 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoMotion: Hierarchical Reasoning and Diffusion for Egocentric Vision-Language Motion Generation
Apr 21, 2026Faithfully modeling human behavior in dynamic environments is a foundational challenge for embodied intelligence. While conditional motion synthesis has achieved significant advances, egocentric motion generation remains largely underexplored due to the inherent complexity of first-person perception. In this work, we investigate Egocentric Vision-Language (Ego-VL) motion generation. This task requires synthesizing 3D human motion conditioned jointly on first-person visual observations and natural language instructions. We identify a critical \textit{reasoning-generation entanglement} challenge: the simultaneous optimization of semantic reasoning and kinematic modeling introduces gradient conflicts. These conflicts systematically degrade the fidelity of multimodal grounding and motion quality. To address this challenge, we propose a hierarchical generative framework \textbf{EgoMotion}. Inspired by the biological decoupling of cognitive reasoning and motor control, EgoMotion operates in two stages. In the Cognitive Reasoning stage, A vision-language model (VLM) projects multimodal inputs into a structured space of discrete motion primitives. This forces the VLM to acquire goal-consistent representations, effectively bridging the semantic gap between high-level perceptual understanding and low-level action execution. In the Motion Generation stage, these learned representations serve as expressive conditioning signals for a diffusion-based motion generator. By performing iterative denoising within a continuous latent space, the generator synthesizes physically plausible and temporally coherent trajectories. Extensive evaluations demonstrate that EgoMotion achieves state-of-the-art performance, and produces motion sequences that are both semantically grounded and kinematically superior to existing approaches.
Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation
May 31, 2024
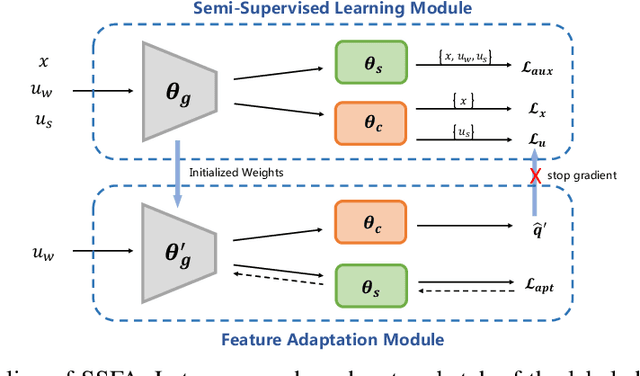


Traditional semi-supervised learning (SSL) assumes that the feature distributions of labeled and unlabeled data are consistent which rarely holds in realistic scenarios. In this paper, we propose a novel SSL setting, where unlabeled samples are drawn from a mixed distribution that deviates from the feature distribution of labeled samples. Under this setting, previous SSL methods tend to predict wrong pseudo-labels with the model fitted on labeled data, resulting in noise accumulation. To tackle this issue, we propose Self-Supervised Feature Adaptation (SSFA), a generic framework for improving SSL performance when labeled and unlabeled data come from different distributions. SSFA decouples the prediction of pseudo-labels from the current model to improve the quality of pseudo-labels. Particularly, SSFA incorporates a self-supervised task into the SSL framework and uses it to adapt the feature extractor of the model to the unlabeled data. In this way, the extracted features better fit the distribution of unlabeled data, thereby generating high-quality pseudo-labels. Extensive experiments show that our proposed SSFA is applicable to various pseudo-label-based SSL learners and significantly improves performance in labeled, unlabeled, and even unseen distributions.
Task Attribute Distance for Few-Shot Learning: Theoretical Analysis and Applications
Mar 06, 2024Few-shot learning (FSL) aims to learn novel tasks with very few labeled samples by leveraging experience from \emph{related} training tasks. In this paper, we try to understand FSL by delving into two key questions: (1) How to quantify the relationship between \emph{training} and \emph{novel} tasks? (2) How does the relationship affect the \emph{adaptation difficulty} on novel tasks for different models? To answer the two questions, we introduce Task Attribute Distance (TAD) built upon attributes as a metric to quantify the task relatedness. Unlike many existing metrics, TAD is model-agnostic, making it applicable to different FSL models. Then, we utilize TAD metric to establish a theoretical connection between task relatedness and task adaptation difficulty. By deriving the generalization error bound on a novel task, we discover how TAD measures the adaptation difficulty on novel tasks for FSL models. To validate our TAD metric and theoretical findings, we conduct experiments on three benchmarks. Our experimental results confirm that TAD metric effectively quantifies the task relatedness and reflects the adaptation difficulty on novel tasks for various FSL methods, even if some of them do not learn attributes explicitly or human-annotated attributes are not available. Finally, we present two applications of the proposed TAD metric: data augmentation and test-time intervention, which further verify its effectiveness and general applicability. The source code is available at https://github.com/hu-my/TaskAttributeDistance.
Prototype-Guided Text-based Person Search based on Rich Chinese Descriptions
Dec 22, 2023Text-based person search aims to simultaneously localize and identify the target person based on query text from uncropped scene images, which can be regarded as the unified task of person detection and text-based person retrieval task. In this work, we propose a large-scale benchmark dataset named PRW-TPS-CN based on the widely used person search dataset PRW. Our dataset contains 47,102 sentences, which means there is quite more information than existing dataset. These texts precisely describe the person images from top to bottom, which in line with the natural description order. We also provide both Chinese and English descriptions in our dataset for more comprehensive evaluation. These characteristics make our dataset more applicable. To alleviate the inconsistency between person detection and text-based person retrieval, we take advantage of the rich texts in PRW-TPS-CN dataset. We propose to aggregate multiple texts as text prototypes to maintain the prominent text features of a person, which can better reflect the whole character of a person. The overall prototypes lead to generating the image attention map to eliminate the detection misalignment causing the decrease of text-based person retrieval. Thus, the inconsistency between person detection and text-based person retrieval is largely alleviated. We conduct extensive experiments on the PRW-TPS-CN dataset. The experimental results show the PRW-TPS-CN dataset's effectiveness and the state-of-the-art performance of our approach.
Dual Compensation Residual Networks for Class Imbalanced Learning
Aug 25, 2023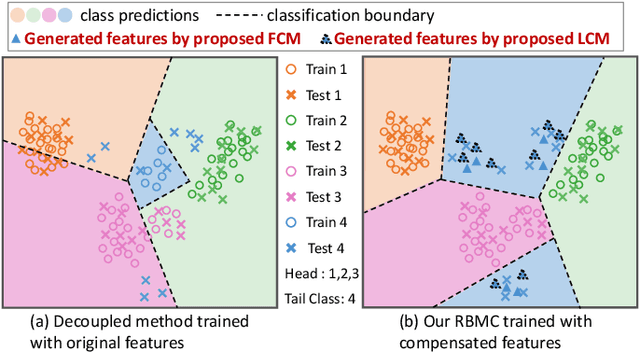
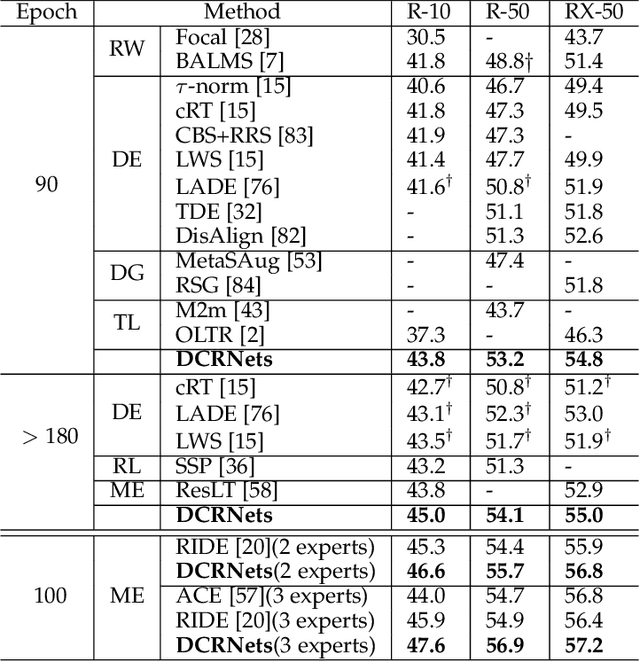
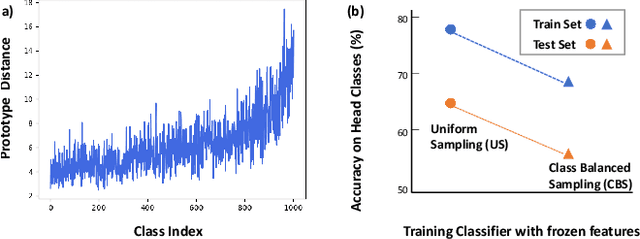
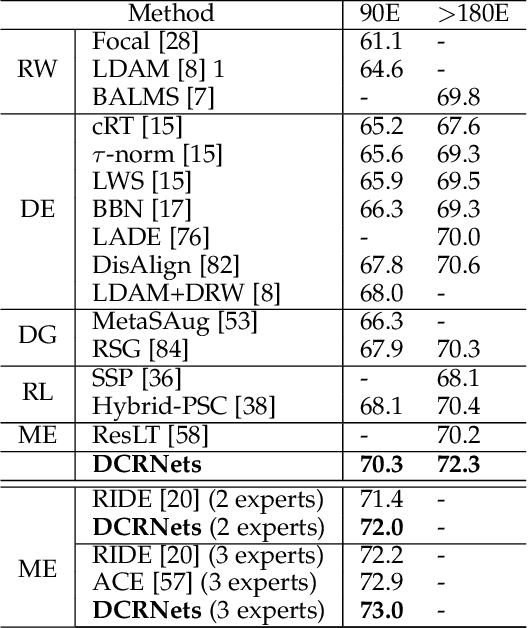
Learning generalizable representation and classifier for class-imbalanced data is challenging for data-driven deep models. Most studies attempt to re-balance the data distribution, which is prone to overfitting on tail classes and underfitting on head classes. In this work, we propose Dual Compensation Residual Networks to better fit both tail and head classes. Firstly, we propose dual Feature Compensation Module (FCM) and Logit Compensation Module (LCM) to alleviate the overfitting issue. The design of these two modules is based on the observation: an important factor causing overfitting is that there is severe feature drift between training and test data on tail classes. In details, the test features of a tail category tend to drift towards feature cloud of multiple similar head categories. So FCM estimates a multi-mode feature drift direction for each tail category and compensate for it. Furthermore, LCM translates the deterministic feature drift vector estimated by FCM along intra-class variations, so as to cover a larger effective compensation space, thereby better fitting the test features. Secondly, we propose a Residual Balanced Multi-Proxies Classifier (RBMC) to alleviate the under-fitting issue. Motivated by the observation that re-balancing strategy hinders the classifier from learning sufficient head knowledge and eventually causes underfitting, RBMC utilizes uniform learning with a residual path to facilitate classifier learning. Comprehensive experiments on Long-tailed and Class-Incremental benchmarks validate the efficacy of our method.
* 20 pages
Diversity-Measurable Anomaly Detection
Mar 09, 2023



Reconstruction-based anomaly detection models achieve their purpose by suppressing the generalization ability for anomaly. However, diverse normal patterns are consequently not well reconstructed as well. Although some efforts have been made to alleviate this problem by modeling sample diversity, they suffer from shortcut learning due to undesired transmission of abnormal information. In this paper, to better handle the tradeoff problem, we propose Diversity-Measurable Anomaly Detection (DMAD) framework to enhance reconstruction diversity while avoid the undesired generalization on anomalies. To this end, we design Pyramid Deformation Module (PDM), which models diverse normals and measures the severity of anomaly by estimating multi-scale deformation fields from reconstructed reference to original input. Integrated with an information compression module, PDM essentially decouples deformation from prototypical embedding and makes the final anomaly score more reliable. Experimental results on both surveillance videos and industrial images demonstrate the effectiveness of our method. In addition, DMAD works equally well in front of contaminated data and anomaly-like normal samples.
Clothes-Changing Person Re-identification with RGB Modality Only
Apr 14, 2022
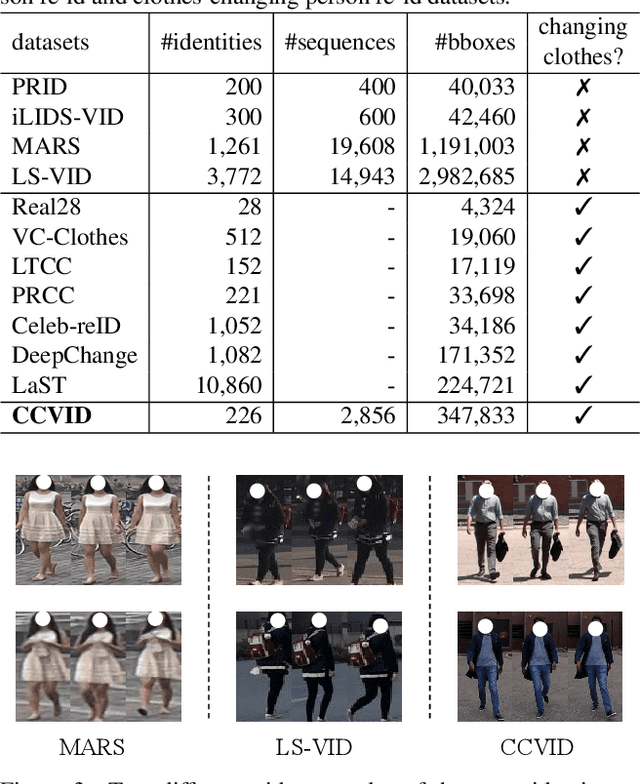
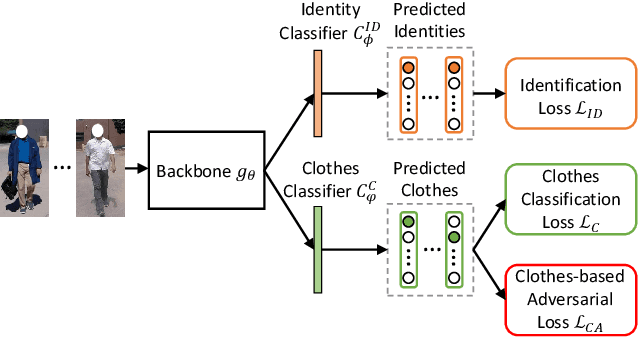
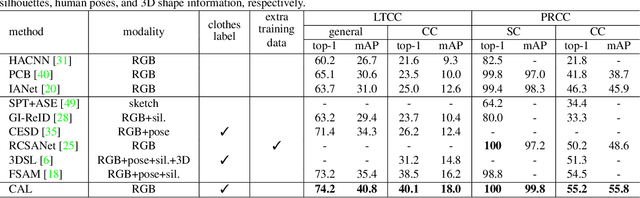
The key to address clothes-changing person re-identification (re-id) is to extract clothes-irrelevant features, e.g., face, hairstyle, body shape, and gait. Most current works mainly focus on modeling body shape from multi-modality information (e.g., silhouettes and sketches), but do not make full use of the clothes-irrelevant information in the original RGB images. In this paper, we propose a Clothes-based Adversarial Loss (CAL) to mine clothes-irrelevant features from the original RGB images by penalizing the predictive power of re-id model w.r.t. clothes. Extensive experiments demonstrate that using RGB images only, CAL outperforms all state-of-the-art methods on widely-used clothes-changing person re-id benchmarks. Besides, compared with images, videos contain richer appearance and additional temporal information, which can be used to model proper spatiotemporal patterns to assist clothes-changing re-id. Since there is no publicly available clothes-changing video re-id dataset, we contribute a new dataset named CCVID and show that there exists much room for improvement in modeling spatiotemporal information. The code and new dataset are available at: https://github.com/guxinqian/Simple-CCReID.
Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework
Mar 24, 2022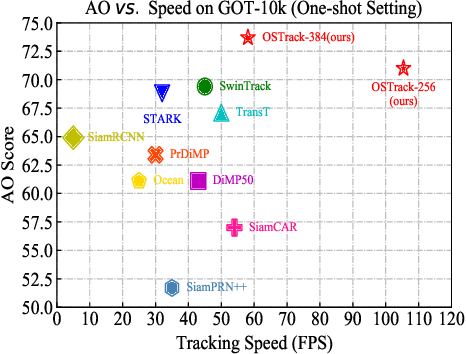
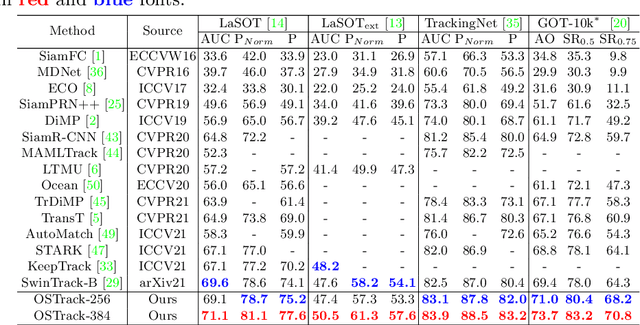
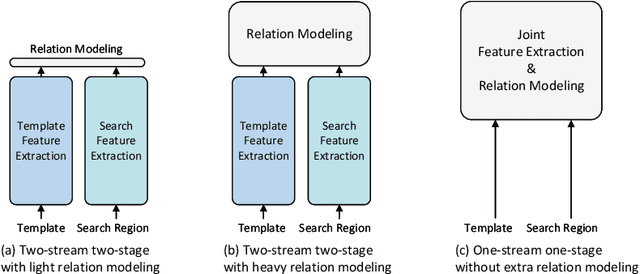

The current popular two-stream, two-stage tracking framework extracts the template and the search region features separately and then performs relation modeling, thus the extracted features lack the awareness of the target and have limited target-background discriminability. To tackle the above issue, we propose a novel one-stream tracking (OSTrack) framework that unifies feature learning and relation modeling by bridging the template-search image pairs with bidirectional information flows. In this way, discriminative target-oriented features can be dynamically extracted by mutual guidance. Since no extra heavy relation modeling module is needed and the implementation is highly parallelized, the proposed tracker runs at a fast speed. To further improve the inference efficiency, an in-network candidate early elimination module is proposed based on the strong similarity prior calculated in the one-stream framework. As a unified framework, OSTrack achieves state-of-the-art performance on multiple benchmarks, in particular, it shows impressive results on the one-shot tracking benchmark GOT-10k, i.e., achieving 73.7% AO, improving the existing best result (SwinTrack) by 4.3%. Besides, our method maintains a good performance-speed trade-off and shows faster convergence. The code and models will be available at https://github.com/botaoye/OSTrack.
Feature Completion for Occluded Person Re-Identification
Jun 24, 2021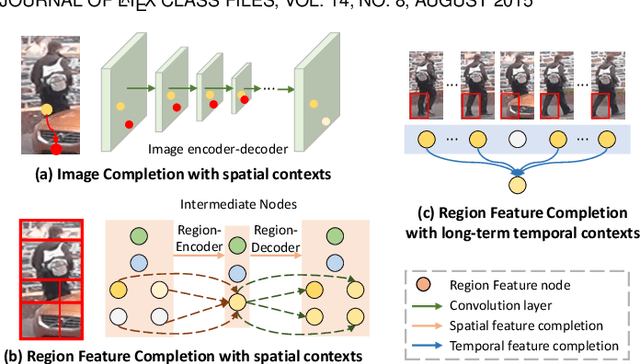
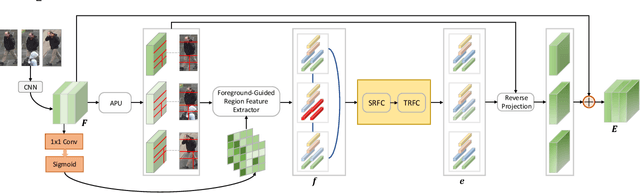
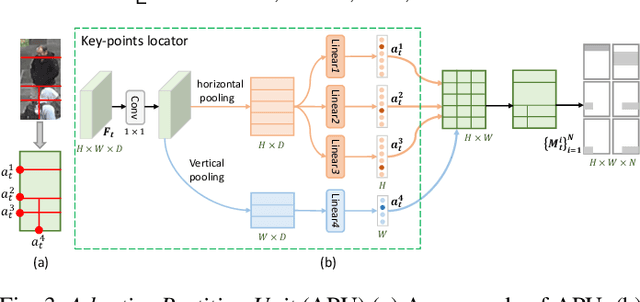

Person re-identification (reID) plays an important role in computer vision. However, existing methods suffer from performance degradation in occluded scenes. In this work, we propose an occlusion-robust block, Region Feature Completion (RFC), for occluded reID. Different from most previous works that discard the occluded regions, RFC block can recover the semantics of occluded regions in feature space. Firstly, a Spatial RFC (SRFC) module is developed. SRFC exploits the long-range spatial contexts from non-occluded regions to predict the features of occluded regions. The unit-wise prediction task leads to an encoder/decoder architecture, where the region-encoder models the correlation between non-occluded and occluded region, and the region-decoder utilizes the spatial correlation to recover occluded region features. Secondly, we introduce Temporal RFC (TRFC) module which captures the long-term temporal contexts to refine the prediction of SRFC. RFC block is lightweight, end-to-end trainable and can be easily plugged into existing CNNs to form RFCnet. Extensive experiments are conducted on occluded and commonly holistic reID benchmarks. Our method significantly outperforms existing methods on the occlusion datasets, while remains top even superior performance on holistic datasets. The source code is available at https://github.com/blue-blue272/OccludedReID-RFCnet.
* 18 pages, 17 figures. The paper is accepted by TPAMI, and the code is available at https://github.com/blue-blue272/OccludedReID-RFCnet
BiCnet-TKS: Learning Efficient Spatial-Temporal Representation for Video Person Re-Identification
Apr 30, 2021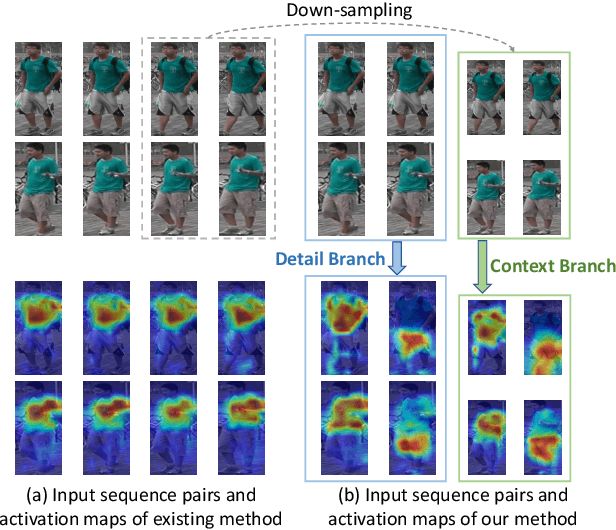
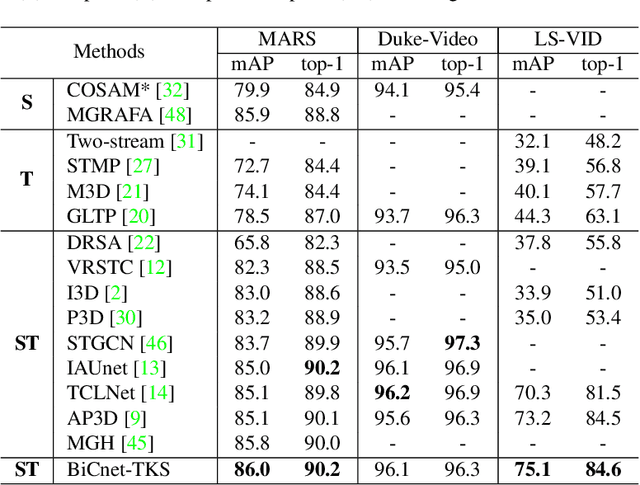

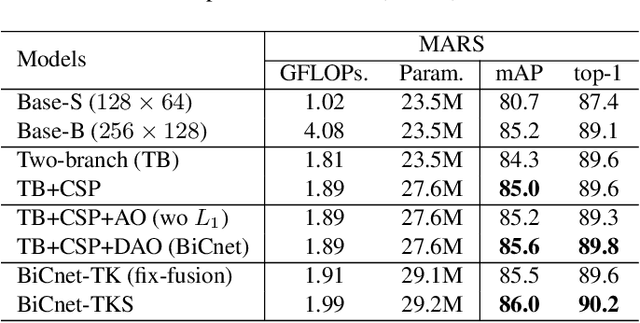
In this paper, we present an efficient spatial-temporal representation for video person re-identification (reID). Firstly, we propose a Bilateral Complementary Network (BiCnet) for spatial complementarity modeling. Specifically, BiCnet contains two branches. Detail Branch processes frames at original resolution to preserve the detailed visual clues, and Context Branch with a down-sampling strategy is employed to capture long-range contexts. On each branch, BiCnet appends multiple parallel and diverse attention modules to discover divergent body parts for consecutive frames, so as to obtain an integral characteristic of target identity. Furthermore, a Temporal Kernel Selection (TKS) block is designed to capture short-term as well as long-term temporal relations by an adaptive mode. TKS can be inserted into BiCnet at any depth to construct BiCnetTKS for spatial-temporal modeling. Experimental results on multiple benchmarks show that BiCnet-TKS outperforms state-of-the-arts with about 50% less computations. The source code is available at https://github.com/ blue-blue272/BiCnet-TKS.