 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLensWalk: Agentic Video Understanding by Planning How You See in Videos
Mar 25, 2026The dense, temporal nature of video presents a profound challenge for automated analysis. Despite the use of powerful Vision-Language Models, prevailing methods for video understanding are limited by the inherent disconnect between reasoning and perception: they rely on static, pre-processed information and cannot actively seek raw evidence from video as their understanding evolves. To address this, we introduce LensWalk, a flexible agentic framework that empowers a Large Language Model reasoner to control its own visual observation actively. LensWalk establishes a tight reason-plan-observe loop where the agent dynamically specifies, at each step, the temporal scope and sampling density of the video it observes. Using a suite of versatile, Vision-Language Model based tools parameterized by these specifications, the agent can perform broad scans for cues, focus on specific segments for fact extraction, and stitch evidence from multiple moments for holistic verification. This design allows for progressive, on-demand evidence gathering that directly serves the agent's evolving chain of thought. Without requiring any model fine-tuning, LensWalk delivers substantial, plug-and-play performance gains on multiple model recipes, boosting their accuracy by over 5\% on challenging long-video benchmarks like LVBench and Video-MME. Our analysis reveals that enabling an agent to control how it sees is key to unlocking more accurate, robust, and interpretable video reasoning.
DenseMLLM: Standard Multimodal LLMs are Intrinsic Dense Predictors
Feb 15, 2026Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in high-level visual understanding. However, extending these models to fine-grained dense prediction tasks, such as semantic segmentation and depth estimation, typically necessitates the incorporation of complex, task-specific decoders and other customizations. This architectural fragmentation increases model complexity and deviates from the generalist design of MLLMs, ultimately limiting their practicality. In this work, we challenge this paradigm by accommodating standard MLLMs to perform dense predictions without requiring additional task-specific decoders. The proposed model is called DenseMLLM, grounded in the standard architecture with a novel vision token supervision strategy for multiple labels and tasks. Despite its minimalist design, our model achieves highly competitive performance across a wide range of dense prediction and vision-language benchmarks, demonstrating that a standard, general-purpose MLLM can effectively support dense perception without architectural specialization.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
HERM: Benchmarking and Enhancing Multimodal LLMs for Human-Centric Understanding
Oct 09, 2024The significant advancements in visual understanding and instruction following from Multimodal Large Language Models (MLLMs) have opened up more possibilities for broader applications in diverse and universal human-centric scenarios. However, existing image-text data may not support the precise modality alignment and integration of multi-grained information, which is crucial for human-centric visual understanding. In this paper, we introduce HERM-Bench, a benchmark for evaluating the human-centric understanding capabilities of MLLMs. Our work reveals the limitations of existing MLLMs in understanding complex human-centric scenarios. To address these challenges, we present HERM-100K, a comprehensive dataset with multi-level human-centric annotations, aimed at enhancing MLLMs' training. Furthermore, we develop HERM-7B, a MLLM that leverages enhanced training data from HERM-100K. Evaluations on HERM-Bench demonstrate that HERM-7B significantly outperforms existing MLLMs across various human-centric dimensions, reflecting the current inadequacy of data annotations used in MLLM training for human-centric visual understanding. This research emphasizes the importance of specialized datasets and benchmarks in advancing the MLLMs' capabilities for human-centric understanding.
How Drones Look: Crowdsourced Knowledge Transfer for Aerial Video Saliency Prediction
Nov 14, 2018
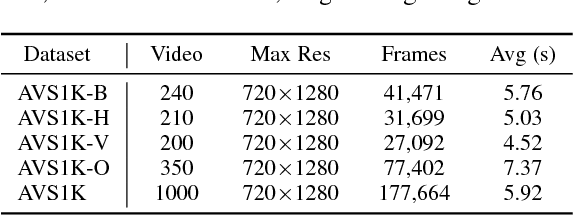


In ground-level platforms, many saliency models have been developed to perceive the visual world as the human does. However, they may not fit a drone that can look from many abnormal viewpoints. To address this problem, this paper proposes a Crowdsourced Multi-path Network (CMNet) that transfer the ground-level knowledge for spatiotemporal saliency prediction in aerial videos. To train CMNet, we first collect and fuse the eye-tracking data of 24 subjects on 1,000 aerial videos to annotate the ground-truth salient regions. Inspired by the crowdsourced annotation in eye-tracking experiments, we design a multi-path architecture for CMNet, in which each path is initialized under the supervision of a classic ground-level saliency model. After that, the most representative paths are selected in a data-driven manner, which are then fused and simultaneously fine-tuned on aerial videos. In this manner, the prior knowledge in various classic ground-level saliency models can be transferred into CMNet so as to improve its capability in processing aerial videos. Finally, the spatial predictions given by CMNet are adaptively refined by incorporating the temporal saliency predictions via a spatiotemporal saliency optimization algorithm. Experimental results show that the proposed approach outperforms ten state-of-the-art models in predicting visual saliency in aerial videos.