 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Drones Look: Crowdsourced Knowledge Transfer for Aerial Video Saliency Prediction
Paper and Code
Nov 14, 2018
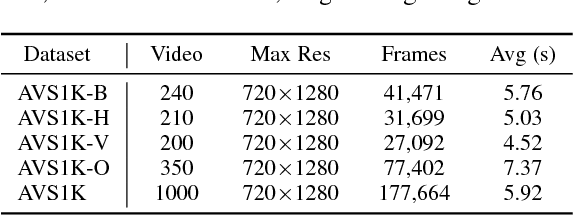


In ground-level platforms, many saliency models have been developed to perceive the visual world as the human does. However, they may not fit a drone that can look from many abnormal viewpoints. To address this problem, this paper proposes a Crowdsourced Multi-path Network (CMNet) that transfer the ground-level knowledge for spatiotemporal saliency prediction in aerial videos. To train CMNet, we first collect and fuse the eye-tracking data of 24 subjects on 1,000 aerial videos to annotate the ground-truth salient regions. Inspired by the crowdsourced annotation in eye-tracking experiments, we design a multi-path architecture for CMNet, in which each path is initialized under the supervision of a classic ground-level saliency model. After that, the most representative paths are selected in a data-driven manner, which are then fused and simultaneously fine-tuned on aerial videos. In this manner, the prior knowledge in various classic ground-level saliency models can be transferred into CMNet so as to improve its capability in processing aerial videos. Finally, the spatial predictions given by CMNet are adaptively refined by incorporating the temporal saliency predictions via a spatiotemporal saliency optimization algorithm. Experimental results show that the proposed approach outperforms ten state-of-the-art models in predicting visual saliency in aerial videos.