 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHOR: Thermal-guided Hand-Object Reasoning via Adaptive Vision Sampling
Jul 08, 2025



Wearable cameras are increasingly used as an observational and interventional tool for human behaviors by providing detailed visual data of hand-related activities. This data can be leveraged to facilitate memory recall for logging of behavior or timely interventions aimed at improving health. However, continuous processing of RGB images from these cameras consumes significant power impacting battery lifetime, generates a large volume of unnecessary video data for post-processing, raises privacy concerns, and requires substantial computational resources for real-time analysis. We introduce THOR, a real-time adaptive spatio-temporal RGB frame sampling method that leverages thermal sensing to capture hand-object patches and classify them in real-time. We use low-resolution thermal camera data to identify moments when a person switches from one hand-related activity to another, and adjust the RGB frame sampling rate by increasing it during activity transitions and reducing it during periods of sustained activity. Additionally, we use the thermal cues from the hand to localize the region of interest (i.e., the hand-object interaction) in each RGB frame, allowing the system to crop and process only the necessary part of the image for activity recognition. We develop a wearable device to validate our method through an in-the-wild study with 14 participants and over 30 activities, and further evaluate it on Ego4D (923 participants across 9 countries, totaling 3,670 hours of video). Our results show that using only 3% of the original RGB video data, our method captures all the activity segments, and achieves hand-related activity recognition F1-score (95%) comparable to using the entire RGB video (94%). Our work provides a more practical path for the longitudinal use of wearable cameras to monitor hand-related activities and health-risk behaviors in real time.
CPDR: Towards Highly-Efficient Salient Object Detection via Crossed Post-decoder Refinement
Jan 11, 2025



Most of the current salient object detection approaches use deeper networks with large backbones to produce more accurate predictions, which results in a significant increase in computational complexity. A great number of network designs follow the pure UNet and Feature Pyramid Network (FPN) architecture which has limited feature extraction and aggregation ability which motivated us to design a lightweight post-decoder refinement module, the crossed post-decoder refinement (CPDR) to enhance the feature representation of a standard FPN or U-Net framework. Specifically, we introduce the Attention Down Sample Fusion (ADF), which employs channel attention mechanisms with attention maps generated by high-level representation to refine the low-level features, and Attention Up Sample Fusion (AUF), leveraging the low-level information to guide the high-level features through spatial attention. Additionally, we proposed the Dual Attention Cross Fusion (DACF) upon ADFs and AUFs, which reduces the number of parameters while maintaining the performance. Experiments on five benchmark datasets demonstrate that our method outperforms previous state-of-the-art approaches.
* 14 pages
Emulators for stellar profiles in binary population modeling
Oct 14, 2024



Knowledge about the internal physical structure of stars is crucial to understanding their evolution. The novel binary population synthesis code POSYDON includes a module for interpolating the stellar and binary properties of any system at the end of binary MESA evolution based on a pre-computed set of models. In this work, we present a new emulation method for predicting stellar profiles, i.e., the internal stellar structure along the radial axis, using machine learning techniques. We use principal component analysis for dimensionality reduction and fully-connected feed-forward neural networks for making predictions. We find accuracy to be comparable to that of nearest neighbor approximation, with a strong advantage in terms of memory and storage efficiency. By delivering more information about the evolution of stellar internal structure, these emulators will enable faster simulations of higher physical fidelity with large-scale simulations of binary star population synthesis possible with POSYDON and other population synthesis codes.
Event-based Shape from Polarization with Spiking Neural Networks
Dec 26, 2023Recent advances in event-based shape determination from polarization offer a transformative approach that tackles the trade-off between speed and accuracy in capturing surface geometries. In this paper, we investigate event-based shape from polarization using Spiking Neural Networks (SNNs), introducing the Single-Timestep and Multi-Timestep Spiking UNets for effective and efficient surface normal estimation. Specificially, the Single-Timestep model processes event-based shape as a non-temporal task, updating the membrane potential of each spiking neuron only once, thereby reducing computational and energy demands. In contrast, the Multi-Timestep model exploits temporal dynamics for enhanced data extraction. Extensive evaluations on synthetic and real-world datasets demonstrate that our models match the performance of state-of-the-art Artifical Neural Networks (ANNs) in estimating surface normals, with the added advantage of superior energy efficiency. Our work not only contributes to the advancement of SNNs in event-based sensing but also sets the stage for future explorations in optimizing SNN architectures, integrating multi-modal data, and scaling for applications on neuromorphic hardware.
StenUNet: Automatic Stenosis Detection from X-ray Coronary Angiography
Oct 23, 2023



Coronary angiography continues to serve as the primary method for diagnosing coronary artery disease (CAD), which is the leading global cause of mortality. The severity of CAD is quantified by the location, degree of narrowing (stenosis), and number of arteries involved. In current practice, this quantification is performed manually using visual inspection and thus suffers from poor inter- and intra-rater reliability. The MICCAI grand challenge: Automatic Region-based Coronary Artery Disease diagnostics using the X-ray angiography imagEs (ARCADE) curated a dataset with stenosis annotations, with the goal of creating an automated stenosis detection algorithm. Using a combination of machine learning and other computer vision techniques, we propose the architecture and algorithm StenUNet to accurately detect stenosis from X-ray Coronary Angiography. Our submission to the ARCADE challenge placed 3rd among all teams. We achieved an F1 score of 0.5348 on the test set, 0.0005 lower than the 2nd place.
Thermal Spread Functions (TSF): Physics-guided Material Classification
Apr 03, 2023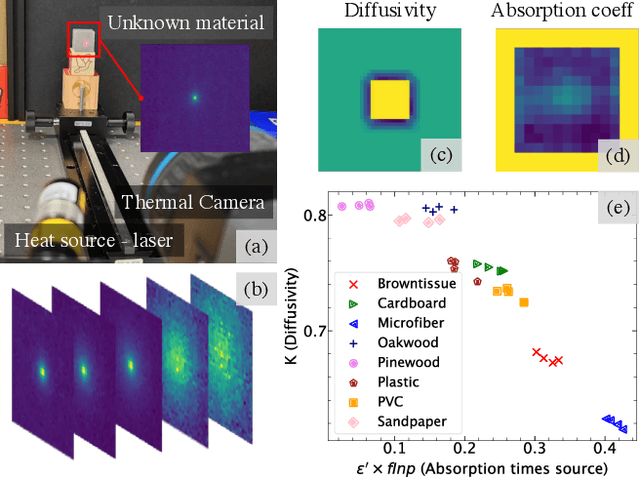
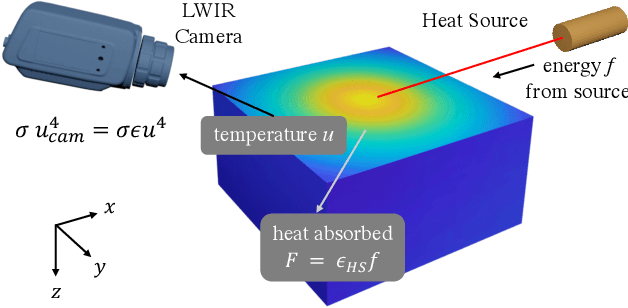
Robust and non-destructive material classification is a challenging but crucial first-step in numerous vision applications. We propose a physics-guided material classification framework that relies on thermal properties of the object. Our key observation is that the rate of heating and cooling of an object depends on the unique intrinsic properties of the material, namely the emissivity and diffusivity. We leverage this observation by gently heating the objects in the scene with a low-power laser for a fixed duration and then turning it off, while a thermal camera captures measurements during the heating and cooling process. We then take this spatial and temporal "thermal spread function" (TSF) to solve an inverse heat equation using the finite-differences approach, resulting in a spatially varying estimate of diffusivity and emissivity. These tuples are then used to train a classifier that produces a fine-grained material label at each spatial pixel. Our approach is extremely simple requiring only a small light source (low power laser) and a thermal camera, and produces robust classification results with 86% accuracy over 16 classes.
BKinD-3D: Self-Supervised 3D Keypoint Discovery from Multi-View Videos
Dec 14, 2022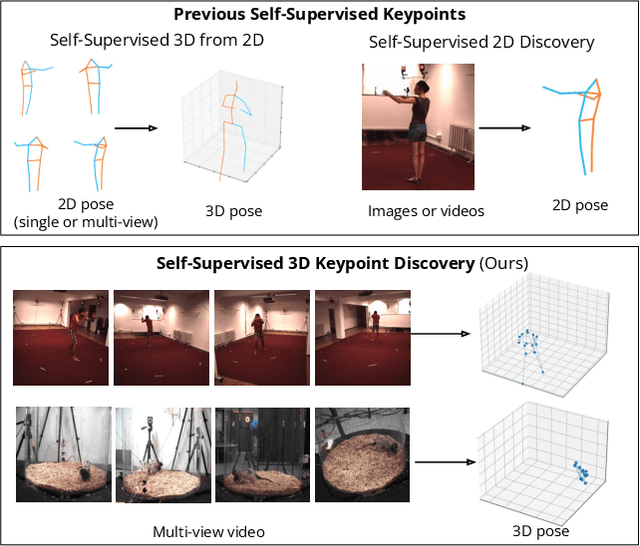
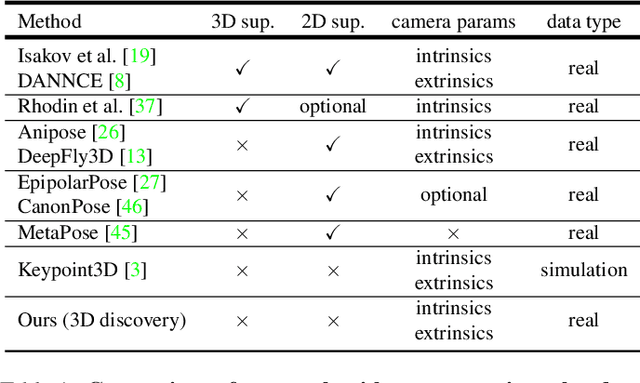
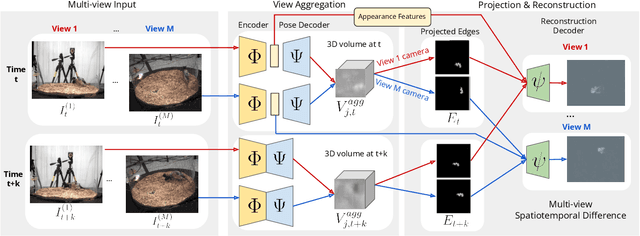
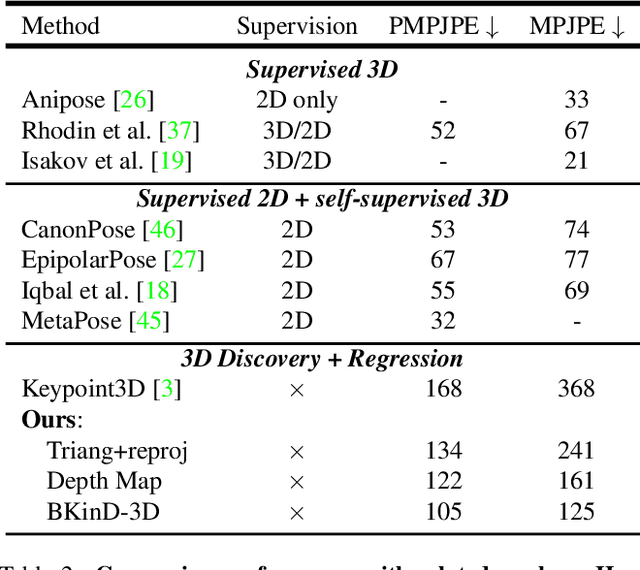
Quantifying motion in 3D is important for studying the behavior of humans and other animals, but manual pose annotations are expensive and time-consuming to obtain. Self-supervised keypoint discovery is a promising strategy for estimating 3D poses without annotations. However, current keypoint discovery approaches commonly process single 2D views and do not operate in the 3D space. We propose a new method to perform self-supervised keypoint discovery in 3D from multi-view videos of behaving agents, without any keypoint or bounding box supervision in 2D or 3D. Our method uses an encoder-decoder architecture with a 3D volumetric heatmap, trained to reconstruct spatiotemporal differences across multiple views, in addition to joint length constraints on a learned 3D skeleton of the subject. In this way, we discover keypoints without requiring manual supervision in videos of humans and rats, demonstrating the potential of 3D keypoint discovery for studying behavior.
Event-Driven Tactile Learning with Various Location Spiking Neurons
Oct 11, 2022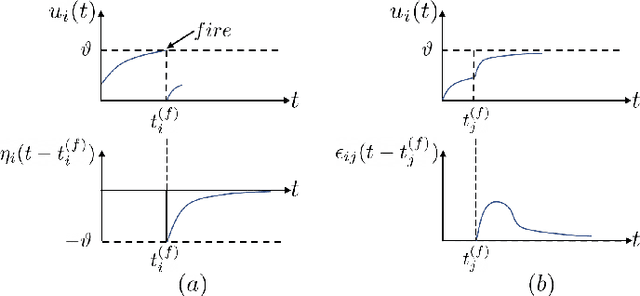
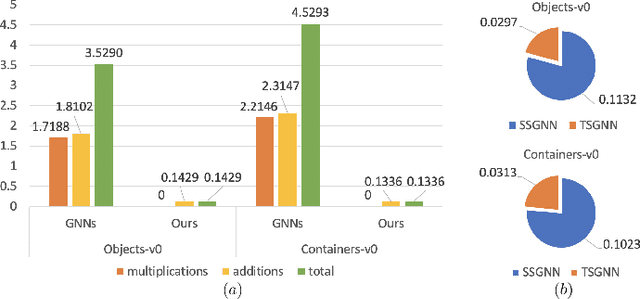
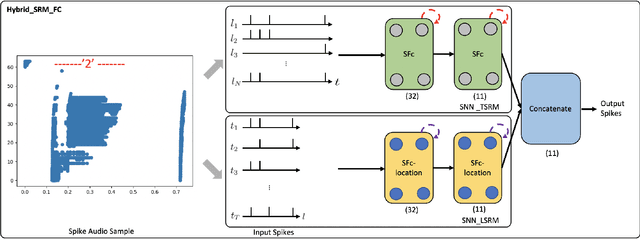
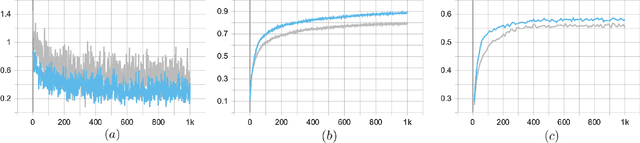
Tactile sensing is essential for a variety of daily tasks. New advances in event-driven tactile sensors and Spiking Neural Networks (SNNs) spur the research in related fields. However, SNN-enabled event-driven tactile learning is still in its infancy due to the limited representation abilities of existing spiking neurons and high spatio-temporal complexity in the data. In this paper, to improve the representation capability of existing spiking neurons, we propose a novel neuron model called "location spiking neuron", which enables us to extract features of event-based data in a novel way. Specifically, based on the classical Time Spike Response Model (TSRM), we develop the Location Spike Response Model (LSRM). In addition, based on the most commonly-used Time Leaky Integrate-and-Fire (TLIF) model, we develop the Location Leaky Integrate-and-Fire (LLIF) model. By exploiting the novel location spiking neurons, we propose several models to capture the complex spatio-temporal dependencies in the event-driven tactile data. Extensive experiments demonstrate the significant improvements of our models over other works on event-driven tactile learning and show the superior energy efficiency of our models and location spiking neurons, which may unlock their potential on neuromorphic hardware.
Can Deep Learning Assist Automatic Identification of Layered Pigments From XRF Data?
Jul 26, 2022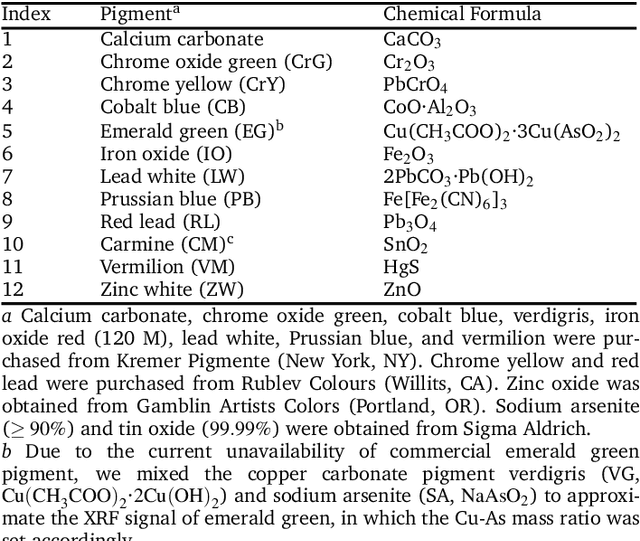
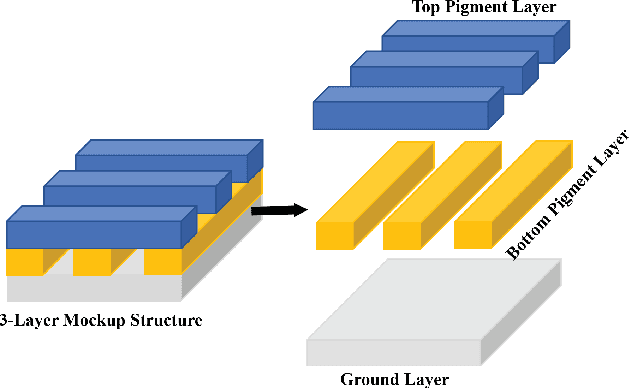
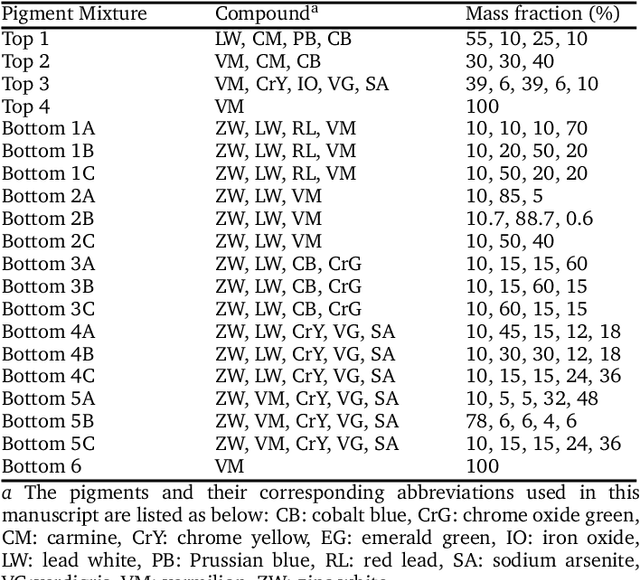
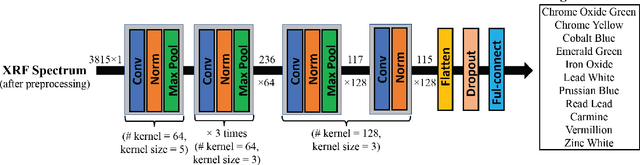
X-ray fluorescence spectroscopy (XRF) plays an important role for elemental analysis in a wide range of scientific fields, especially in cultural heritage. XRF imaging, which uses a raster scan to acquire spectra across artworks, provides the opportunity for spatial analysis of pigment distributions based on their elemental composition. However, conventional XRF-based pigment identification relies on time-consuming elemental mapping by expert interpretations of measured spectra. To reduce the reliance on manual work, recent studies have applied machine learning techniques to cluster similar XRF spectra in data analysis and to identify the most likely pigments. Nevertheless, it is still challenging for automatic pigment identification strategies to directly tackle the complex structure of real paintings, e.g. pigment mixtures and layered pigments. In addition, pixel-wise pigment identification based on XRF imaging remains an obstacle due to the high noise level compared with averaged spectra. Therefore, we developed a deep-learning-based end-to-end pigment identification framework to fully automate the pigment identification process. In particular, it offers high sensitivity to the underlying pigments and to the pigments with a low concentration, therefore enabling satisfying results in mapping the pigments based on single-pixel XRF spectrum. As case studies, we applied our framework to lab-prepared mock-up paintings and two 19th-century paintings: Paul Gauguin's Po\`emes Barbares (1896) that contains layered pigments with an underlying painting, and Paul Cezanne's The Bathers (1899-1904). The pigment identification results demonstrated that our model achieved comparable results to the analysis by elemental mapping, suggesting the generalizability and stability of our model.
Denoising Fast X-Ray Fluorescence Raster Scans of Paintings
Jun 03, 2022

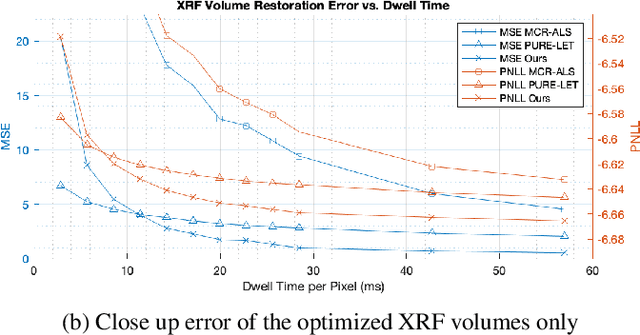
Macro x-ray fluorescence (XRF) imaging of cultural heritage objects, while a popular non-invasive technique for providing elemental distribution maps, is a slow acquisition process in acquiring high signal-to-noise ratio XRF volumes. Typically on the order of tenths of a second per pixel, a raster scanning probe counts the number of photons at different energies emitted by the object under x-ray illumination. In an effort to reduce the scan times without sacrificing elemental map and XRF volume quality, we propose using dictionary learning with a Poisson noise model as well as a color image-based prior to restore noisy, rapidly acquired XRF data.