 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMo: Scaling Any-Modality Conditional Motion Generation with Masked Modeling
May 28, 2026Conditional human motion generation remains a fundamental challenge in computer vision and robotics. Despite significant progress, current methods are often constrained by fixed modality configurations and task-specific architectures, leaving cross-modal interactions and the scaling laws of multimodal-conditioned synthesis largely underexplored. A key bottleneck is the scarcity of large-scale modality-aligned motion data, limiting generalization across diverse control signals. In this work, we introduce OmniHuMo, a large-scale, high-quality dataset comprising over 5,000 hours of motion and 3.2 million sequences with precisely aligned multimodal annotations (e.g., text, speech, music, and trajectory). Leveraging OmniHuMo, we propose AnyMo, a unified multimodal framework combining a Residual FSQ-based motion tokenizer with a scalable masked modeling transformer, enabling high-quality motion synthesis under arbitrary modality combinations. Extensive experiments show that AnyMo achieves high-fidelity synthesis while offering flexible control over both spatial and stylistic attributes.
Component-Based Out-of-Distribution Detection
Apr 23, 2026Out-of-Distribution (OOD) detection requires sensitivity to subtle shifts without overreacting to natural In-Distribution (ID) diversity. However, from the viewpoint of detection granularity, global representation inevitably suppress local OOD cues, while patch-based methods are unstable due to entangled spurious-correlation and noise. And neither them is effective in detecting compositional OODs composed of valid ID components. Inspired by recognition-by-components theory, we present a training-free Component-Based OOD Detection (CoOD) framework that addresses the existing limitations by decomposing inputs into functional components. To instantiate CoOD, we derive Component Shift Score (CSS) to detect local appearance shifts, and Compositional Consistency Score (CCS) to identify cross-component compositional inconsistencies. Empirically, CoOD achieves consistent improvements on both coarse- and fine-grained OOD detection.
EgoMotion: Hierarchical Reasoning and Diffusion for Egocentric Vision-Language Motion Generation
Apr 21, 2026Faithfully modeling human behavior in dynamic environments is a foundational challenge for embodied intelligence. While conditional motion synthesis has achieved significant advances, egocentric motion generation remains largely underexplored due to the inherent complexity of first-person perception. In this work, we investigate Egocentric Vision-Language (Ego-VL) motion generation. This task requires synthesizing 3D human motion conditioned jointly on first-person visual observations and natural language instructions. We identify a critical \textit{reasoning-generation entanglement} challenge: the simultaneous optimization of semantic reasoning and kinematic modeling introduces gradient conflicts. These conflicts systematically degrade the fidelity of multimodal grounding and motion quality. To address this challenge, we propose a hierarchical generative framework \textbf{EgoMotion}. Inspired by the biological decoupling of cognitive reasoning and motor control, EgoMotion operates in two stages. In the Cognitive Reasoning stage, A vision-language model (VLM) projects multimodal inputs into a structured space of discrete motion primitives. This forces the VLM to acquire goal-consistent representations, effectively bridging the semantic gap between high-level perceptual understanding and low-level action execution. In the Motion Generation stage, these learned representations serve as expressive conditioning signals for a diffusion-based motion generator. By performing iterative denoising within a continuous latent space, the generator synthesizes physically plausible and temporally coherent trajectories. Extensive evaluations demonstrate that EgoMotion achieves state-of-the-art performance, and produces motion sequences that are both semantically grounded and kinematically superior to existing approaches.
DreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning
Jan 29, 2026Character image animation aims to synthesize high-fidelity videos by transferring motion from a driving sequence to a static reference image. Despite recent advancements, existing methods suffer from two fundamental challenges: (1) suboptimal motion injection strategies that lead to a trade-off between identity preservation and motion consistency, manifesting as a "see-saw", and (2) an over-reliance on explicit pose priors (e.g., skeletons), which inadequately capture intricate dynamics and hinder generalization to arbitrary, non-humanoid characters. To address these challenges, we present DreamActor-M2, a universal animation framework that reimagines motion conditioning as an in-context learning problem. Our approach follows a two-stage paradigm. First, we bridge the input modality gap by fusing reference appearance and motion cues into a unified latent space, enabling the model to jointly reason about spatial identity and temporal dynamics by leveraging the generative prior of foundational models. Second, we introduce a self-bootstrapped data synthesis pipeline that curates pseudo cross-identity training pairs, facilitating a seamless transition from pose-dependent control to direct, end-to-end RGB-driven animation. This strategy significantly enhances generalization across diverse characters and motion scenarios. To facilitate comprehensive evaluation, we further introduce AW Bench, a versatile benchmark encompassing a wide spectrum of characters types and motion scenarios. Extensive experiments demonstrate that DreamActor-M2 achieves state-of-the-art performance, delivering superior visual fidelity and robust cross-domain generalization. Project Page: https://grisoon.github.io/DreamActor-M2/
CLIP-Guided Adaptable Self-Supervised Learning for Human-Centric Visual Tasks
Jan 19, 2026Human-centric visual analysis plays a pivotal role in diverse applications, including surveillance, healthcare, and human-computer interaction. With the emergence of large-scale unlabeled human image datasets, there is an increasing need for a general unsupervised pre-training model capable of supporting diverse human-centric downstream tasks. To achieve this goal, we propose CLASP (CLIP-guided Adaptable Self-suPervised learning), a novel framework designed for unsupervised pre-training in human-centric visual tasks. CLASP leverages the powerful vision-language model CLIP to generate both low-level (e.g., body parts) and high-level (e.g., attributes) semantic pseudo-labels. These multi-level semantic cues are then integrated into the learned visual representations, enriching their expressiveness and generalizability. Recognizing that different downstream tasks demand varying levels of semantic granularity, CLASP incorporates a Prompt-Controlled Mixture-of-Experts (MoE) module. MoE dynamically adapts feature extraction based on task-specific prompts, mitigating potential feature conflicts and enhancing transferability. Furthermore, CLASP employs a multi-task pre-training strategy, where part- and attribute-level pseudo-labels derived from CLIP guide the representation learning process. Extensive experiments across multiple benchmarks demonstrate that CLASP consistently outperforms existing unsupervised pre-training methods, advancing the field of human-centric visual analysis.
Revisiting Multimodal Positional Encoding in Vision-Language Models
Oct 27, 2025Multimodal position encoding is essential for vision-language models, yet there has been little systematic investigation into multimodal position encoding. We conduct a comprehensive analysis of multimodal Rotary Positional Embedding (RoPE) by examining its two core components: position design and frequency allocation. Through extensive experiments, we identify three key guidelines: positional coherence, full frequency utilization, and preservation of textual priors-ensuring unambiguous layout, rich representation, and faithful transfer from the pre-trained LLM. Based on these insights, we propose Multi-Head RoPE (MHRoPE) and MRoPE-Interleave (MRoPE-I), two simple and plug-and-play variants that require no architectural changes. Our methods consistently outperform existing approaches across diverse benchmarks, with significant improvements in both general and fine-grained multimodal understanding. Code will be avaliable at https://github.com/JJJYmmm/Multimodal-RoPEs.
un$^2$CLIP: Improving CLIP's Visual Detail Capturing Ability via Inverting unCLIP
May 30, 2025Contrastive Language-Image Pre-training (CLIP) has become a foundation model and has been applied to various vision and multimodal tasks. However, recent works indicate that CLIP falls short in distinguishing detailed differences in images and shows suboptimal performance on dense-prediction and vision-centric multimodal tasks. Therefore, this work focuses on improving existing CLIP models, aiming to capture as many visual details in images as possible. We find that a specific type of generative models, unCLIP, provides a suitable framework for achieving our goal. Specifically, unCLIP trains an image generator conditioned on the CLIP image embedding. In other words, it inverts the CLIP image encoder. Compared to discriminative models like CLIP, generative models are better at capturing image details because they are trained to learn the data distribution of images. Additionally, the conditional input space of unCLIP aligns with CLIP's original image-text embedding space. Therefore, we propose to invert unCLIP (dubbed un$^2$CLIP) to improve the CLIP model. In this way, the improved image encoder can gain unCLIP's visual detail capturing ability while preserving its alignment with the original text encoder simultaneously. We evaluate our improved CLIP across various tasks to which CLIP has been applied, including the challenging MMVP-VLM benchmark, the dense-prediction open-vocabulary segmentation task, and multimodal large language model tasks. Experiments show that un$^2$CLIP significantly improves the original CLIP and previous CLIP improvement methods. Code and models will be available at https://github.com/LiYinqi/un2CLIP.
DIVE: Inverting Conditional Diffusion Models for Discriminative Tasks
Apr 24, 2025Diffusion models have shown remarkable progress in various generative tasks such as image and video generation. This paper studies the problem of leveraging pretrained diffusion models for performing discriminative tasks. Specifically, we extend the discriminative capability of pretrained frozen generative diffusion models from the classification task to the more complex object detection task, by "inverting" a pretrained layout-to-image diffusion model. To this end, a gradient-based discrete optimization approach for replacing the heavy prediction enumeration process, and a prior distribution model for making more accurate use of the Bayes' rule, are proposed respectively. Empirical results show that this method is on par with basic discriminative object detection baselines on COCO dataset. In addition, our method can greatly speed up the previous diffusion-based method for classification without sacrificing accuracy. Code and models are available at https://github.com/LiYinqi/DIVE .
HIS-GPT: Towards 3D Human-In-Scene Multimodal Understanding
Mar 17, 2025We propose a new task to benchmark human-in-scene understanding for embodied agents: Human-In-Scene Question Answering (HIS-QA). Given a human motion within a 3D scene, HIS-QA requires the agent to comprehend human states and behaviors, reason about its surrounding environment, and answer human-related questions within the scene. To support this new task, we present HIS-Bench, a multimodal benchmark that systematically evaluates HIS understanding across a broad spectrum, from basic perception to commonsense reasoning and planning. Our evaluation of various vision-language models on HIS-Bench reveals significant limitations in their ability to handle HIS-QA tasks. To this end, we propose HIS-GPT, the first foundation model for HIS understanding. HIS-GPT integrates 3D scene context and human motion dynamics into large language models while incorporating specialized mechanisms to capture human-scene interactions. Extensive experiments demonstrate that HIS-GPT sets a new state-of-the-art on HIS-QA tasks. We hope this work inspires future research on human behavior analysis in 3D scenes, advancing embodied AI and world models.
MATS: An Audio Language Model under Text-only Supervision
Feb 20, 2025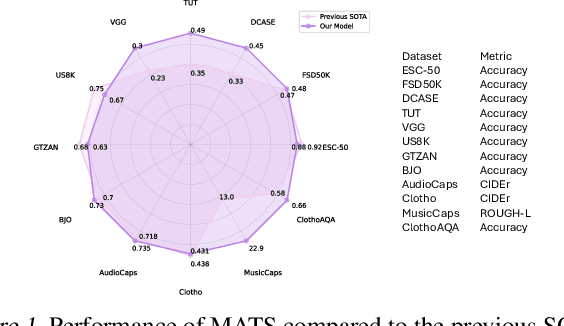
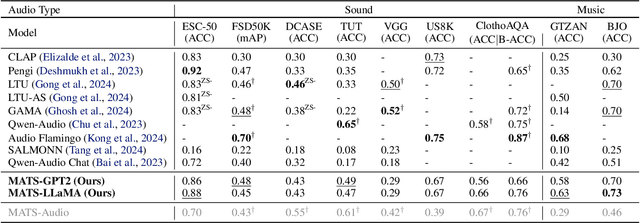
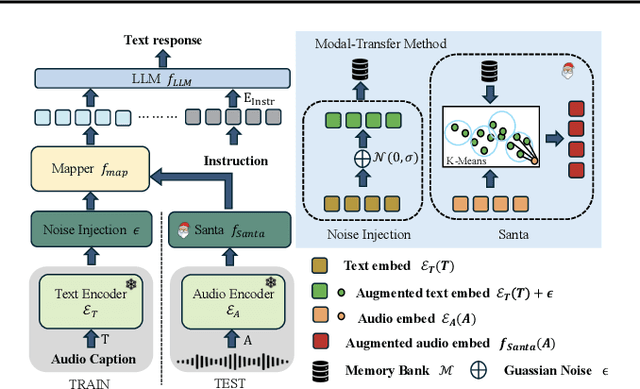
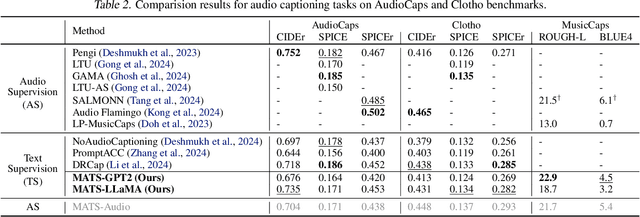
Large audio-language models (LALMs), built upon powerful Large Language Models (LLMs), have exhibited remarkable audio comprehension and reasoning capabilities. However, the training of LALMs demands a large corpus of audio-language pairs, which requires substantial costs in both data collection and training resources. In this paper, we propose MATS, an audio-language multimodal LLM designed to handle Multiple Audio task using solely Text-only Supervision. By leveraging pre-trained audio-language alignment models such as CLAP, we develop a text-only training strategy that projects the shared audio-language latent space into LLM latent space, endowing the LLM with audio comprehension capabilities without relying on audio data during training. To further bridge the modality gap between audio and language embeddings within CLAP, we propose the Strongly-related noisy text with audio (Santa) mechanism. Santa maps audio embeddings into CLAP language embedding space while preserving essential information from the audio input. Extensive experiments demonstrate that MATS, despite being trained exclusively on text data, achieves competitive performance compared to recent LALMs trained on large-scale audio-language pairs.