 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Intensity-Neuromorphic Event Imaging System for Resource Constrained Devices
May 29, 2021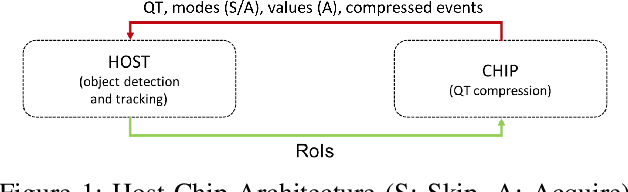
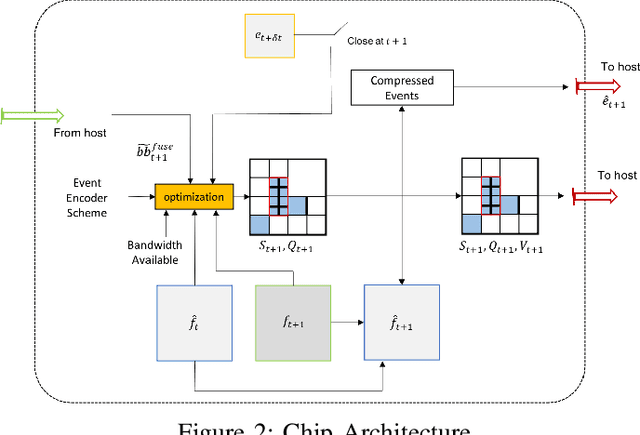
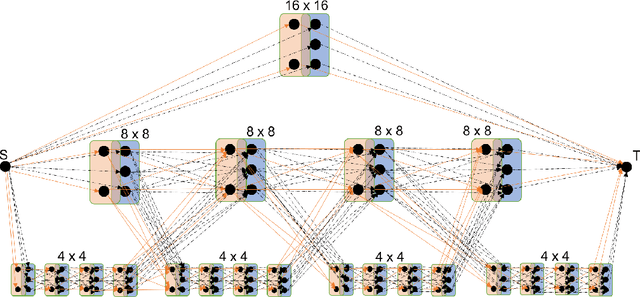
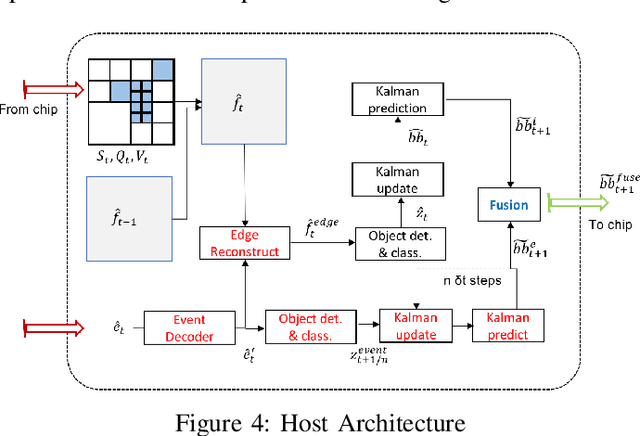
We present a novel adaptive multi-modal intensity-event algorithm to optimize an overall objective of object tracking under bit rate constraints for a host-chip architecture. The chip is a computationally resource constrained device acquiring high resolution intensity frames and events, while the host is capable of performing computationally expensive tasks. We develop a joint intensity-neuromorphic event rate-distortion compression framework with a quadtree (QT) based compression of intensity and events scheme. The data acquisition on the chip is driven by the presence of objects of interest in the scene as detected by an object detector. The most informative intensity and event data are communicated to the host under rate constraints, so that the best possible tracking performance is obtained. The detection and tracking of objects in the scene are done on the distorted data at the host. Intensity and events are jointly used in a fusion framework to enhance the quality of the distorted images, so as to improve the object detection and tracking performance. The performance assessment of the overall system is done in terms of the multiple object tracking accuracy (MOTA) score. Compared to using intensity modality only, there is an improvement in MOTA using both these modalities in different scenarios.
E3D: Event-Based 3D Shape Reconstruction
Dec 10, 2020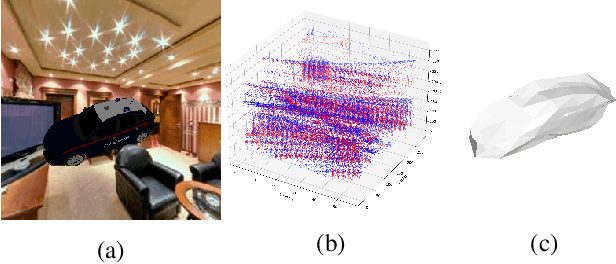
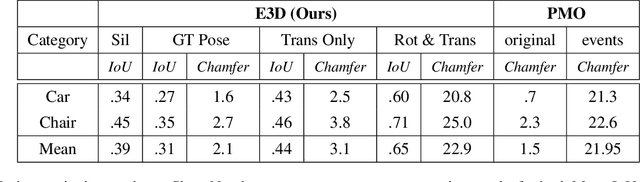


3D shape reconstruction is a primary component of augmented/virtual reality. Despite being highly advanced, existing solutions based on RGB, RGB-D and Lidar sensors are power and data intensive, which introduces challenges for deployment in edge devices. We approach 3D reconstruction with an event camera, a sensor with significantly lower power, latency and data expense while enabling high dynamic range. While previous event-based 3D reconstruction methods are primarily based on stereo vision, we cast the problem as multi-view shape from silhouette using a monocular event camera. The output from a moving event camera is a sparse point set of space-time gradients, largely sketching scene/object edges and contours. We first introduce an event-to-silhouette (E2S) neural network module to transform a stack of event frames to the corresponding silhouettes, with additional neural branches for camera pose regression. Second, we introduce E3D, which employs a 3D differentiable renderer (PyTorch3D) to enforce cross-view 3D mesh consistency and fine-tune the E2S and pose network. Lastly, we introduce a 3D-to-events simulation pipeline and apply it to publicly available object datasets and generate synthetic event/silhouette training pairs for supervised learning.
Quadtree Driven Lossy Event Compression
May 03, 2020

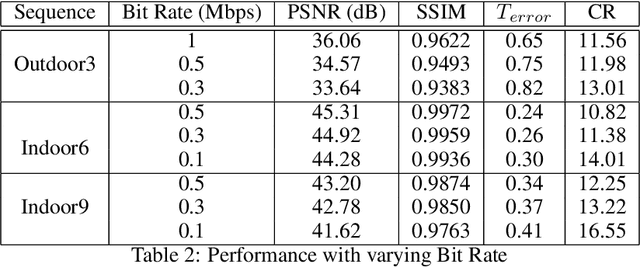
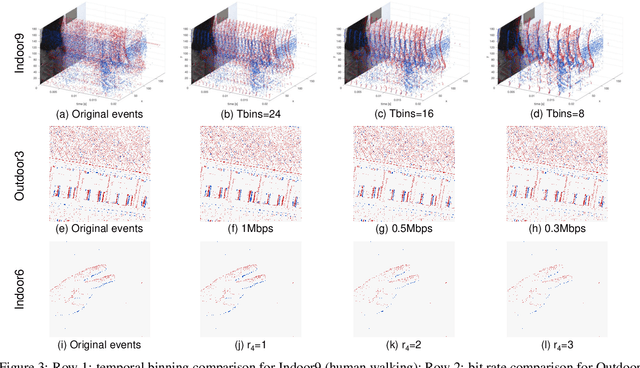
Event cameras are emerging bio-inspired sensors that offer salient benefits over traditional cameras. With high speed, high dynamic range, and low power consumption, event cameras have been increasingly employed to solve existing as well as novel visual and robotics tasks. Despite rapid advancement in event-based vision, event data compression is facing growing demand, yet remains elusively challenging and not effectively addressed. The major challenge is the unique data form, \emph{i.e.}, a stream of four-attribute events, encoding the spatial locations and the timestamp of each event, with a polarity representing the brightness increase/decrease. While events encode temporal variations at high speed, they omit rich spatial information, which is critical for image/video compression. In this paper, we perform lossy event compression (LEC) based on a quadtree (QT) segmentation map derived from an adjacent image. The QT structure provides a priority map for the 3D space-time volume, albeit in a 2D manner. LEC is performed by first quantizing the events over time, and then variably compressing the events within each QT block via Poisson Disk Sampling in 2D space for each quantized time. Our QT-LEC has flexibility in accordance with the bit-rate requirement. Experimentally, we show results with state-of-the-art coding performance. We further evaluate the performance in event-based applications such as image reconstruction and corner detection.
Privacy-Preserving Action Recognition using Coded Aperture Videos
Apr 16, 2019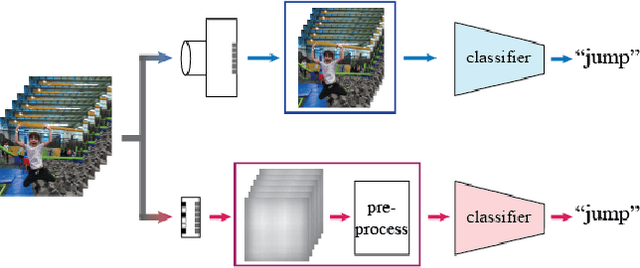
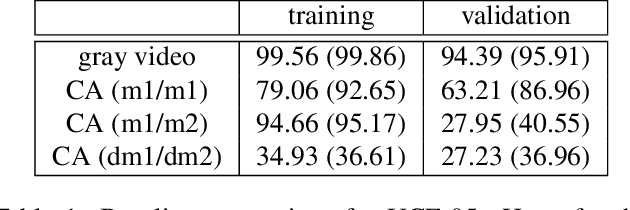
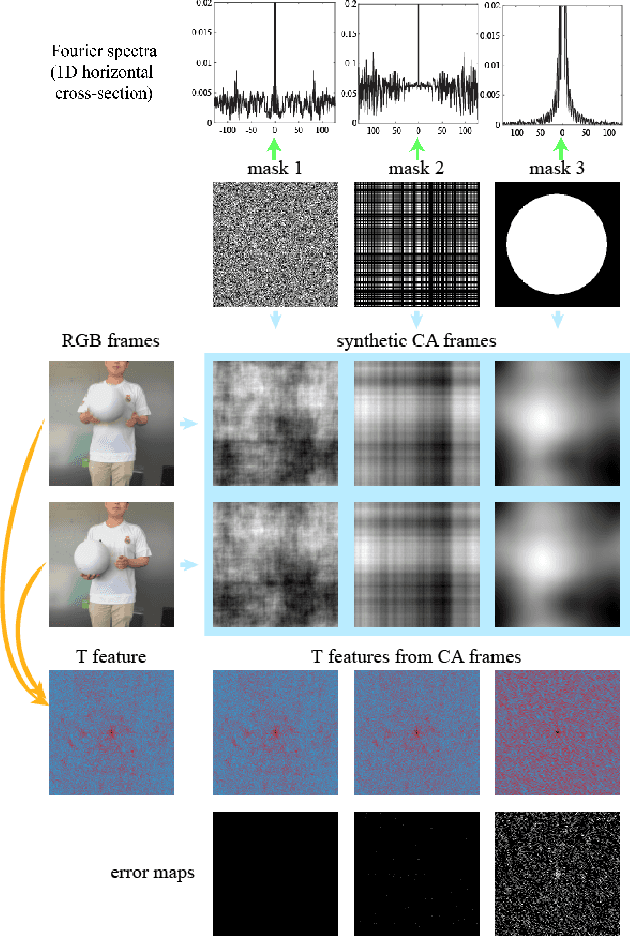
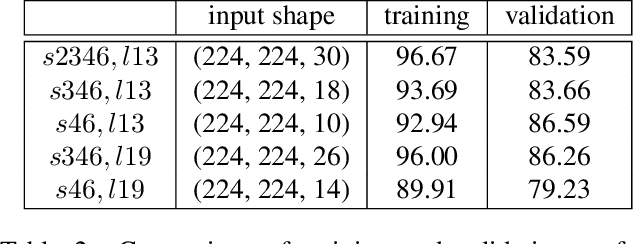
The risk of unauthorized remote access of streaming video from networked cameras underlines the need for stronger privacy safeguards. We propose a lens-free coded aperture camera system for human action recognition that is privacy-preserving. While coded aperture systems exist, we believe ours is the first system designed for action recognition without the need for image restoration as an intermediate step. Action recognition is done using a deep network that takes in as input, non-invertible motion features between pairs of frames computed using phase correlation and log-polar transformation. Phase correlation encodes translation while the log polar transformation encodes in-plane rotation and scaling. We show that the translation features are independent of the coded aperture design, as long as its spectral response within the bandwidth has no zeros. Stacking motion features computed on frames at multiple different strides in the video can improve accuracy. Preliminary results on simulated data based on a subset of the UCF and NTU datasets are promising. We also describe our prototype lens-free coded aperture camera system, and results for real captured videos are mixed.