 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJPAD-SE: High-Level Semantics for Joint Perception-Accuracy-Distortion Enhancement in Image Compression
Paper and Code

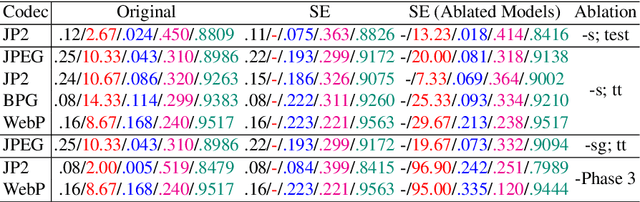

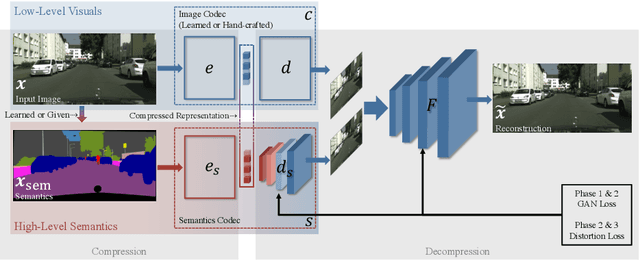
While humans can effortlessly transform complex visual scenes into simple words and the other way around by leveraging their high-level understanding of the content, conventional or the more recent learned image compression codecs do not seem to utilize the semantic meanings of visual content to its full potential. Moreover, they focus mostly on rate-distortion and tend to underperform in perception quality especially in low bitrate regime, and often disregard the performance of downstream computer vision algorithms, which is a fast-growing consumer group of compressed images in addition to human viewers. In this paper, we (1) present a generic framework that can enable any image codec to leverage high-level semantics, and (2) study the joint optimization of perception quality, accuracy of downstream computer vision task, and distortion. Our idea is that given any codec, we utilize high-level semantics to augment the low-level visual features extracted by it and produce essentially a new, semantic-aware codec. And we argue that semantic enhancement implicitly optimizes rate-perception-accuracy-distortion (R-PAD) performance. To validate our claim, we perform extensive empirical evaluations and provide both quantitative and qualitative results.