 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBokeh-Loss GAN: Multi-Stage Adversarial Training for Realistic Edge-Aware Bokeh
Aug 25, 2022
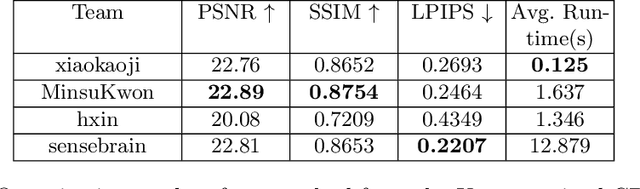
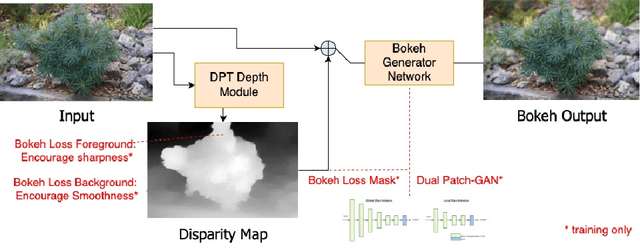
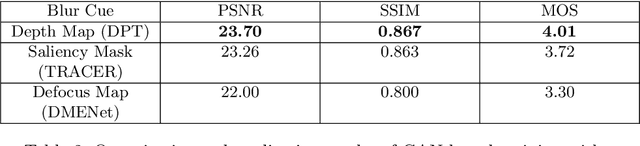
In this paper, we tackle the problem of monocular bokeh synthesis, where we attempt to render a shallow depth of field image from a single all-in-focus image. Unlike in DSLR cameras, this effect can not be captured directly in mobile cameras due to the physical constraints of the mobile aperture. We thus propose a network-based approach that is capable of rendering realistic monocular bokeh from single image inputs. To do this, we introduce three new edge-aware Bokeh Losses based on a predicted monocular depth map, that sharpens the foreground edges while blurring the background. This model is then finetuned using an adversarial loss to generate a realistic Bokeh effect. Experimental results show that our approach is capable of generating a pleasing, natural Bokeh effect with sharp edges while handling complicated scenes.
E3D: Event-Based 3D Shape Reconstruction
Dec 10, 2020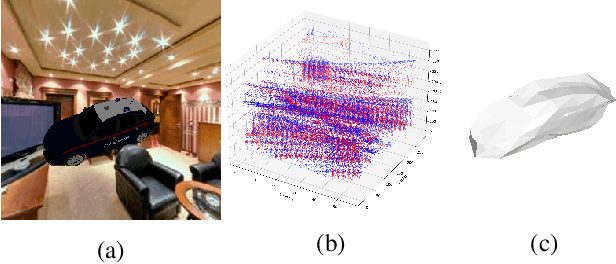
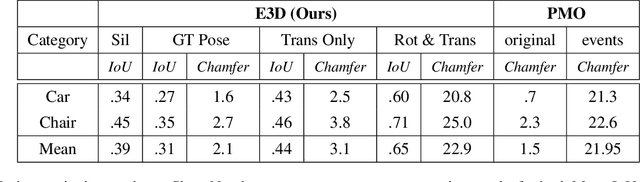


3D shape reconstruction is a primary component of augmented/virtual reality. Despite being highly advanced, existing solutions based on RGB, RGB-D and Lidar sensors are power and data intensive, which introduces challenges for deployment in edge devices. We approach 3D reconstruction with an event camera, a sensor with significantly lower power, latency and data expense while enabling high dynamic range. While previous event-based 3D reconstruction methods are primarily based on stereo vision, we cast the problem as multi-view shape from silhouette using a monocular event camera. The output from a moving event camera is a sparse point set of space-time gradients, largely sketching scene/object edges and contours. We first introduce an event-to-silhouette (E2S) neural network module to transform a stack of event frames to the corresponding silhouettes, with additional neural branches for camera pose regression. Second, we introduce E3D, which employs a 3D differentiable renderer (PyTorch3D) to enforce cross-view 3D mesh consistency and fine-tune the E2S and pose network. Lastly, we introduce a 3D-to-events simulation pipeline and apply it to publicly available object datasets and generate synthetic event/silhouette training pairs for supervised learning.