 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo better language models have crisper vision?
Oct 09, 2024

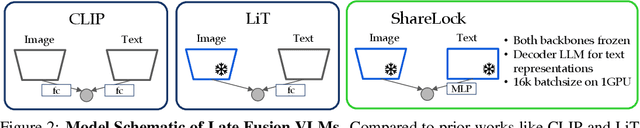

How well do text-only Large Language Models (LLMs) grasp the visual world? As LLMs are increasingly used in computer vision, addressing this question becomes both fundamental and pertinent. However, existing studies have primarily focused on limited scenarios, such as their ability to generate visual content or cluster multimodal data. To this end, we propose the Visual Text Representation Benchmark (ViTeRB) to isolate key properties that make language models well-aligned with the visual world. With this, we identify large-scale decoder-based LLMs as ideal candidates for representing text in vision-centric contexts, counter to the current practice of utilizing text encoders. Building on these findings, we propose ShareLock, an ultra-lightweight CLIP-like model. By leveraging precomputable frozen features from strong vision and language models, ShareLock achieves an impressive 51% accuracy on ImageNet despite utilizing just 563k image-caption pairs. Moreover, training requires only 1 GPU hour (or 10 hours including the precomputation of features) - orders of magnitude less than prior methods. Code will be released.
A System-driven Automatic Ground Truth Generation Method for DL Inner-City Driving Corridor Detectors
Jul 20, 2022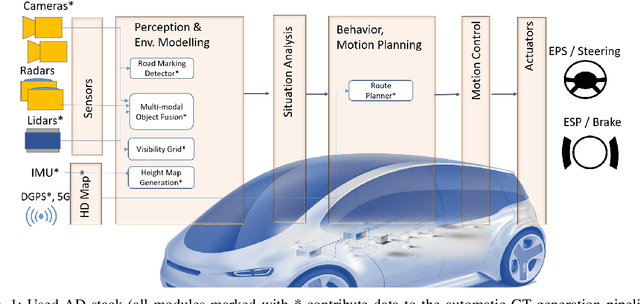

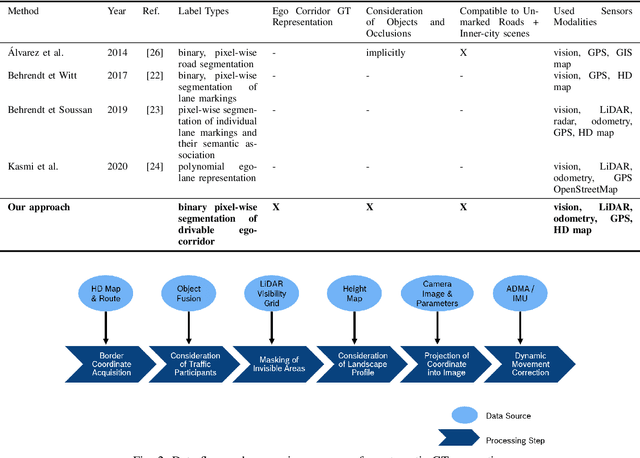
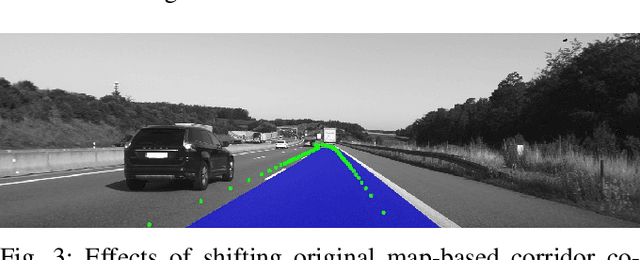
Data-driven perception approaches are well-established in automated driving systems. In many fields even super-human performance is reached. Unlike prediction and planning approaches, mainly supervised learning algorithms are used for the perception domain. Therefore, a major remaining challenge is the efficient generation of ground truth data. As perception modules are positioned close to the sensor, they typically run on raw sensor data of high bandwidth. Due to that, the generation of ground truth labels typically causes a significant manual effort, which leads to high costs for the labelling itself and the necessary quality control. In this contribution, we propose an automatic labeling approach for semantic segmentation of the drivable ego corridor that reduces the manual effort by a factor of 150 and more. The proposed holistic approach could be used in an automated data loop, allowing a continuous improvement of the depending perception modules.
* 8 pages