 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023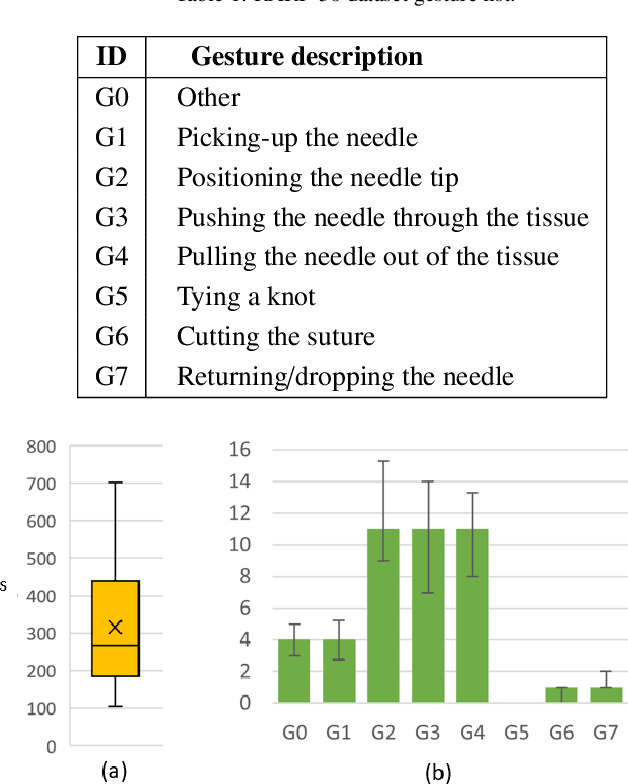
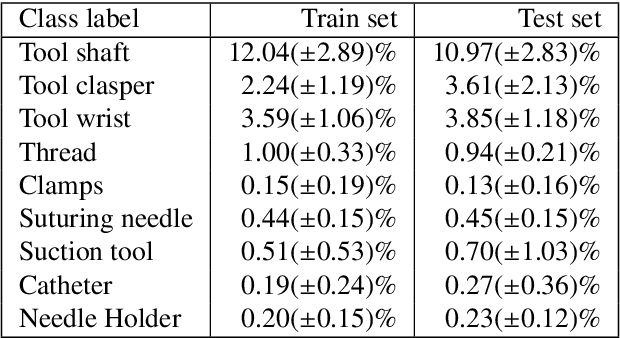
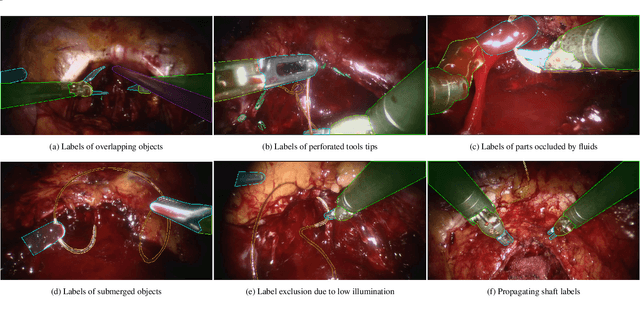
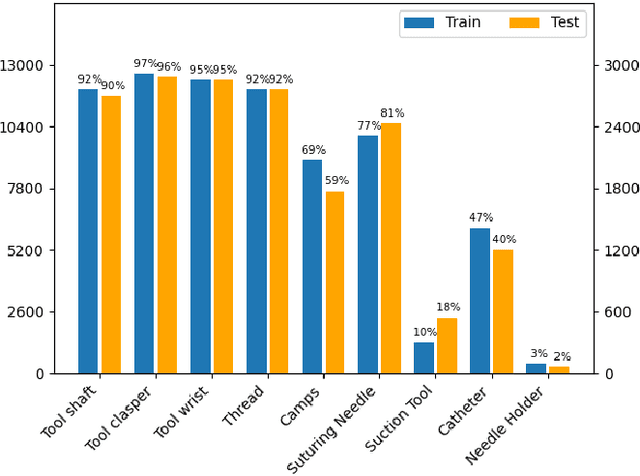
Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
Intrinsic Relationship Reasoning for Small Object Detection
Sep 02, 2020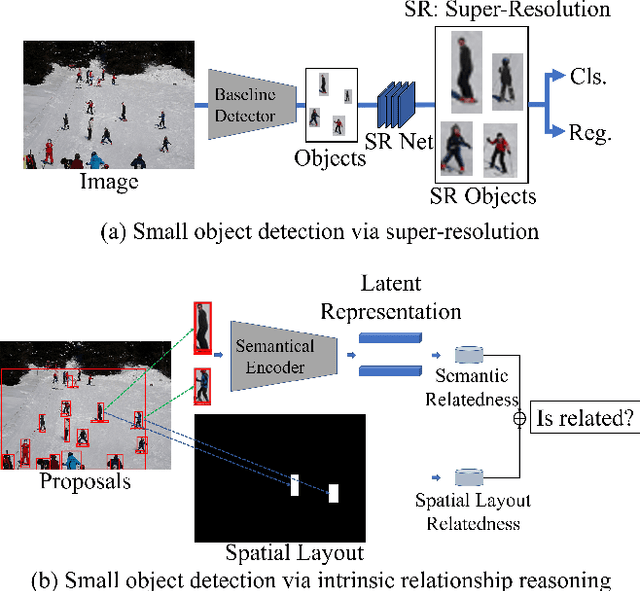
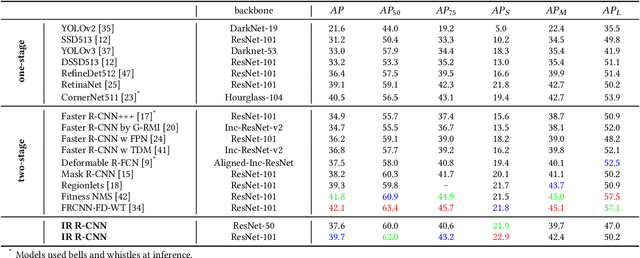
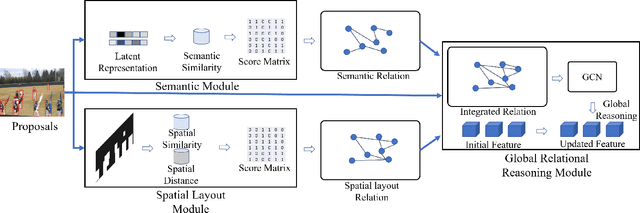
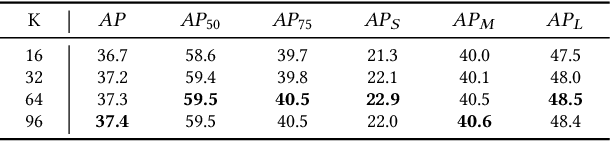
The small objects in images and videos are usually not independent individuals. Instead, they more or less present some semantic and spatial layout relationships with each other. Modeling and inferring such intrinsic relationships can thereby be beneficial for small object detection. In this paper, we propose a novel context reasoning approach for small object detection which models and infers the intrinsic semantic and spatial layout relationships between objects. Specifically, we first construct a semantic module to model the sparse semantic relationships based on the initial regional features, and a spatial layout module to model the sparse spatial layout relationships based on their position and shape information, respectively. Both of them are then fed into a context reasoning module for integrating the contextual information with respect to the objects and their relationships, which is further fused with the original regional visual features for classification and regression. Experimental results reveal that the proposed approach can effectively boost the small object detection performance.
Spatiotemporal Knowledge Distillation for Efficient Estimation of Aerial Video Saliency
Apr 10, 2019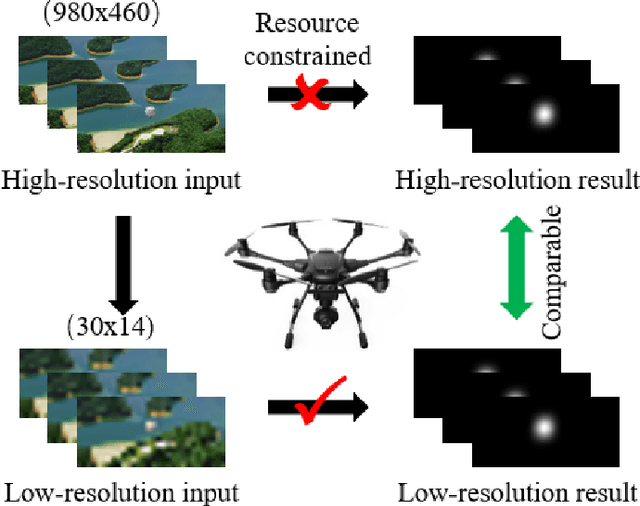
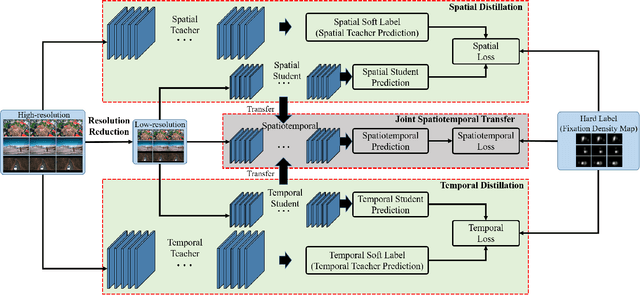
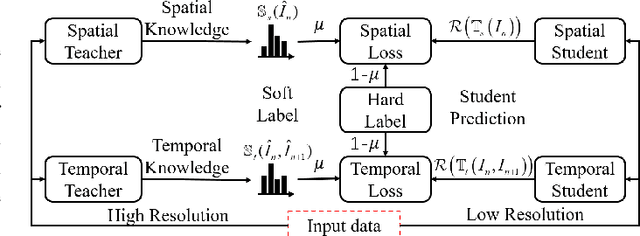
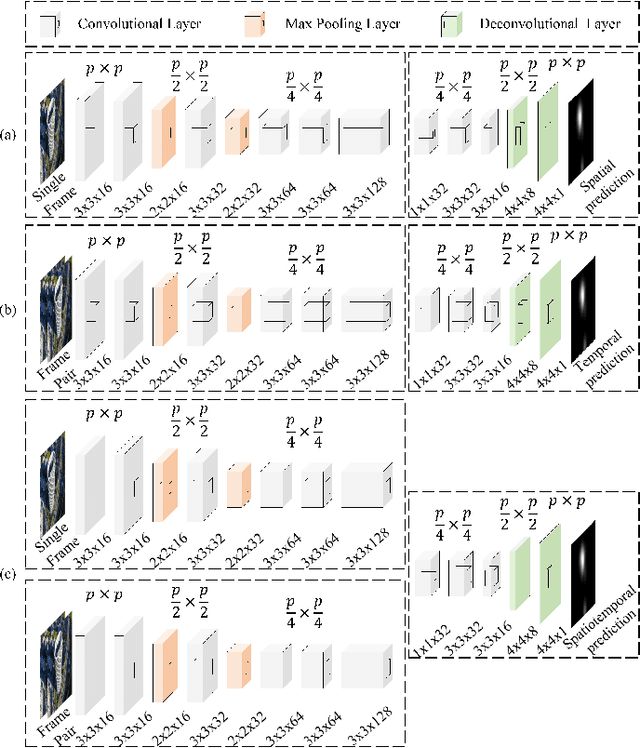
The performance of video saliency estimation techniques has achieved significant advances along with the rapid development of Convolutional Neural Networks (CNNs). However, devices like cameras and drones may have limited computational capability and storage space so that the direct deployment of complex deep saliency models becomes infeasible. To address this problem, this paper proposes a dynamic saliency estimation approach for aerial videos via spatiotemporal knowledge distillation. In this approach, five components are involved, including two teachers, two students and the desired spatiotemporal model. The knowledge of spatial and temporal saliency is first separately transferred from the two complex and redundant teachers to their simple and compact students, and the input scenes are also degraded from high-resolution to low-resolution to remove the probable data redundancy so as to greatly speed up the feature extraction process. After that, the desired spatiotemporal model is further trained by distilling and encoding the spatial and temporal saliency knowledge of two students into a unified network. In this manner, the inter-model redundancy can be further removed for the effective estimation of dynamic saliency on aerial videos. Experimental results show that the proposed approach outperforms ten state-of-the-art models in estimating visual saliency on aerial videos, while its speed reaches up to 28,738 FPS on the GPU platform.
Ultrafast Video Attention Prediction with Coupled Knowledge Distillation
Apr 09, 2019

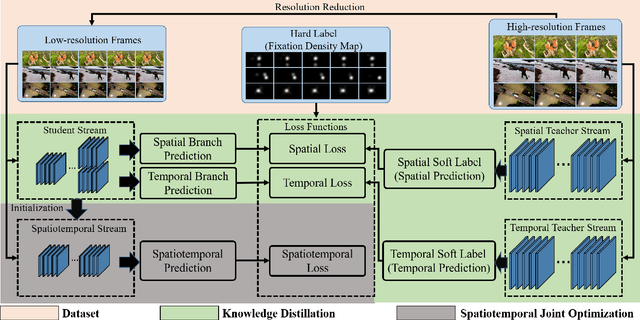
Large convolutional neural network models have recently demonstrated impressive performance on video attention prediction. Conventionally, these models are with intensive computation and large memory. To address these issues, we design an extremely light-weight network with ultrafast speed, named UVA-Net. The network is constructed based on depth-wise convolutions and takes low-resolution images as input. However, this straight-forward acceleration method will decrease performance dramatically. To this end, we propose a coupled knowledge distillation strategy to augment and train the network effectively. With this strategy, the model can further automatically discover and emphasize implicit useful cues contained in the data. Both spatial and temporal knowledge learned by the high-resolution complex teacher networks also can be distilled and transferred into the proposed low-resolution light-weight spatiotemporal network. Experimental results show that the performance of our model is comparable to ten state-of-the-art models in video attention prediction, while it costs only 0.68 MB memory footprint, runs about 10,106 FPS on GPU and 404 FPS on CPU, which is 206 times faster than previous models.
Visual Attention on the Sun: What Do Existing Models Actually Predict?
Nov 25, 2018
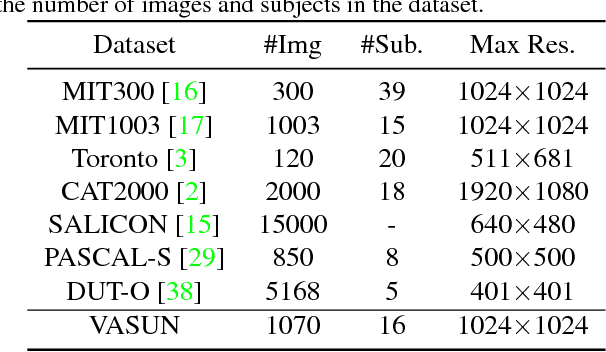
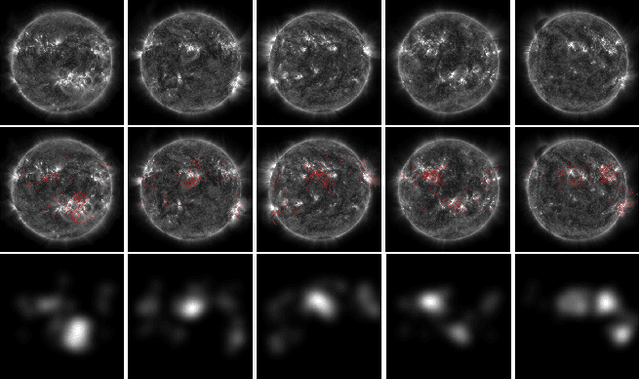
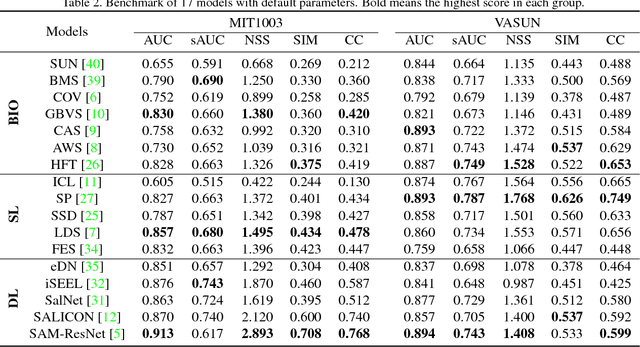
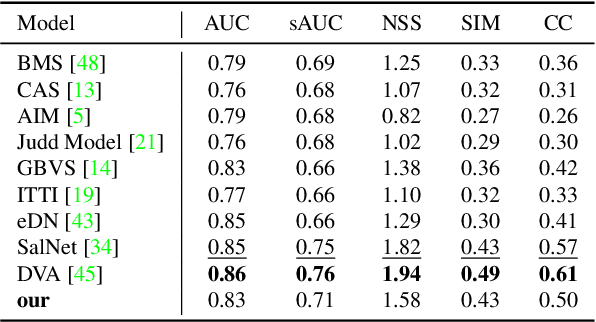
Visual attention prediction is a classic problem that seems to be well addressed in the deep learning era. One compelling concern, however, gradually arise along with the rapidly growing performance scores over existing visual attention datasets: do existing deep models really capture the inherent mechanism of human visual attention? To address this concern, this paper proposes a new dataset, named VASUN, that records the free-viewing human attention on solar images. Different from previous datasets, images in VASUN contain many irregular visual patterns that existing deep models have never seen. By benchmarking existing models on VASUN, we find the performances of many state-of-the-art deep models drop remarkably, while many classic shallow models perform impressively. From these results, we find that the significant performance advance of existing deep attention models may come from their capabilities of memorizing and predicting the occurrence of some specific visual patterns other than learning the inherent mechanism of human visual attention. In addition, we also train several baseline models on VASUN to demonstrate the feasibility and key issues of predicting visual attention on the sun. These baseline models, together with the proposed dataset, can be used to revisit the problem of visual attention prediction from a novel perspective that are complementary to existing ones.
How Drones Look: Crowdsourced Knowledge Transfer for Aerial Video Saliency Prediction
Nov 14, 2018
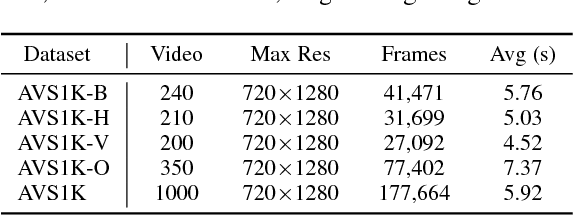


In ground-level platforms, many saliency models have been developed to perceive the visual world as the human does. However, they may not fit a drone that can look from many abnormal viewpoints. To address this problem, this paper proposes a Crowdsourced Multi-path Network (CMNet) that transfer the ground-level knowledge for spatiotemporal saliency prediction in aerial videos. To train CMNet, we first collect and fuse the eye-tracking data of 24 subjects on 1,000 aerial videos to annotate the ground-truth salient regions. Inspired by the crowdsourced annotation in eye-tracking experiments, we design a multi-path architecture for CMNet, in which each path is initialized under the supervision of a classic ground-level saliency model. After that, the most representative paths are selected in a data-driven manner, which are then fused and simultaneously fine-tuned on aerial videos. In this manner, the prior knowledge in various classic ground-level saliency models can be transferred into CMNet so as to improve its capability in processing aerial videos. Finally, the spatial predictions given by CMNet are adaptively refined by incorporating the temporal saliency predictions via a spatiotemporal saliency optimization algorithm. Experimental results show that the proposed approach outperforms ten state-of-the-art models in predicting visual saliency in aerial videos.