 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFlow: Transformer as Flow Learner
Apr 23, 2023



Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation.
Generating Aligned Pseudo-Supervision from Non-Aligned Data for Image Restoration in Under-Display Camera
Apr 12, 2023Due to the difficulty in collecting large-scale and perfectly aligned paired training data for Under-Display Camera (UDC) image restoration, previous methods resort to monitor-based image systems or simulation-based methods, sacrificing the realness of the data and introducing domain gaps. In this work, we revisit the classic stereo setup for training data collection -- capturing two images of the same scene with one UDC and one standard camera. The key idea is to "copy" details from a high-quality reference image and "paste" them on the UDC image. While being able to generate real training pairs, this setting is susceptible to spatial misalignment due to perspective and depth of field changes. The problem is further compounded by the large domain discrepancy between the UDC and normal images, which is unique to UDC restoration. In this paper, we mitigate the non-trivial domain discrepancy and spatial misalignment through a novel Transformer-based framework that generates well-aligned yet high-quality target data for the corresponding UDC input. This is made possible through two carefully designed components, namely, the Domain Alignment Module (DAM) and Geometric Alignment Module (GAM), which encourage robust and accurate discovery of correspondence between the UDC and normal views. Extensive experiments show that high-quality and well-aligned pseudo UDC training pairs are beneficial for training a robust restoration network. Code and the dataset are available at https://github.com/jnjaby/AlignFormer.
Joint Multi-Scale Tone Mapping and Denoising for HDR Image Enhancement
Mar 23, 2023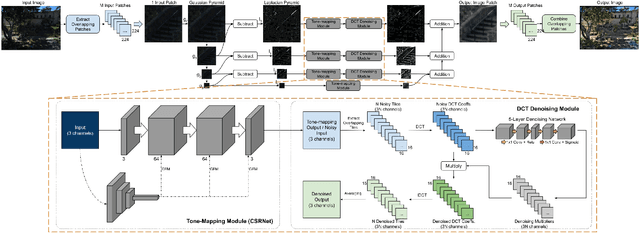

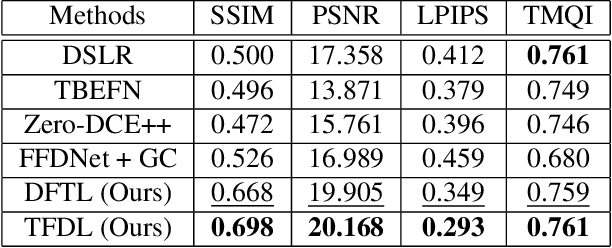
An image processing unit (IPU), or image signal processor (ISP) for high dynamic range (HDR) imaging usually consists of demosaicing, white balancing, lens shading correction, color correction, denoising, and tone-mapping. Besides noise from the imaging sensors, almost every step in the ISP introduces or amplifies noise in different ways, and denoising operators are designed to reduce the noise from these sources. Designed for dynamic range compressing, tone-mapping operators in an ISP can significantly amplify the noise level, especially for images captured in low-light conditions, making denoising very difficult. Therefore, we propose a joint multi-scale denoising and tone-mapping framework that is designed with both operations in mind for HDR images. Our joint network is trained in an end-to-end format that optimizes both operators together, to prevent the tone-mapping operator from overwhelming the denoising operator. Our model outperforms existing HDR denoising and tone-mapping operators both quantitatively and qualitatively on most of our benchmarking datasets.
Realistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.
Bokeh-Loss GAN: Multi-Stage Adversarial Training for Realistic Edge-Aware Bokeh
Aug 25, 2022
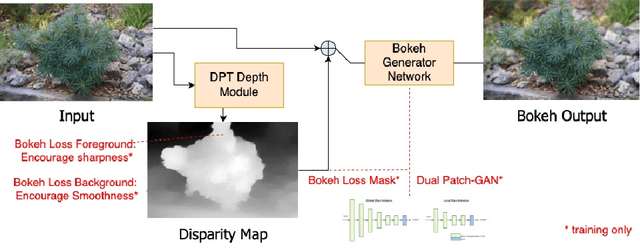
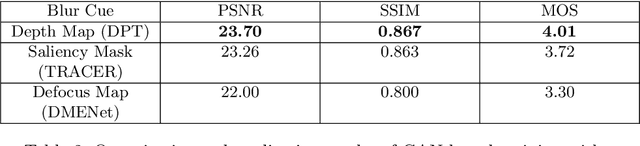
In this paper, we tackle the problem of monocular bokeh synthesis, where we attempt to render a shallow depth of field image from a single all-in-focus image. Unlike in DSLR cameras, this effect can not be captured directly in mobile cameras due to the physical constraints of the mobile aperture. We thus propose a network-based approach that is capable of rendering realistic monocular bokeh from single image inputs. To do this, we introduce three new edge-aware Bokeh Losses based on a predicted monocular depth map, that sharpens the foreground edges while blurring the background. This model is then finetuned using an adversarial loss to generate a realistic Bokeh effect. Experimental results show that our approach is capable of generating a pleasing, natural Bokeh effect with sharp edges while handling complicated scenes.
Deep Camera Obscura: An Image Restoration Pipeline for Lensless Pinhole Photography
Aug 12, 2021The lensless pinhole camera is perhaps the earliest and simplest form of an imaging system using only a pinhole-sized aperture in place of a lens. They can capture an infinite depth-of-field and offer greater freedom from optical distortion over their lens-based counterparts. However, the inherent limitations of a pinhole system result in lower sharpness from blur caused by optical diffraction and higher noise levels due to low light throughput of the small aperture, requiring very long exposure times to capture well-exposed images. In this paper, we explore an image restoration pipeline using deep learning and domain-knowledge of the pinhole system to enhance the pinhole image quality through a joint denoise and deblur approach. Our approach allows for more practical exposure times for hand-held photography and provides higher image quality, making it more suitable for daily photography compared to other lensless cameras while keeping size and cost low. This opens up the potential of pinhole cameras to be used in smaller devices, such as smartphones.
Removing Diffraction Image Artifacts in Under-Display Camera via Dynamic Skip Connection Network
Apr 19, 2021


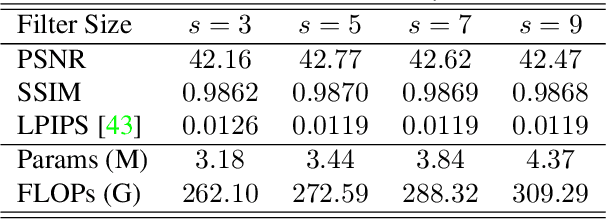
Recent development of Under-Display Camera (UDC) systems provides a true bezel-less and notch-free viewing experience on smartphones (and TV, laptops, tablets), while allowing images to be captured from the selfie camera embedded underneath. In a typical UDC system, the microstructure of the semi-transparent organic light-emitting diode (OLED) pixel array attenuates and diffracts the incident light on the camera, resulting in significant image quality degradation. Oftentimes, noise, flare, haze, and blur can be observed in UDC images. In this work, we aim to analyze and tackle the aforementioned degradation problems. We define a physics-based image formation model to better understand the degradation. In addition, we utilize one of the world's first commodity UDC smartphone prototypes to measure the real-world Point Spread Function (PSF) of the UDC system, and provide a model-based data synthesis pipeline to generate realistically degraded images. We specially design a new domain knowledge-enabled Dynamic Skip Connection Network (DISCNet) to restore the UDC images. We demonstrate the effectiveness of our method through extensive experiments on both synthetic and real UDC data. Our physics-based image formation model and proposed DISCNet can provide foundations for further exploration in UDC image restoration, and even for general diffraction artifact removal in a broader sense.
iToF2dToF: A Robust and Flexible Representation for Data-Driven Time-of-Flight Imaging
Mar 12, 2021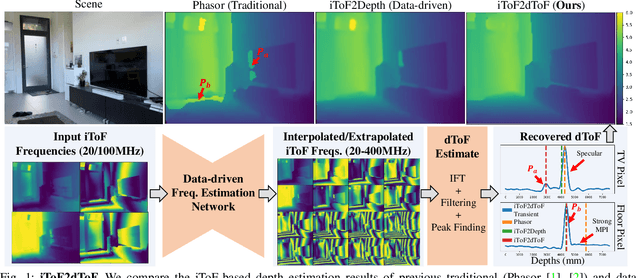
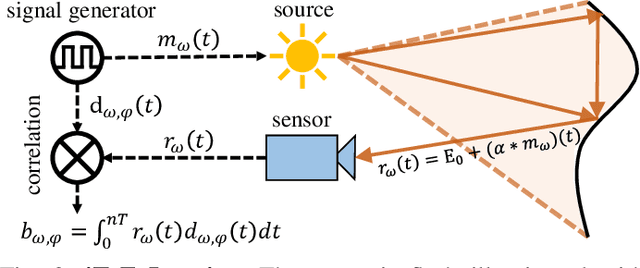
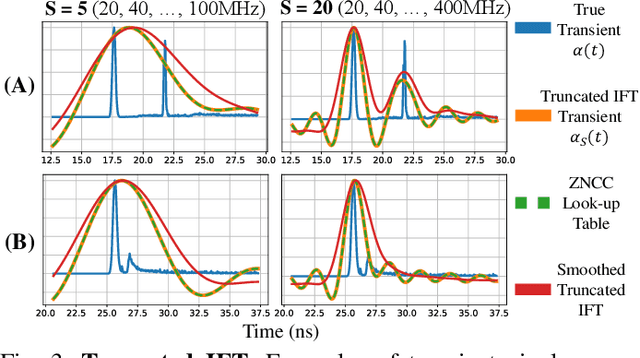
Indirect Time-of-Flight (iToF) cameras are a promising depth sensing technology. However, they are prone to errors caused by multi-path interference (MPI) and low signal-to-noise ratio (SNR). Traditional methods, after denoising, mitigate MPI by estimating a transient image that encodes depths. Recently, data-driven methods that jointly denoise and mitigate MPI have become state-of-the-art without using the intermediate transient representation. In this paper, we propose to revisit the transient representation. Using data-driven priors, we interpolate/extrapolate iToF frequencies and use them to estimate the transient image. Given direct ToF (dToF) sensors capture transient images, we name our method iToF2dToF. The transient representation is flexible. It can be integrated with different rule-based depth sensing algorithms that are robust to low SNR and can deal with ambiguous scenarios that arise in practice (e.g., specular MPI, optical cross-talk). We demonstrate the benefits of iToF2dToF over previous methods in real depth sensing scenarios.
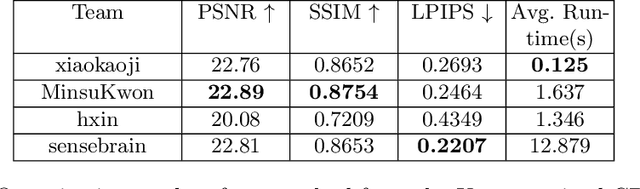
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020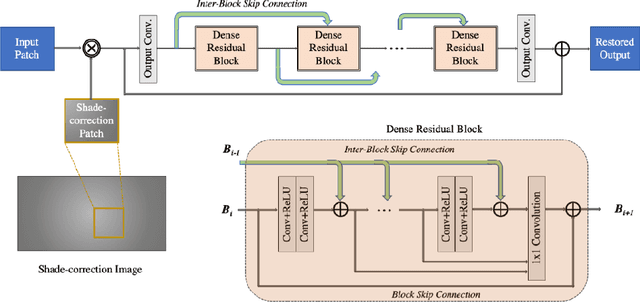
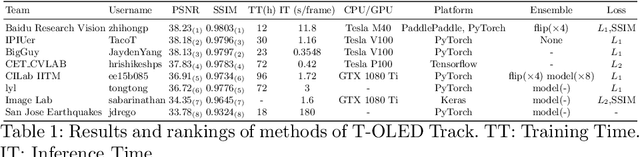
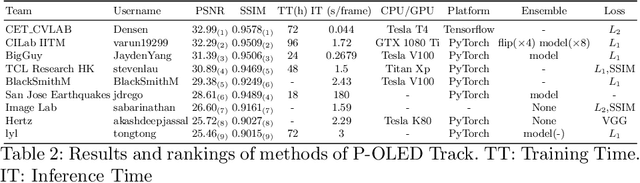
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
JPAD-SE: High-Level Semantics for Joint Perception-Accuracy-Distortion Enhancement in Image Compression
May 29, 2020
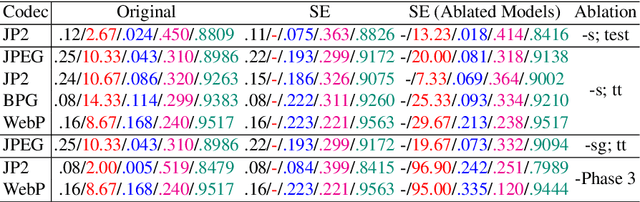

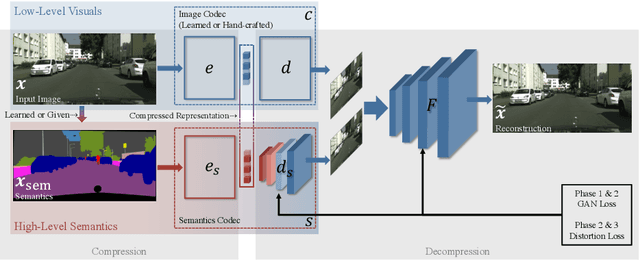
While humans can effortlessly transform complex visual scenes into simple words and the other way around by leveraging their high-level understanding of the content, conventional or the more recent learned image compression codecs do not seem to utilize the semantic meanings of visual content to its full potential. Moreover, they focus mostly on rate-distortion and tend to underperform in perception quality especially in low bitrate regime, and often disregard the performance of downstream computer vision algorithms, which is a fast-growing consumer group of compressed images in addition to human viewers. In this paper, we (1) present a generic framework that can enable any image codec to leverage high-level semantics, and (2) study the joint optimization of perception quality, accuracy of downstream computer vision task, and distortion. Our idea is that given any codec, we utilize high-level semantics to augment the low-level visual features extracted by it and produce essentially a new, semantic-aware codec. And we argue that semantic enhancement implicitly optimizes rate-perception-accuracy-distortion (R-PAD) performance. To validate our claim, we perform extensive empirical evaluations and provide both quantitative and qualitative results.