables scaling the draft model to deeper architectures with consistent gains. We further scale training data from 800K to 2.4M samples to fully exploit the enlarged capacity. On six benchmarks spanning mathematical reasoning, code generation, and conversation, \modelname attains average wall-clock speedups of 5.52x on Qwen3-4B, 5.46x on Qwen3-8B, and 3.91x on GPT-OSS-20B, improving over DFlash by roughly 11\%, 8\%, and 5\% respectively. Our code is available at https://github.com/Tencent/AngelSlim.
Learning to Draft: Adaptive Speculative Decoding with Reinforcement Learning
Mar 02, 2026Speculative decoding accelerates large language model (LLM) inference by using a small draft model to generate candidate tokens for a larger target model to verify. The efficacy of this technique hinges on the trade-off between the time spent on drafting candidates and verifying them. However, current state-of-the-art methods rely on a static time allocation, while recent dynamic approaches optimize for proxy metrics like acceptance length, often neglecting the true time cost and treating the drafting and verification phases in isolation. To address these limitations, we introduce Learning to Draft (LTD), a novel method that directly optimizes for throughput of each draft-and-verify cycle. We formulate the problem as a reinforcement learning environment and train two co-adaptive policies to dynamically coordinate the draft and verification phases. This encourages the policies to adapt to each other and explicitly maximize decoding efficiency. We conducted extensive evaluations on five diverse LLMs and four distinct tasks. Our results show that LTD achieves speedup ratios ranging from 2.24x to 4.32x, outperforming the state-of-the-art method Eagle3 up to 36.4%.
More Tokens, Lower Precision: Towards the Optimal Token-Precision Trade-off in KV Cache Compression
Dec 17, 2024As large language models (LLMs) process increasing context windows, the memory usage of KV cache has become a critical bottleneck during inference. The mainstream KV compression methods, including KV pruning and KV quantization, primarily focus on either token or precision dimension and seldom explore the efficiency of their combination. In this paper, we comprehensively investigate the token-precision trade-off in KV cache compression. Experiments demonstrate that storing more tokens in the KV cache with lower precision, i.e., quantized pruning, can significantly enhance the long-context performance of LLMs. Furthermore, in-depth analysis regarding token-precision trade-off from a series of key aspects exhibit that, quantized pruning achieves substantial improvements in retrieval-related tasks and consistently performs well across varying input lengths. Moreover, quantized pruning demonstrates notable stability across different KV pruning methods, quantization strategies, and model scales. These findings provide valuable insights into the token-precision trade-off in KV cache compression. We plan to release our code in the near future.
Retrieval-based Full-length Wikipedia Generation for Emergent Events
Feb 28, 2024



In today's fast-paced world, the growing demand to quickly generate comprehensive and accurate Wikipedia documents for emerging events is both crucial and challenging. However, previous efforts in Wikipedia generation have often fallen short of meeting real-world requirements. Some approaches focus solely on generating segments of a complete Wikipedia document, while others overlook the importance of faithfulness in generation or fail to consider the influence of the pre-training corpus. In this paper, we simulate a real-world scenario where structured full-length Wikipedia documents are generated for emergent events using input retrieved from web sources. To ensure that Large Language Models (LLMs) are not trained on corpora related to recently occurred events, we select events that have taken place recently and introduce a new benchmark Wiki-GenBen, which consists of 309 events paired with their corresponding retrieved web pages for generating evidence. Additionally, we design a comprehensive set of systematic evaluation metrics and baseline methods, to evaluate the capability of LLMs in generating factual full-length Wikipedia documents. The data and code are open-sourced at WikiGenBench.
ConFiguRe: Exploring Discourse-level Chinese Figures of Speech
Sep 16, 2022
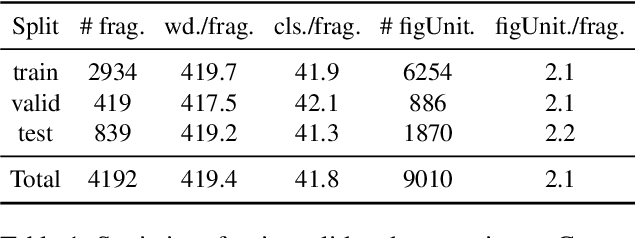

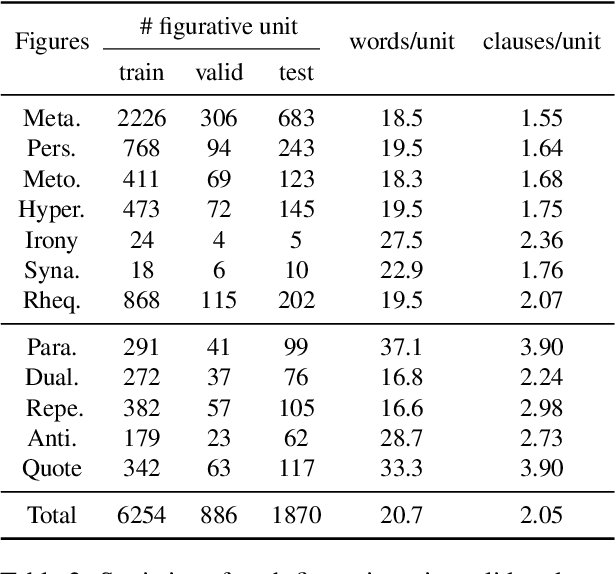
Figures of speech, such as metaphor and irony, are ubiquitous in literature works and colloquial conversations. This poses great challenge for natural language understanding since figures of speech usually deviate from their ostensible meanings to express deeper semantic implications. Previous research lays emphasis on the literary aspect of figures and seldom provide a comprehensive exploration from a view of computational linguistics. In this paper, we first propose the concept of figurative unit, which is the carrier of a figure. Then we select 12 types of figures commonly used in Chinese, and build a Chinese corpus for Contextualized Figure Recognition (ConFiguRe). Different from previous token-level or sentence-level counterparts, ConFiguRe aims at extracting a figurative unit from discourse-level context, and classifying the figurative unit into the right figure type. On ConFiguRe, three tasks, i.e., figure extraction, figure type classification and figure recognition, are designed and the state-of-the-art techniques are utilized to implement the benchmarks. We conduct thorough experiments and show that all three tasks are challenging for existing models, thus requiring further research. Our dataset and code are publicly available at https://github.com/pku-tangent/ConFiguRe.