 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATS: An Audio Language Model under Text-only Supervision
Paper and Code
Feb 20, 2025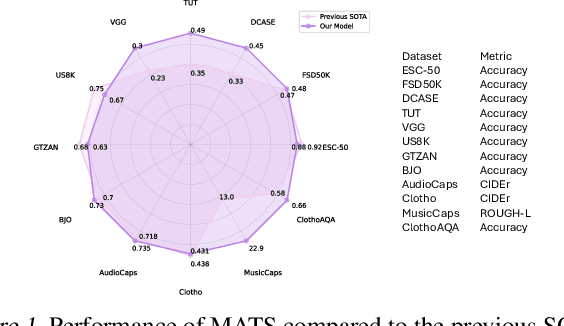
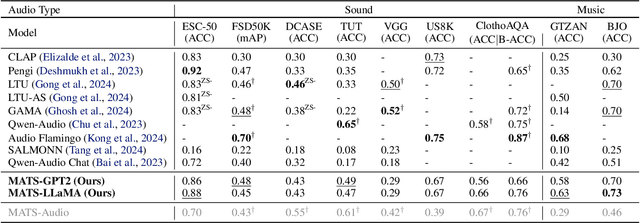
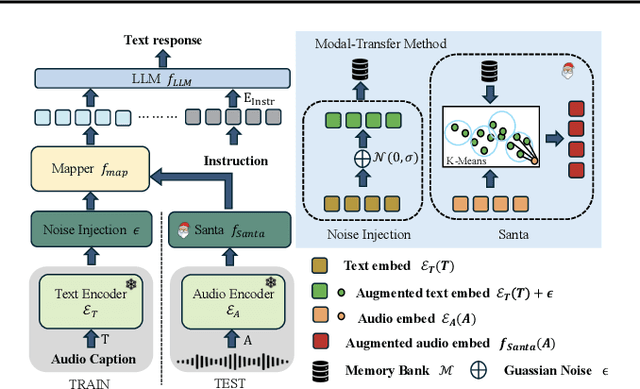
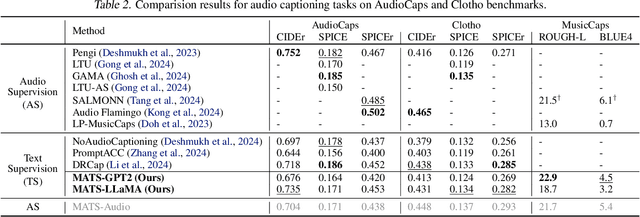
Large audio-language models (LALMs), built upon powerful Large Language Models (LLMs), have exhibited remarkable audio comprehension and reasoning capabilities. However, the training of LALMs demands a large corpus of audio-language pairs, which requires substantial costs in both data collection and training resources. In this paper, we propose MATS, an audio-language multimodal LLM designed to handle Multiple Audio task using solely Text-only Supervision. By leveraging pre-trained audio-language alignment models such as CLAP, we develop a text-only training strategy that projects the shared audio-language latent space into LLM latent space, endowing the LLM with audio comprehension capabilities without relying on audio data during training. To further bridge the modality gap between audio and language embeddings within CLAP, we propose the Strongly-related noisy text with audio (Santa) mechanism. Santa maps audio embeddings into CLAP language embedding space while preserving essential information from the audio input. Extensive experiments demonstrate that MATS, despite being trained exclusively on text data, achieves competitive performance compared to recent LALMs trained on large-scale audio-language pairs.