 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Attention on the Sun: What Do Existing Models Actually Predict?
Paper and Code
Nov 25, 2018
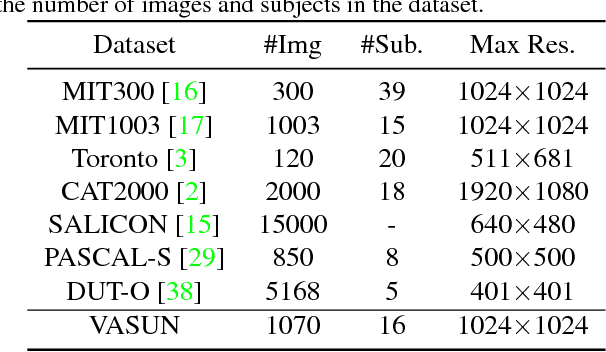
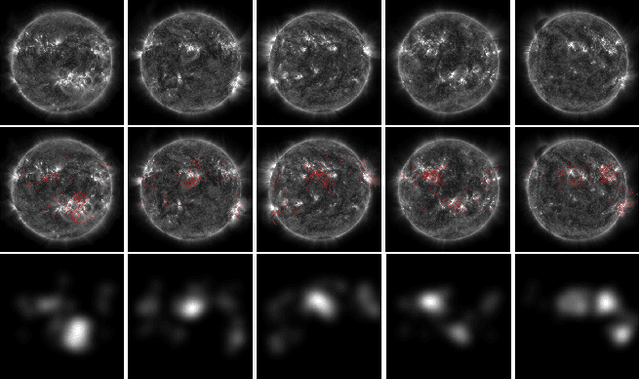
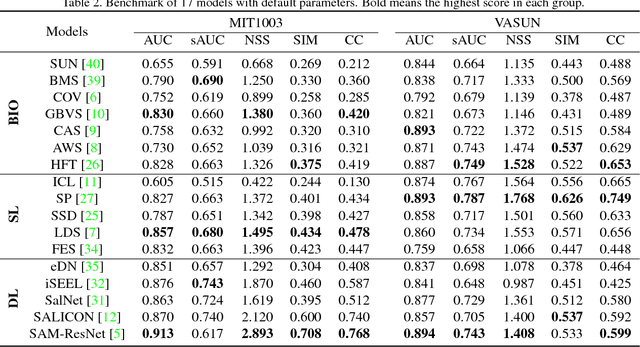
Visual attention prediction is a classic problem that seems to be well addressed in the deep learning era. One compelling concern, however, gradually arise along with the rapidly growing performance scores over existing visual attention datasets: do existing deep models really capture the inherent mechanism of human visual attention? To address this concern, this paper proposes a new dataset, named VASUN, that records the free-viewing human attention on solar images. Different from previous datasets, images in VASUN contain many irregular visual patterns that existing deep models have never seen. By benchmarking existing models on VASUN, we find the performances of many state-of-the-art deep models drop remarkably, while many classic shallow models perform impressively. From these results, we find that the significant performance advance of existing deep attention models may come from their capabilities of memorizing and predicting the occurrence of some specific visual patterns other than learning the inherent mechanism of human visual attention. In addition, we also train several baseline models on VASUN to demonstrate the feasibility and key issues of predicting visual attention on the sun. These baseline models, together with the proposed dataset, can be used to revisit the problem of visual attention prediction from a novel perspective that are complementary to existing ones.