 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLII: Visual-Text Inpainting via Cross-Modal Predictive Interaction
Paper and Code
Jul 23, 2024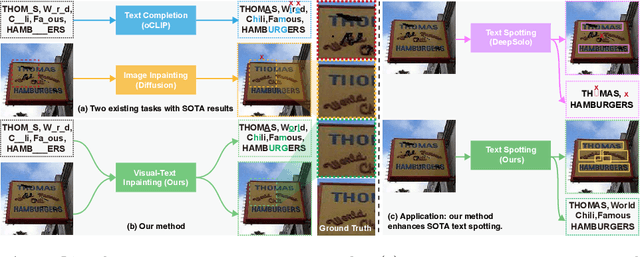
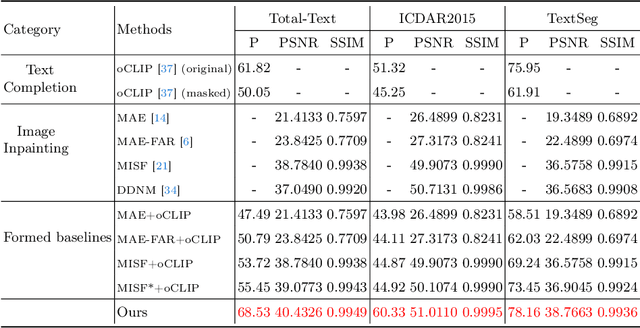
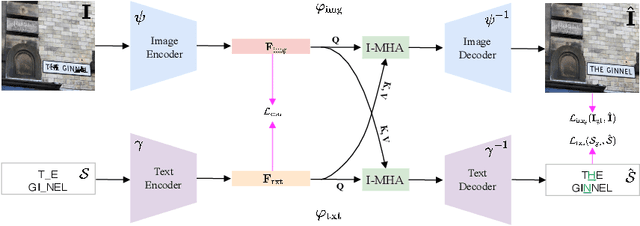

Image inpainting aims to fill missing pixels in damaged images and has achieved significant progress with cut-edging learning techniques. Nevertheless, state-of-the-art inpainting methods are mainly designed for nature images and cannot correctly recover text within scene text images, and training existing models on the scene text images cannot fix the issues. In this work, we identify the visual-text inpainting task to achieve high-quality scene text image restoration and text completion: Given a scene text image with unknown missing regions and the corresponding text with unknown missing characters, we aim to complete the missing information in both images and text by leveraging their complementary information. Intuitively, the input text, even if damaged, contains language priors of the contents within the images and can guide the image inpainting. Meanwhile, the scene text image includes the appearance cues of the characters that could benefit text recovery. To this end, we design the cross-modal predictive interaction (CLII) model containing two branches, i.e., ImgBranch and TxtBranch, for scene text inpainting and text completion, respectively while leveraging their complementary effectively. Moreover, we propose to embed our model into the SOTA scene text spotting method and significantly enhance its robustness against missing pixels, which demonstrates the practicality of the newly developed task. To validate the effectiveness of our method, we construct three real datasets based on existing text-related datasets, containing 1838 images and covering three scenarios with curved, incidental, and styled texts, and conduct extensive experiments to show that our method outperforms baselines significantly.