 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Knowledge Distillation for Efficient Estimation of Aerial Video Saliency
Paper and Code
Apr 10, 2019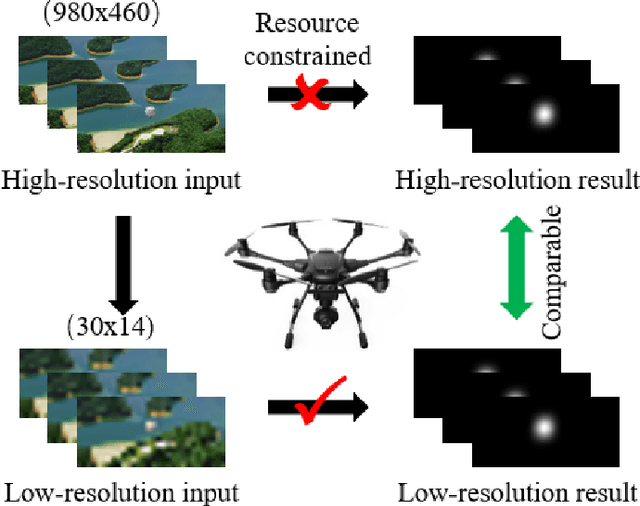
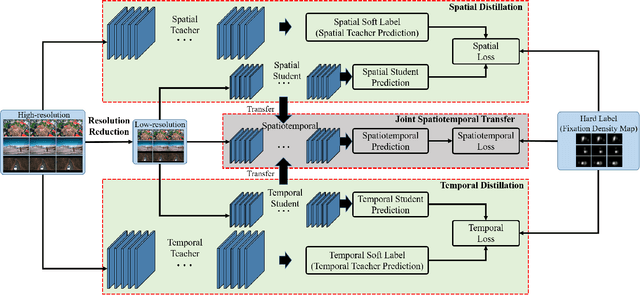
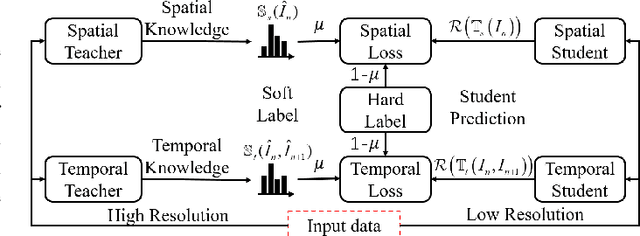
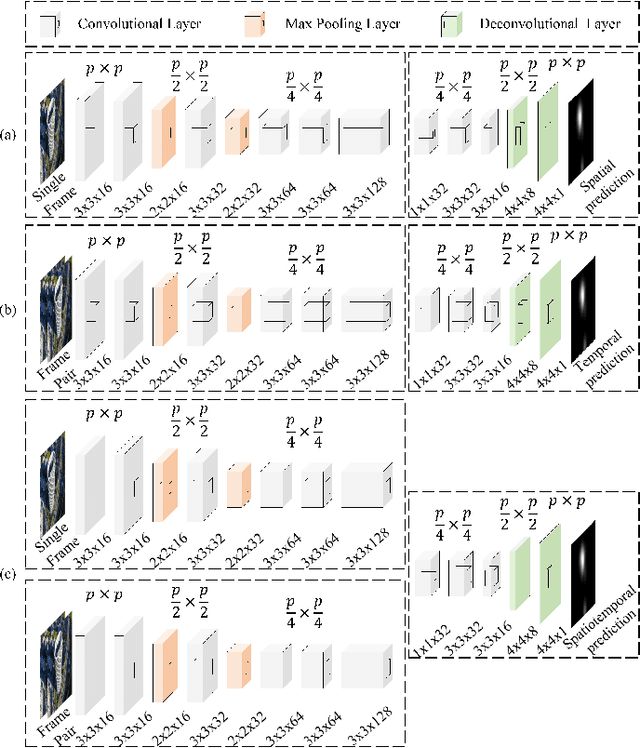
The performance of video saliency estimation techniques has achieved significant advances along with the rapid development of Convolutional Neural Networks (CNNs). However, devices like cameras and drones may have limited computational capability and storage space so that the direct deployment of complex deep saliency models becomes infeasible. To address this problem, this paper proposes a dynamic saliency estimation approach for aerial videos via spatiotemporal knowledge distillation. In this approach, five components are involved, including two teachers, two students and the desired spatiotemporal model. The knowledge of spatial and temporal saliency is first separately transferred from the two complex and redundant teachers to their simple and compact students, and the input scenes are also degraded from high-resolution to low-resolution to remove the probable data redundancy so as to greatly speed up the feature extraction process. After that, the desired spatiotemporal model is further trained by distilling and encoding the spatial and temporal saliency knowledge of two students into a unified network. In this manner, the inter-model redundancy can be further removed for the effective estimation of dynamic saliency on aerial videos. Experimental results show that the proposed approach outperforms ten state-of-the-art models in estimating visual saliency on aerial videos, while its speed reaches up to 28,738 FPS on the GPU platform.