 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo better language models have crisper vision?
Oct 09, 2024

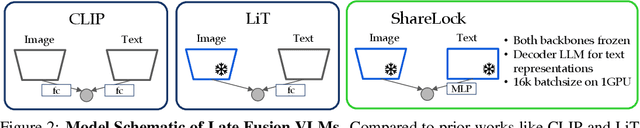

How well do text-only Large Language Models (LLMs) grasp the visual world? As LLMs are increasingly used in computer vision, addressing this question becomes both fundamental and pertinent. However, existing studies have primarily focused on limited scenarios, such as their ability to generate visual content or cluster multimodal data. To this end, we propose the Visual Text Representation Benchmark (ViTeRB) to isolate key properties that make language models well-aligned with the visual world. With this, we identify large-scale decoder-based LLMs as ideal candidates for representing text in vision-centric contexts, counter to the current practice of utilizing text encoders. Building on these findings, we propose ShareLock, an ultra-lightweight CLIP-like model. By leveraging precomputable frozen features from strong vision and language models, ShareLock achieves an impressive 51% accuracy on ImageNet despite utilizing just 563k image-caption pairs. Moreover, training requires only 1 GPU hour (or 10 hours including the precomputation of features) - orders of magnitude less than prior methods. Code will be released.
Graph Neural Networks for Learning Equivariant Representations of Neural Networks
Mar 20, 2024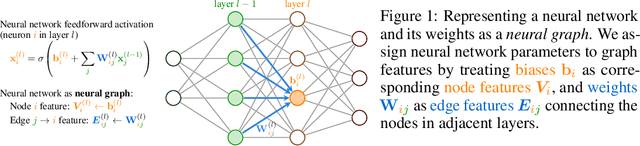
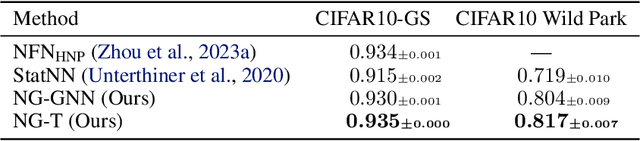
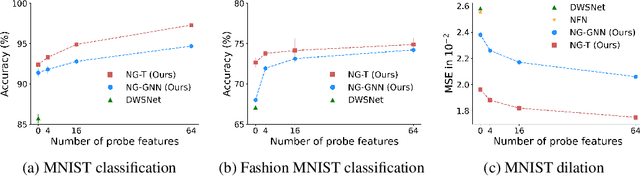
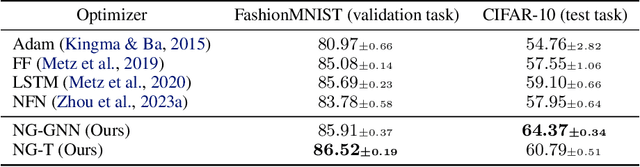
Neural networks that process the parameters of other neural networks find applications in domains as diverse as classifying implicit neural representations, generating neural network weights, and predicting generalization errors. However, existing approaches either overlook the inherent permutation symmetry in the neural network or rely on intricate weight-sharing patterns to achieve equivariance, while ignoring the impact of the network architecture itself. In this work, we propose to represent neural networks as computational graphs of parameters, which allows us to harness powerful graph neural networks and transformers that preserve permutation symmetry. Consequently, our approach enables a single model to encode neural computational graphs with diverse architectures. We showcase the effectiveness of our method on a wide range of tasks, including classification and editing of implicit neural representations, predicting generalization performance, and learning to optimize, while consistently outperforming state-of-the-art methods. The source code is open-sourced at https://github.com/mkofinas/neural-graphs.
Data Augmentations in Deep Weight Spaces
Nov 15, 2023Learning in weight spaces, where neural networks process the weights of other deep neural networks, has emerged as a promising research direction with applications in various fields, from analyzing and editing neural fields and implicit neural representations, to network pruning and quantization. Recent works designed architectures for effective learning in that space, which takes into account its unique, permutation-equivariant, structure. Unfortunately, so far these architectures suffer from severe overfitting and were shown to benefit from large datasets. This poses a significant challenge because generating data for this learning setup is laborious and time-consuming since each data sample is a full set of network weights that has to be trained. In this paper, we address this difficulty by investigating data augmentations for weight spaces, a set of techniques that enable generating new data examples on the fly without having to train additional input weight space elements. We first review several recently proposed data augmentation schemes %that were proposed recently and divide them into categories. We then introduce a novel augmentation scheme based on the Mixup method. We evaluate the performance of these techniques on existing benchmarks as well as new benchmarks we generate, which can be valuable for future studies.
Unlocking Slot Attention by Changing Optimal Transport Costs
Jan 30, 2023Slot attention is a powerful method for object-centric modeling in images and videos. However, its set-equivariance limits its ability to handle videos with a dynamic number of objects because it cannot break ties. To overcome this limitation, we first establish a connection between slot attention and optimal transport. Based on this new perspective we propose MESH (Minimize Entropy of Sinkhorn): a cross-attention module that combines the tiebreaking properties of unregularized optimal transport with the speed of regularized optimal transport. We evaluate slot attention using MESH on multiple object-centric learning benchmarks and find significant improvements over slot attention in every setting.
Self-Guided Diffusion Models
Oct 12, 2022
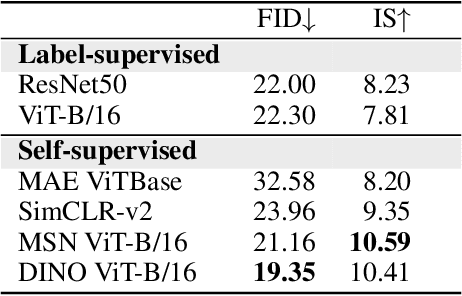
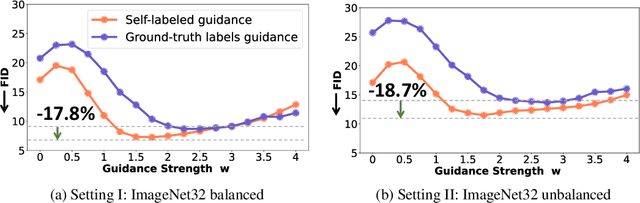

Diffusion models have demonstrated remarkable progress in image generation quality, especially when guidance is used to control the generative process. However, guidance requires a large amount of image-annotation pairs for training and is thus dependent on their availability, correctness and unbiasedness. In this paper, we eliminate the need for such annotation by instead leveraging the flexibility of self-supervision signals to design a framework for self-guided diffusion models. By leveraging a feature extraction function and a self-annotation function, our method provides guidance signals at various image granularities: from the level of holistic images to object boxes and even segmentation masks. Our experiments on single-label and multi-label image datasets demonstrate that self-labeled guidance always outperforms diffusion models without guidance and may even surpass guidance based on ground-truth labels, especially on unbalanced data. When equipped with self-supervised box or mask proposals, our method further generates visually diverse yet semantically consistent images, without the need for any class, box, or segment label annotation. Self-guided diffusion is simple, flexible and expected to profit from deployment at scale.
Maximum Class Separation as Inductive Bias in One Matrix
Jun 17, 2022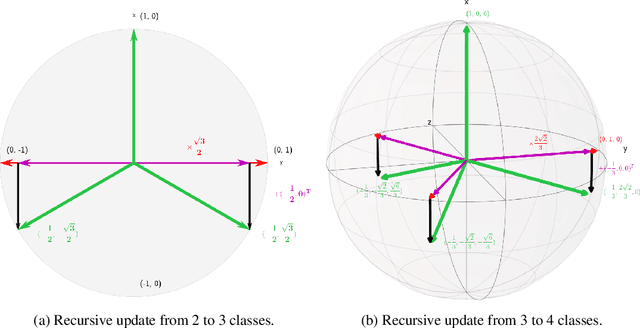
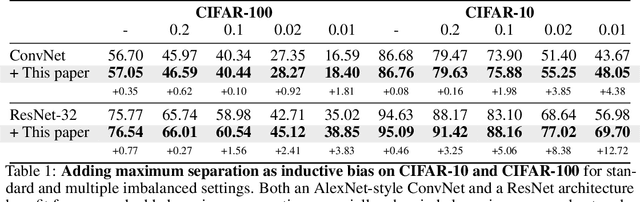
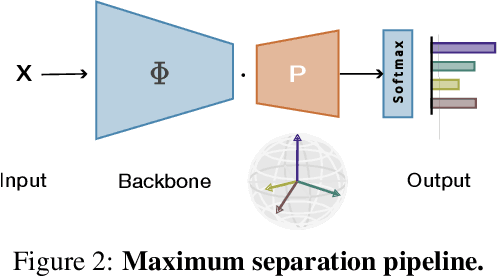
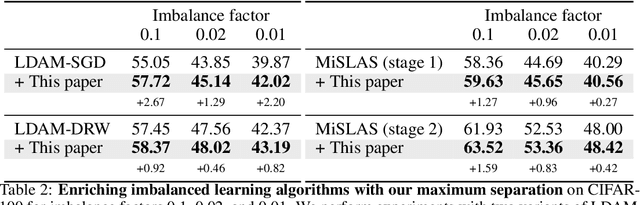
Maximizing the separation between classes constitutes a well-known inductive bias in machine learning and a pillar of many traditional algorithms. By default, deep networks are not equipped with this inductive bias and therefore many alternative solutions have been proposed through differential optimization. Current approaches tend to optimize classification and separation jointly: aligning inputs with class vectors and separating class vectors angularly. This paper proposes a simple alternative: encoding maximum separation as an inductive bias in the network by adding one fixed matrix multiplication before computing the softmax activations. The main observation behind our approach is that separation does not require optimization but can be solved in closed-form prior to training and plugged into a network. We outline a recursive approach to obtain the matrix consisting of maximally separable vectors for any number of classes, which can be added with negligible engineering effort and computational overhead. Despite its simple nature, this one matrix multiplication provides real impact. We show that our proposal directly boosts classification, long-tailed recognition, out-of-distribution detection, and open-set recognition, from CIFAR to ImageNet. We find empirically that maximum separation works best as a fixed bias; making the matrix learnable adds nothing to the performance. The closed-form implementation and code to reproduce the experiments are on github.
Multiset-Equivariant Set Prediction with Approximate Implicit Differentiation
Nov 23, 2021

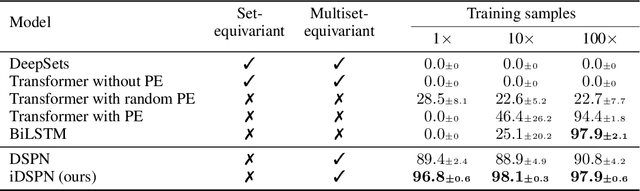
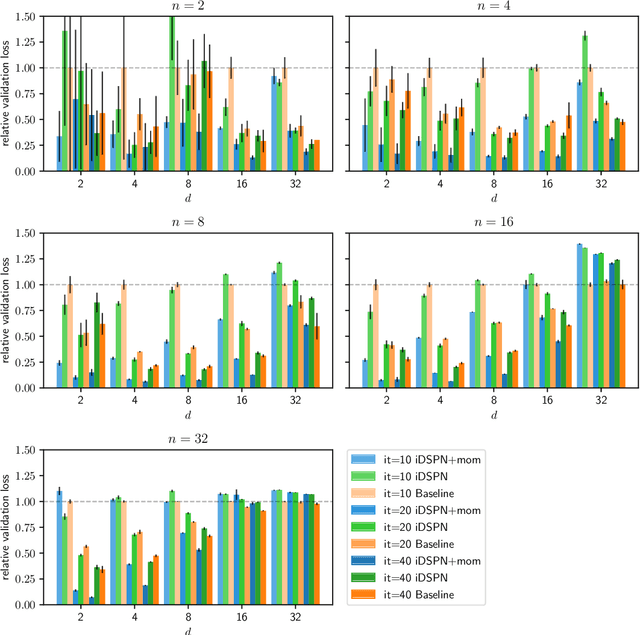
Most set prediction models in deep learning use set-equivariant operations, but they actually operate on multisets. We show that set-equivariant functions cannot represent certain functions on multisets, so we introduce the more appropriate notion of multiset-equivariance. We identify that the existing Deep Set Prediction Network (DSPN) can be multiset-equivariant without being hindered by set-equivariance and improve it with approximate implicit differentiation, allowing for better optimization while being faster and saving memory. In a range of toy experiments, we show that the perspective of multiset-equivariance is beneficial and that our changes to DSPN achieve better results in most cases. On CLEVR object property prediction, we substantially improve over the state-of-the-art Slot Attention from 8% to 77% in one of the strictest evaluation metrics because of the benefits made possible by implicit differentiation.
Recurrently Predicting Hypergraphs
Jun 26, 2021
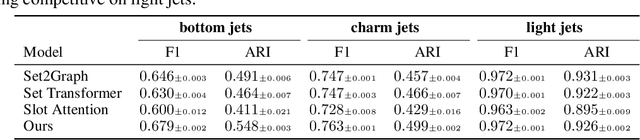
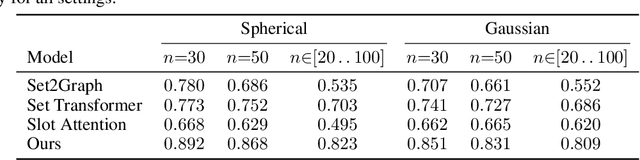

This work considers predicting the relational structure of a hypergraph for a given set of vertices, as common for applications in particle physics, biological systems and other complex combinatorial problems. A problem arises from the number of possible multi-way relationships, or hyperedges, scaling in $\mathcal{O}(2^n)$ for a set of $n$ elements. Simply storing an indicator tensor for all relationships is already intractable for moderately sized $n$, prompting previous approaches to restrict the number of vertices a hyperedge connects. Instead, we propose a recurrent hypergraph neural network that predicts the incidence matrix by iteratively refining an initial guess of the solution. We leverage the property that most hypergraphs of interest are sparsely connected and reduce the memory requirement to $\mathcal{O}(nk)$, where $k$ is the maximum number of positive edges, i.e., edges that actually exist. In order to counteract the linearly growing memory cost from training a lengthening sequence of refinement steps, we further propose an algorithm that applies backpropagation through time on randomly sampled subsequences. We empirically show that our method can match an increase in the intrinsic complexity without a performance decrease and demonstrate superior performance compared to state-of-the-art models.
Set Prediction without Imposing Structure as Conditional Density Estimation
Oct 08, 2020



Set prediction is about learning to predict a collection of unordered variables with unknown interrelations. Training such models with set losses imposes the structure of a metric space over sets. We focus on stochastic and underdefined cases, where an incorrectly chosen loss function leads to implausible predictions. Example tasks include conditional point-cloud reconstruction and predicting future states of molecules. In this paper, we propose an alternative to training via set losses by viewing learning as conditional density estimation. Our learning framework fits deep energy-based models and approximates the intractable likelihood with gradient-guided sampling. Furthermore, we propose a stochastically augmented prediction algorithm that enables multiple predictions, reflecting the possible variations in the target set. We empirically demonstrate on a variety of datasets the capability to learn multi-modal densities and produce multiple plausible predictions. Our approach is competitive with previous set prediction models on standard benchmarks. More importantly, it extends the family of addressable tasks beyond those that have unambiguous predictions.
Robotic Self-Assessment of Competence
May 04, 2020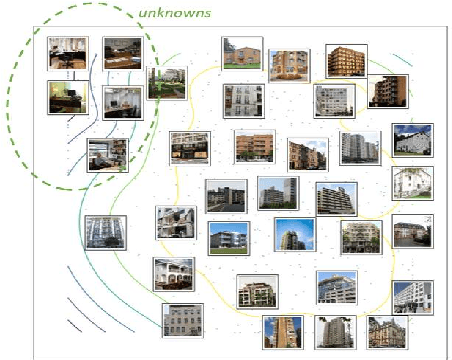


In robotics, one of the main challenges is that the on-board Artificial Intelligence (AI) must deal with different or unexpected environments. Such AI agents may be incompetent there, while the underlying model itself may not be aware of this (e.g., deep learning models are often overly confident). This paper proposes two methods for the online assessment of the competence of the AI model, respectively for situations when nothing is known about competence beforehand, and when there is prior knowledge about competence (in semantic form). The proposed method assesses whether the current environment is known. If not, it asks a human for feedback about its competence. If it knows the environment, it assesses its competence by generalizing from earlier experience. Results on real data show the merit of competence assessment for a robot moving through various environments in which it sometimes is competent and at other times it is not competent. We discuss the role of the human in robot's self-assessment of its competence, and the challenges to acquire complementary information from the human that reinforces the assessments.